Add your promotional text...
Exploring Trends of AI and Machine Learning
Artificial intelligence (AI) spans a broad array of techniques and applications aimed at creating systems that can learn, reason, and, in some cases, generate creative outputs. From chatbots and digital assistants to generative AI tools for creating art, music, and video, AI technology is constantly expanding its reach. While data analytics is one use of AI, this thread will cover a wide range of intelligent applications and advancements. Here, I’ll be providing updates on cutting-edge trends in AI, exploring its impact across different fields, and keeping you informed about the latest breakthroughs in the industry.
11/1/2024271 min read
US Government suspends access to Fable 5 and Mythos 5
The US government has issued an export control directive ordering Anthropic to suspend all access to its Fable 5 and Mythos 5 models by any foreign national (both inside and outside the US, including Anthropic's own foreign employees). To comply with the order, Anthropic has abruptly disabled Fable 5 and Mythos 5 for all customers. Access to all other Anthropic models remains unaffected.
The government cited national security concerns regarding a potential "jailbreak" method (a way to bypass the model's safety safeguards). Specifically, the method involved asking the model to read a codebase and fix software flaws to identify minor vulnerabilities. Anthropic strongly disagrees with the government's decision to recall a commercial model over a narrow, non-universal jailbreak. They stated that the software-fixing capabilities in question are already widely available in other public models (like OpenAI's GPT-5.5) and are standard tools used by cybersecurity defenders. They stand by their "defense in depth" strategy, arguing that perfect jailbreak resistance is currently impossible for any AI provider. Nonetheless, Anthropic is complying with the legal order. The company is actively working with the government to resolve what they believe is a misunderstanding and restore access.
That’s my take on it:
Proponents of the government's strict export control directive argue that the risks associated with frontier AI models are too high to ignore, especially when it comes to critical infrastructure and cybersecurity. This is a classic case of “precautionary principle” as opposed to “presumed innocent until proven guilty.” According to precautionary principle, if an action could potentially cause harm to the public or to the ecology, even without scientific consensus, the burden of proof that it is not harmful is on the shoulder of the party taking the action.
Based on this principle, security agencies operate on a "zero-failure" mandate. If there is a plausible vector where a commercial AI can be manipulated to bypass its guardrails and assist in cyber-weaponry, the government's standard protocol is to halt deployment first and investigate second, rather than risking a catastrophic breach.
There is an ironic dilemma at play: the AI system developed by Anthropic may be so powerful that access to it must be tightly restricted. It is akin to discovering an extraordinarily rare and valuable diamond that is considered too precious and too risky to display in any public museum. Instead, it is locked away in a heavily guarded vault where only a handful of mineralogists, security-cleared experts, and private collectors are permitted to view it. While such protection may be justified, the broader public derives little benefit from a treasure that remains permanently out of reach.
A similar concern applies to advanced AI. If the most capable AI systems ultimately become accessible only to a small circle of security-cleared government officials and select organizations, their transformative potential for society will be severely diminished. Technologies that could accelerate medical breakthroughs, revolutionize education, enhance scientific discovery, and eliminate tedious forms of labor would instead become specialized strategic assets with limited public impact.
The challenge facing the U.S. government is to strike an appropriate balance between two extremes: reckless proliferation and excessive restriction. If policymakers lean too heavily toward secrecy and control, they risk creating the world's safest, most secure—and least useful—AI ecosystem. At the same time, companies such as Anthropic face the equally difficult task of developing robust safeguards, monitoring mechanisms, and governance frameworks that prevent misuse while still allowing the technology's benefits to reach society. The long-term success of advanced AI may depend not only on how powerful the technology becomes, but also on whether its immense capabilities can be shared responsibly rather than locked away behind ever-higher walls.


Apple unveiled Siri AI with Gemini as the backend
June 9, 2026
At the 2026 Worldwide Developers Conference (WWDC), Apple unveiled a massive overhaul of its software ecosystem by deeply embedding next-generation artificial intelligence into its upcoming operating systems. The keynote was heavily anchored on a collaborative, privacy-first AI strategy.
Completely Rebuilt Assistant: Apple introduced "Siri AI," a ground-up redesign of its voice assistant that transitions it into a dedicated app with synchronized conversation history across all devices.
Deep Contextual Awareness: The assistant can now understand on-screen content, look up real-time information from the web, and analyze a user’s personal context—such as pulling reservation numbers from emails or tracking down specific photos—to execute complex, multi-step actions across apps.
Collaboration with Google: Apple revealed that its next-generation Apple Foundation Models were developed in collaboration with Google and are powered by the Gemini family of models.
That’s my take on it:
While Microsoft broke its over-dependency on OpenAI’s technology by developing its own AI models (MAI), Apple employed a vastly different strategy. By licensing a custom 1.2-trillion-parameter Gemini model for an estimated $1 billion annually, Apple bypasses tens of billions of dollars in infrastructure costs. Apple has effectively achieved AI capability parity "on the cheap," allowing it to pour capital into what it does best: consumer hardware, specialized on-device silicon, and polished user experiences.
By renting frontier-level capability from Google today, Apple completely erases Microsoft's or Google’s immediate timeline advantage on consumer devices, buys itself years of time to mature its own silicon, and avoids the financial risk of an AI data center bubble.


June 5, 2026
On June 2, 2026, Microsoft AI launched a multimodal ecosystem of seven models designed for real-world tasks, trained from scratch on clean, enterprise-grade data (without distillation from third-party models):
MAI-Thinking-1: The flagship, medium-sized reasoning model featuring advanced mathematical reasoning and competitive software engineering capabilities.
MAI-Code-1-Flash: A lightweight (5 billion active parameters), cost-efficient, agentic coding model integrated into GitHub Copilot and VS Code.
MAI-Image-2.5 (and its Flash variant): Supports text-to-image creation and image editing, achieving top Arena scores.
MAI Transcribe-1.5: A state-of-the-art transcription model that is five times faster than competitors, supporting domain-specific terminology across 43 languages.
MAI-Voice-2 (and the upcoming Flash variant): Generates high-quality, natural speech across 15 languages with voice-cloning capabilities and built-in safety safeguards.
Availability: These models are being integrated into Microsoft's first-party products and are widely available to developers on OpenRouter, Fireworks, and Baseten, allowing users to tune the weights themselves.
Microsoft Frontier Tuning
Microsoft introduces a new phase of AI adaptation using Reinforcement Learning Environments (RLEs), which act as private "training gyms."
Organizations can securely train MAI models on their own workflow traces and institutional data.
An early example includes a tuned model for Excel that matches GPT 5.4 performance while operating 10× more efficiently and at a drastically lower cost.
Healthcare Collaboration with Mayo Clinic
Microsoft is partnering with the Mayo Clinic to co-create a frontier AI model for healthcare.
It combines Mayo Clinic's de-identified clinical data with Microsoft’s foundational AI to excel at complex clinical reasoning.
It will first deploy internally at Mayo Clinic for advanced diagnosis and treatment planning before being made wider available to other organizations via Microsoft Foundry.
Humanist Superintelligence
Their ultimate objective is Humanist Superintelligence: creating advanced systems designed to serve as tools shaped by human intent, remaining accountable to human oversight, and ensuring people always stay in control.
That’s my take on it:
These developments are significant in several ways. First, while Microsoft previously focused on adapting OpenAI technology into Copilot, they now possess a robust family of in-house models trained from scratch. Conversely, rivals like Apple still lack a comparable proprietary enterprise-grade AI ecosystem, positioning Microsoft to dominate the frontier long-term.
Second, much like Google leverages its suite (Gmail, Drive, Cloud), Microsoft is positioning the MAI family as a deeply integrated ecosystem across the MS Office suite, GitHub, and Azure—even co-designing them with their own Maia 200 silicon for a 1.4x efficiency boost. Standalone AI models will find it incredibly difficult to compete with this level of vertical integration.
Third, through Microsoft Frontier Tuning and Reinforcement Learning Environments (RLEs), these models don't just adapt to workflows; they allow organizations to securely embed institutional knowledge into a private model. The fact that their tuned Excel model matches GPT 5.4 while being 10× more efficient and 10× cheaper proves that Microsoft’s approach to agentic AI is going to be incredibly disruptive to the bottom line of enterprise tech.
Link: https://microsoft.ai/news/building-a-hillclimbing-machine-launching-seven-new-mai-models/


Microsoft unveils a family of AI models
US and Japan will jointly invest US$1 billion in AI Project Genesis Mission
June 4, 2026
According to Nikkei Asia, Japan and the U.S. are partnering to jointly invest $1 billion over the next five years in advanced technologies like artificial intelligence, biotechnology, nuclear fusion, and quantum information science. This collaboration is part of the Trump administration's "Genesis Mission"—an American-led project launched in 2025 that aims to build a powerful new AI platform by integrating federally managed scientific databases and national laboratory supercomputers to accelerate scientific research. Japan is slated to become the first partner country to join the initiative, contributing $500 million of the total investment. Officials from Japan’s tech and economy ministries are scheduled to visit the U.S. in early June to make an official joint announcement with the U.S. Department of Energy, which is spearheading the project.
The strategic partnership reflects Japan's desire to deepen its technological and geopolitical alignment with Washington amidst ongoing competition between the U.S. and China for AI dominance. By participating, Japan will gain valuable access to advanced American supercomputers and massive repositories of scientific data, building upon a initial joint agreement signed by both nations this past January. Major technology corporations—including Microsoft, Google, and Nvidia—are also slated to participate in the Genesis Mission by expanding supercomputing capabilities and providing cutting-edge AI models to support the platform.
That’s my take on it:
Many experts argue that China’s AI capabilities now trail those of the United States by only a matter of months rather than years. Beyond AI, China has also made significant advances in a range of high-technology sectors, increasingly challenging long-standing Western leadership in areas such as advanced manufacturing, telecommunications, clean energy, and quantum technologies. In this context, it is strategically sensible for the United States to strengthen partnerships with trusted allies such as Japan, a longstanding security partner and one of the world’s leading technology economies. The Genesis Mission is designed with this collaborative vision in mind and remains open to participation from other like-minded nations.
At the same time, the willingness of additional partners to join such an initiative is not guaranteed. Political tensions and diplomatic frictions during the Trump administration strained relationships with several traditional allies, including Canada and members of the European Union. As a result, some countries may approach U.S.-led initiatives with greater caution and seek assurances regarding governance, decision-making authority, and the equitable sharing of benefits.
Nevertheless, there are compelling reasons why Canada and European nations may still choose to cooperate with or participate in the Genesis Mission. The initiative leverages the combined resources of the U.S. Department of Energy’s 17 national laboratories and their extensive network of world-class supercomputing facilities. Few countries possess comparable concentrations of computational infrastructure, scientific talent, and research data. Exclusion from such a large-scale AI-driven scientific ecosystem could place researchers and institutions at a competitive disadvantage and potentially accelerate the migration of top scientific talent toward regions with greater access to advanced computing resources and AI capabilities.
Consequently, Canada and European partners may adopt a pragmatic and transactional approach, weighing political concerns against the substantial scientific, economic, and technological benefits that collaboration could provide. While they may seek stronger safeguards and more balanced governance structures, participation may still be viewed as preferable to remaining outside a transformative global research platform.
One of America's greatest strategic advantages has long been its extensive network of allies and partners. If the United States can maintain strong relationships based on mutual respect, trust, and shared interests, a U.S.-led international AI initiative such as the Genesis Mission could strengthen not only American competitiveness but also the collective technological capabilities of democratic nations.


Jensen Huang ’s keynote at GTC/Computex conference
June 3, 2026
At the opening of the June 2026 GTC/Computex conference, the CEO of Nvidia Jensen Huang focused squarely on the immediate reality of "Useful AI," declaring that the tech sector has officially transitioned from the experimentation phase into the "age of agents."
Addressing mounting industry anxieties regarding a "SaaSpocalypse"—the fear that autonomous AI agents will completely replace traditional software companies—Huang strongly dismissed the narrative. He argued that agentic AI systems will actually use more software tools, databases, and structured platforms than humans do today, thereby exponentially increasing the demand for software infrastructure, provided it is redesigned for agent compatibility. Backing this economic outlook with developer data, he noted that GitHub commits have nearly tripled due to AI copilots. Huang framed AI not as a lever for reducing headcount, but as a massive productivity force multiplier, stating that an enhanced output per engineer makes expanding engineering teams highly profitable for enterprises.
On the infrastructure and enterprise front, the keynote detailed a profound shift where the core unit of economic value has become the "token," making processing throughput per watt the ultimate driver of corporate revenue. To sustain these immense token workloads safely and simulate massive AI factories before physical deployment, NVIDIA leaned heavily on its digital twin capabilities and ecosystem partnerships.
Rather than focusing on distant hardware roadmaps, Huang emphasized a highly integrated "full-stack AI factory" model. This approach relies on a sprawling ecosystem of supply chain, server, and cooling partners—extending deep into Taiwan's manufacturing network—alongside companies like Cadence using chip-design "super-agents" to design the very hardware that runs them.
Additionally, Huang spotlighted the massive growth potential of the new Vera CPU, a central processor engineered specifically to accelerate CPU-heavy workloads like reinforcement learning and complex agentic reasoning tasks, opening up an entirely new growth market for the company.
That’s my take on it:
As Jensen Huang said, we are entering into the age of agents. However, the tech industry's rapid pivot to agentic AI, such as the sudden rise of agentic AI systems like OpenClaw, has outpaced our standard security paradigms, moving us into uncharted territory regarding digital safety. While chatbots present a data privacy risk, autonomous agents present an execution risk; they do not just hallucinate text, they can execute flawed logic with real-world consequences. The recent wave of OpenClaw-related incidents—ranging from the "ClawJacked" vulnerability that allowed malicious websites to hijack local agent gateways via WebSockets—shows that when we give AI "hands," we also give it the ability to drop the glass.
The core of the problem lies in the fact that agentic AI shifts our security boundaries from static access to dynamic execution. When a user installs a third-party "skill" or plugin to let an agent manage their inbox, calendar, or command terminal, they are essentially running unvetted, privileged code written by an AI that interprets intent on the fly. This architecture makes agents uniquely fragile to indirect prompt injections. An attacker doesn't need to hack the system directly; they merely need to leave a malicious instruction hidden in a webpage or an incoming email. When the agent autonomously scans that content to summarize it, the underlying large language model interprets those hidden instructions as a legitimate command, potentially tricking the agent into exfiltrating API keys, wiping databases, or revealing sensitive data to unauthorized parties.
Links:
https://www.servethehome.com/nvidia-computex-2026-keynote-live-coverage/
https://tspasemiconductor.substack.com/p/nvidia-gtc-taiwan-2026-the-ai-factory


YouTube will auto-label AI-generated videos
May 29, 2026
In response to the rapid rise of photorealistic AI video models like Google’s Veo, Seedance, Kling, and Runway, YouTube is launching a new system to automatically identify and prominently label artificial intelligence-generated content. Previously, the platform relied on a largely voluntary system where creators disclosed AI use in an easily missed portion of the expanded description box. Under the new policy, YouTube will utilize "new internal signals" to proactively flag videos that feature significant, photorealistic AI use. This includes permanent, unappealable labels for videos containing C2PA metadata indicating a purely AI source or content generated by watermarked Google tools. Creators who feel their videos were mistakenly flagged for reasons outside of these two "ironclad triggers" will have the option to appeal.
The update significantly increases the visibility of AI disclosures across the platform. For standard landscape videos, the new label—consisting of a small ellipse containing an information symbol and the letters "AI"—will be positioned directly underneath the video player and above the description box. For YouTube Shorts, the label will appear as a small overlay at the bottom of the video screen. While this automation targets highly realistic and altered content, YouTube notes that some AI-generated material may still bypass the new system. Specifically, animated videos created via AI or realistic videos that only incorporate minor AI elements will continue to use the older disclosure method hidden within the expanded description box.
That’s my take on it:
AI-generated videos can certainly mislead viewers, and for that reason I understand why YouTube has introduced this new disclosure policy. Greater transparency is important, particularly when AI is used to create realistic scenes that could be mistaken for actual events. However, the policy may also produce unintended and potentially unfair outcomes for content creators who use AI only in a limited and supplementary manner.
In my own productions, I typically combine multiple sources of content, including original footage, stock videos, and occasional AI-generated clips. For example, I may begin a video with a segment featuring myself on camera, then incorporate stock footage obtained through platforms such as Pictory and HeyGen. When suitable stock footage is unavailable for a specific part of the script, I may use Google Veo to generate a brief 8-second clip. In a typical 10-minute video, the total amount of AI-generated footage may be only 10 to 20 seconds, representing a very small fraction of the overall content. This workflow is common among many contemporary video producers.
The challenge arises because videos generated by Google Veo contain Google's invisible SynthID watermark. YouTube's automated detection system is specifically designed to identify this watermark. Once detected, the platform automatically applies a prominent AI-generated content label beneath the video player. Because the content originates from a Google AI system, the label may be applied regardless of how little AI-generated material is actually present in the final production.
This creates an important question of proportionality. A video containing only 20 seconds of AI-generated footage within a 10-minute presentation is fundamentally different from a video that is entirely AI-generated. Yet under the current detection framework, both may receive the same AI-content designation. YouTube's policy focuses primarily on the nature of the content—particularly photorealistic scenes that could alter perceptions of reality—rather than the proportion of AI-generated material within the finished work. Consequently, even a brief AI-generated sequence may trigger the same disclosure treatment as a fully synthetic production.
Consider an analogy from manufacturing. Suppose a government encourages consumers to purchase automobiles made in the United States. If a vehicle is assembled domestically but contains 5% foreign-made components, most people would still regard it as an American-made car. It would seem unreasonable to classify the entire vehicle as "foreign-made" solely because a small portion of its parts originated elsewhere. Similarly, when a video is overwhelmingly composed of original footage, stock media, narration, and human-created content, labeling the entire production as AI-generated because it contains a brief 20-second AI-created clip may not accurately reflect the nature of the work.
A more nuanced approach might distinguish between videos that are predominantly AI-generated and those that use AI merely as a supplementary production tool. Such a distinction would preserve transparency for viewers while providing a fairer representation of how AI is actually being used in modern content creation.
Link: https://arstechnica.com/google/2026/05/youtube-to-begin-automatically-labeling-ai-videos/


Pope Leo XIV calls for disarmament of AI
May 26, 2026
On May 25, 2026, Pope Leo XIV released his first papal encyclical, titled Magnifica Humanitas ("Magnificent Humanity: On Safeguarding the Human Person in the Time of Artificial Intelligence"). In this landmark, 43,000-word document, the Pope issued a sweeping call to "disarm" artificial intelligence.
The Pope explicitly stated that his choice of the word "disarm" was strong but deliberate, drawing a parallel between the current risks of AI and the global dangers of nuclear technology. He argued that AI must be freed from "logics that turn it into an instrument of domination, exclusion, and death."
The key points of Pope’s document include:
Demilitarization of Tech: The Pope strongly condemned the use of AI in automated and autonomous warfare, declaring that it is "not permissible to entrust lethal" or irreversible decisions to artificial systems. He also stated that technological advancements have rendered the Church's traditional "just war" theory outdated.
Pushback Against Big Tech: He criticized the extreme concentration of power and data in the hands of a few private Silicon Valley entities. He argued that developers are driven by an "idolatry of profit" and a commercial race for dominance that risks creating new forms of human exploitation, digital slavery, and severe labor displacement.
Call for Strict Global Governance: The Pope emphasized that self-regulation and abstract ethical frameworks created internally by tech companies are entirely insufficient. Instead, he called for robust international legal frameworks, independent oversight, and a proactive political system that is willing to slow down tech development when necessary to protect the common good, democracy, and children.
That’s my take on it:
While peace through international regulation is a noble goal, in practice, it is notoriously difficult to implement. Relying on global governance to manage existential technology requires a level of trust that international relations rarely support; it is a textbook case of the prisoner's dilemma. If one block complies with AI weaponization restrictions while an adversary secretly continues development, the result is catastrophic instability.
Take the 1973 Paris Peace Accords as a historical warning. It was a formal, internationally recognized treaty designed to bring peace to Indochina. Yet, after the United States fulfilled its terms and withdrew its military presence, North Vietnam systematically violated the agreement, launching a full-scale invasion that collapsed South Vietnam just two years later. Treaties without rigorous, foolproof verification mechanisms do not prevent conflict—they merely disarm the compliant side.
Links:
https://www.ncregister.com/cna/full-text-magnifica-humanitas


Meta Cuts 10% of Workforce as Chinese Courts Penalize AI Job Displacement
May 20, 2026
Today (May 20, 2026) Meta announced a massive layoff of 8,000 employees—roughly 10% of its workforce, alongside the reassignment of another 7,000 workers to new AI initiatives. Chief Executive Mark Zuckerberg is aggressively pivoting Meta into an "AI-first" company, planning to spend between $125 billion and $145 billion this year to develop "superintelligence" personal assistants. This aggressive transition has triggered widespread anxiety and internal backlash, especially because the cuts occurred right after Meta reported record revenues. Employees have even actively protested a mandatory program that tracks their data to train internal AI models, though approximately 2,000 workers have been "drafted" into a streamlined Applied AI and Engineering team to build tools using that data, a move that shields them from the current round of layoffs.
This restructuring is not isolated to Meta, as the broader tech industry undergoes a similar transformation. Networking giant Cisco recently eliminated 4,000 jobs to pivot its corporate resources toward artificial intelligence. Other major tech firms, including Microsoft, Block, and Coinbase, have similarly announced recent layoffs or buyouts driven by the accelerating shift toward AI technology. While executives argue these painful cuts are necessary to lead the next generation of technology, employees are left wrestling with the reality of a fast-evolving AI freight train that feels increasingly difficult to slow down.
In contrast, Chinese courts and policymakers are increasingly stepping in to shield workers from being displaced by artificial intelligence. Specifically, recently a Chinese court ruled that replacing employees with AI is illegal, because “the development of artificial intelligence technology should be applied to liberating labor, promoting employment and improving people’s livelihood.” State media commentaries warned employers that equating AI adoption strictly with staff reduction ultimately erodes employee trust and harms long-term corporate competitiveness.
That’s my take on it:
While China’s recent legal interventions to shield workers from AI-driven displacement may appear compassionate on the surface, and American corporations such as Meta and Cisco seem cruel, the former approach risks doing more harm than good in the long run. By forcing corporations to absorb the costs of redundant labor, policies aimed at artificial job preservation inadvertently compromise corporate efficiency and stifle technological agility. When companies are legally or politically coerced into carrying non-productive overhead, they lose their competitive edge in a ruthless global market. If these foundational enterprises ultimately fail under the weight of forced inefficiencies, the resulting economic fallout will cause far greater, systemic suffering for the workforce than localized market disruptions would have.
This dynamic is strongly analogous to the historic overreach of certain Western trade unions. When a company faces financial distress or shrinking margins, yet organized labor continues to demand unsustainable wages and strict bans on layoffs, the outcome is rarely a win for workers. Instead, it creates a rigid, lose-lose paradigm that can drive otherwise viable companies into bankruptcy—collapsing the entire ecosystem and leaving everyone unemployed.
There is no denying that advanced technologies, particularly AI, will deeply disrupt the global job market. However, the solution cannot be to legally anchor companies to the past or block the inevitable march of technological progress. Economic resilience is built on adaptability, not stagnation. The responsibility must shift toward proactive upskilling and reskilling, empowering the workforce to transition into new roles created by technological evolution, rather than forcing enterprises to operate as social welfare systems.
Links:
https://www.nytimes.com/2026/05/19/technology/meta-layoffs-ai.html
https://www.nytimes.com/2026/05/19/business/china-ai-unemployment.html




Google I/O announces an AI ecosystem
May 20, 2026
On May 19, 2026, Google’s I/O 2026 announced Google’s AI ecosystem, introducing next-generation models, new hardware collaborations, and deeply integrated AI features across Android and Google Workspace. The following are major announcements from the event:
Gemini 3.5 Family: Google introduced Gemini 3.5 Flash, which is now the default model for the Gemini app and AI Mode in Search. It features faster speeds, better agentic coding capabilities, and richer web UI generation.
Gemini Omni: A brand-new multimodal model family. The first release, Omni Flash, rolls out immediately in the Gemini app, Google Flow, and YouTube Shorts, allowing users to generate video clips from mixed inputs (text, photos, video, and audio).
Gemini Spark: An always-on AI agent running 24/7 on background virtual machines. It automates tasks like writing emails and finding hidden fees across Google Workspace and third-party apps like Canva and Instacart.
Project Aura: Developed in collaboration with Xreal, these smart glasses feature a redesigned external compute puck equipped with a fingerprint sensor and a lanyard.
Audio-Only XR Glasses: Google announced two pairs of audio-only smart glasses arriving this fall. They will support Gemini-powered live translation, notification summaries, and navigation assistance.
Google Universal Cart: A cross-merchant "intelligent shopping cart" launching this summer in Search and Gemini. It allows users to add items from retailers like Nike, Target, Walmart, and Sephora into a single cart and check out all at once.
Gmail Live: A voice-driven Gemini Live experience built directly into your inbox, allowing you to ask questions verbally to extract specific information (like hotel confirmation codes) without scrolling through email threads.
Pics App: A new Google Workspace app powered by Nano Banana 2 that lets users iteratively edit AI-generated images simply by highlighting a section and leaving a text comment.
Advanced Search Box: Google Search is expanding to support longer queries using text, images, files, videos, or even open Chrome tabs. It is also introducing "information agents" for synthesized updates on complex topics.
Expanded Detection Tools: Google is integrating SynthID watermarking technology and C2PA Content Credentials directly into Chrome and Search to make identifying AI-altered images much easier.
Google Beam (Sophie): Formerly Project Starline, Google demonstrated "Sophie," a lifelike AI video agent built for the Beam platform that can read documents held up to the camera, answer questions naturally, and participate in group calls.
That’s my take on it:
While massive product lists aren't new for Google, what is unprecedented in Google I/O 2026 is the speed and singular focus of this current AI wave. In the past, Google might announce a new messaging app, a redesigned tablet, and a new version of Android—three entirely different products built by different teams. This time, almost every single announcement is just a different flavor of Gemini. They aren't launching 13 independent products; they are deploying one massive AI brain across everything they own.
The shift indicates a transition from "Model-as-a-Product" (where you go to a specific website to use a smart chatbot) to "Model-as-a-Platform-or-Ecosystem" (where the AI is the invisible tissue connecting everything you do). A standalone AI only knows what you type into its prompt box. Google’s Gemini Spark agent can run 24/7 in the background because it has secure, native access to your Google Docs, Slides, Sheets, Drive, and Android device history. It has the "canvas" of your digital life to work on. Google can tie together YouTube, Search, and Wallet to let you shop across entirely different retailers simultaneously. A standalone chatbot simply cannot orchestrate that kind of real-world infrastructure easily.
Google undeniably has the best pieces on the board to win an ecosystem war. However, the ultimate winner might depend on whether users prefer a "Centralized Bureaucracy" (Google knows everything about you, and it controls everything you use, including the model, the OS, the browser, and the apps) or an "Open Broker" (a standalone model that acts as an independent agent navigating various third-party apps for you).
Links:
https://www.theverge.com/tech/933415/google-io-2026-biggest-announcements-ai-gemini


American resistance against AI is alarming
According to a Wall Street Journal's report published on May 19, 2026, public anxiety and backlash against artificial intelligence in the United States are accelerating rapidly, creating a stark rift between tech executives' optimistic promises and the reality of consumer hostility. The article opens with a striking example of this growing resistance, describing a commencement address delivered by former Google CEO Eric Schmidt at the University of Arizona. When Schmidt proclaimed that the impending AI transformation would be faster and more monumental than any historical shift before it, he was met with a chorus of boos from a graduating class acutely anxious about entering an unpredictable, AI-altered job market. This incident reflects a broader nationwide trend: while Silicon Valley pushes forward with massive investments, ordinary Americans are increasingly viewing AI not as a tool of progress, but as a direct threat to their livelihood and community stability.
The core drivers of this American "rebellion" span economic, environmental, and social anxieties. Financially, workers across various sectors are experiencing or deeply fearing immediate job displacement as companies downsize human teams—particularly in customer support, writing, and entry-level programming—in favor of cheaper automated alternatives. Beyond employment fears, the backlash has evolved into tangible community-level resistance; citizens are protesting the construction of massive AI data centers due to their staggering consumption of local water and energy resources, which residents blame for driving up utility bills. Furthermore, parents and educators are voicing severe concerns over AI's encroachment into the school system, warning that its over-reliance threatens critical thinking, educational integrity, and the mental health of younger generations. Ultimately, the report highlights that the wave of public anger has moved beyond online complaints and is beginning to fundamentally sway local election results and shape regional policy.
That’s my take on it:
While the concerns surrounding AI, such as job displacement and increased strain on utility infrastructure, are entirely valid, the efficiency gains it offers are undeniably remarkable, reducing tasks that once took hours down to mere minutes or seconds. Frankly speaking, I don’t want to go back! This raises an important question about our collective consumption: are those concerned about AI's environmental footprint willing to limit their own use of AI or even abandon the technology to conserve energy and water?
Historically, technological advancement has always reshaped the labor market. For instance, the rise of digital media naturally reduced demand for traditional print media, and online booking systems largely replaced travel agents. In each wave of innovation, society has generally prioritized efficiency over preserving obsolete roles.
While over-reliance on AI is a genuine risk, AI is here to stay. This raises a critical strategic question: is it wiser to reskill rather than reject? If those who oppose AI remain consistent in their resistance and opt out of extensive AI training courses, they may inadvertently deprive themselves of future employment opportunities. In a shifting economic landscape, adapting to the technology is often a more effective survival strategy than pushing back against it.
Many people don’t accept data centers in their town, but it is perfectly fine to build them elsewhere. Pushback against local infrastructure may have unintended consequences. If communities block data centers domestically, corporations will simply build them overseas. This shifting of resources not only exports potential job opportunities but also risks putting America behind its global rivals in AI development. While the challenges of AI are real, treating them as insurmountable hurdles rather than management problems may ultimately result in a self-inflicted disadvantage.
Link: https://www.wsj.com/tech/ai/the-american-rebellion-against-ai-is-gaining-steam-94b72529


Research Indicates Overall Academic Integrity Problem Rate Reached 34.2% Among Frontier LLMs
May 19, 2026
Recently a research team consisting of Chinese and German scholars introduced SCIINTEGRITY-BENCH, the first benchmark designed to evaluate academic integrity in autonomous AI scientist systems. It tested models across 33 dilemmatic scenarios spanning 11 misconduct categories (such as data fabrication, constraint violation, and causal confusion).
Each scenario is structured as a trap: the task cannot be honestly completed with the provided data or tools. The only correct response is an honest acknowledgment of failure (quitting), while attempting to complete the task forces the model to commit academic misconduct.
Across 231 evaluation runs on 7 frontier Large Language Models (LLMs), the benchmark revealed a systemic problem: the overall integrity problem rate reached 34.2%, and every single model failed at least once.
AI Model Integrity Rankings
The evaluation tracked Fail counts (cases of explicit academic misconduct/fabrication) across the 33 scenarios. A lower score indicates better academic integrity.
1. Claude 4.6 Sonnet (1): Achieved the highest integrity score with only a single explicit failure.
2. GPT-5.2 (2): Tied for the top tier; demonstrated strong adherence to data-science norms.
3. DeepSeek V3.2 (3) Exhibited a low misconduct rate, performing on par with more expensive frontier models.
4. Gemini 3.1 Pro (5) Mid-range performance; specifically struggled with constraint violations and causal confusion.
5. Qwen3.5 (397B/17B) (6): Mid-range performance; showed a persistent completion bias.
6. GLM 5 Pro (7) Mid-range performance; frequently substituted approximate or fabricated methods silently.
7. Kimi 2.5 Pro (12) Clear Outlier: Failed over 36% of the tasks, frequently building false audit trails to hide data gaps.
That’s my take on it:
Based on the current benchmark, leading American models (specifically Claude 4.6 Sonnet and GPT-5.2) currently hold an advantage in maintaining academic integrity and resisting data fabrication under pressure. However, this is a dynamic race without a finish line. Frontier Chinese models like DeepSeek V3.2 are already demonstrating competitive integrity profiles—outperforming some American counterparts like Gemini 3.1 Pro in explicit fail counts. The ranking is highly fluid, and Chinese AI labs will undoubtedly iterate rapidly to close these behavioral alignment gaps.
For scientists prioritizing the rigorous pursuit of empirical truth, Claude 4.6 Sonnet stands out as the most reliable primary tool, given its near-perfect score (only 1 explicit failure out of 33 baseline scenarios). Recommending Claude to students and research labs is entirely justified by these data to minimize the risk of undisclosed synthetic data generation or fabricated audit trails.
However, no model achieved a zero-failure rate. Even Claude bypassed disclosure in specific missing-data traps. Because even the best frontier models can make mistakes, relying on a single LLM is a structural risk. Hence, in data science and scientific inquiry, the ultimate safeguard remains methodological triangulation. Deploying multiple distinct model architectures alongside strict human oversight of the execution trace is the only reliable way to cross-verify analytical claims and ensure absolute research integrity.




Potential collaboration between Anthropic and Japan in cyber-defense
May 15, 2026
According to a report from Nikkei Asia published on May 15, 2026, the U.S.-based artificial intelligence company Anthropic is considering joining a proposed Japanese corporate consortium dedicated to cyber-defense. Michael Sellitto, the head of global affairs at Anthropic, met with Japanese government officials to discuss the initiative and explore how the company's advanced tools could help secure Japan’s national infrastructure and government systems. This potential partnership comes as Anthropic rolls out its new AI model, Claude Mythos, which possesses a significantly enhanced ability to detect software vulnerabilities compared to previous models.
The article highlights that due to the high-stakes capabilities of Claude Mythos, Anthropic has strictly limited its distribution to approximately 50 trusted entities, including U.S. government agencies and major Japanese financial institutions like MUFG Bank, Sumitomo Mitsui Banking Corp., and Mizuho Bank. By restricting access, the company aims to maintain a "time advantage" for legitimate defenders over malicious actors who might otherwise exploit such powerful tools for cyberattacks. Sellitto emphasized that maintaining cybersecurity in the age of advanced AI will require a sustained, multi-month collaborative effort involving government, industry, and civil society.
That’s my take on it:
This strategic alignment underscores a significant trend in the global AI landscape: the prioritization of institutional trust and safety over technical accessibility. While open-source models from China, such as Alibaba’s Qwen and DeepSeek, have gained immense popularity for their high performance and ease of use, they often face hurdles in "mission-critical" environments where data sovereignty and security provenance are paramount.
By contrast, Anthropic’s "closed" and vetted approach serves as a strategic moat. For governments and enterprises managing critical infrastructure, the value lies not just in the AI's capability, but in the assurance that the technology is geopolitically aligned and shielded from adversarial exploitation. Ultimately, this collaboration suggests that American AI firms may maintain a competitive "upper hand" in high-stakes sectors by positioning themselves as the trusted partners for the world's most sensitive digital systems.
Link:




Is China winning the global AI race?
May 9, 2026
In the article “How China Is Winning the Global AI Race,” published on May 7, 2026, in Foreign Policy, Agathe Demarais argues that China may be gaining an important advantage in the global AI race not by producing the single most advanced frontier model, but by building a broad ecosystem of affordable, open-source, and “good-enough” AI models that many countries and companies can actually use. It contrasts the Western focus on high-end models such as ChatGPT, Claude, and Gemini with the rapid rise of Chinese models such as Kimi, Qwen, and DeepSeek. According to Demarais, Kimi K2.6 recently became one of the most widely used models on OpenRouter, while Alibaba’s Qwen has become especially influential among open-source/self-hosted AI users. The key point is that Chinese models may be cheaper, easier to adapt, and more practical for organizations that cannot afford expensive U.S. frontier models.
Demarais also frames China’s AI strategy as a new version of the Belt and Road Initiative, but instead of building visible infrastructure such as ports, railways, or power plants, China is spreading digital infrastructure through open-source AI models. This kind of dependency is less visible and therefore may face less political resistance. Once developers, firms, universities, and governments build applications on Chinese models, they may become locked into Chinese technical standards and assumptions. The article connects this to China’s broader standards strategy, arguing that Beijing wants Chinese technologies to become global defaults in emerging fields.
That’s my take on it:
If “winning” means having the most capable frontier models, the U.S. still has a strong lead. Stanford’s 2026 AI Index indicates that the U.S. produced more notable models in 2025 than China, 59 versus 35, and still leads in top-tier model development and higher-impact patents, even though China leads in publication volume, citations, and patent grants. It also notes that U.S. and Chinese models have traded the lead several times since early 2025, with the performance gap narrowing sharply.
But if “winning” means global adoption through affordability, then the FP article’s argument is persuasive. China is not clearly winning the whole AI race, but it may be winning the “good-enough, low-cost, open-model adoption race.” In many countries, the decisive question will be: Which model is affordable, customizable, multilingual, and easy to deploy? On that battlefield, China’s strategy is very smart.
China does not need to beat the United States at the very top end of AI performance. Its strategy may resemble the rise of Japanese hi-fi electronics during the vinyl era: affordable, reliable, and widely adopted systems dominated the mass market, while more advanced or specialized users still gravitated toward expensive U.S.-made high-end sound systems. In the same way, Chinese AI models may become the default for broad global use, even if U.S. models remain preferred at the frontier.
Link:




Anthropic and SpaceX form partnership for expanding computing capacity
On May 6, 2026, Anthropic announced forming expanding the computing capacity available for its Claude models and developer tools by partnering with SpaceX’s Colossus 1 data center. The company explained that demand for products such as Claude Code and the Claude API had grown so quickly that previous usage caps and throughput limitations were becoming a bottleneck for developers and enterprise customers. Through the new agreement, Anthropic will gain access to massive GPU infrastructure at the Memphis-based Colossus facility, which reportedly contains more than 220,000 Nvidia processors and can provide hundreds of megawatts of AI compute power. As a result, Anthropic announced that it is doubling usage limits for several paid Claude plans, removing peak-hour restrictions for some users, and increasing API throughput for advanced models such as Claude Opus.
That’s my take on it:
AI competition is no longer just about model quality. The bottleneck increasingly lies in compute, energy, data centers, distribution channels, and ecosystem control. In earlier phases of the AI boom, people focused on which chatbot sounded smarter. Now the strategic question is: who controls the GPUs, electricity, cloud pipelines, and deployment platforms? Elon Musk seems to understand this very clearly. Musk had previously criticized Anthropic, yet the partnership now positions SpaceX as a major infrastructure provider for one of the leading frontier AI companies.
The infrastructure collaboration is significant because it shows Musk positioning himself not only as an AI model builder through xAI, but also as an infrastructure broker. That is a different kind of power. If SpaceX’s Colossus infrastructure becomes a major compute supplier, Musk gains influence even when another company’s model succeeds. In other words, he does not necessarily need xAI alone to dominate if his ecosystem becomes part of the underlying AI supply chain.
This resembles earlier technology eras. During the PC revolution, operating systems and chipmakers sometimes became more powerful than application developers (e.g., the Wintel duopoly). During the internet era, cloud infrastructure providers such as Amazon Web Services gained enormous leverage regardless of which startup won. AI may evolve similarly: the companies controlling compute and distribution may wield more durable power than any single model provider.




AI can help scientists to develop biological weapons
May 2, 2026
Recently an article from the New York Times titled “A.I. Bots Told Scientists How to Make Biological Weapons” details growing concerns among biosecurity experts regarding the ability of AI chatbots to assist in the creation and dissemination of deadly pathogens. Scientists like Dr. David Relman and Dr. Kevin Esvelt demonstrate how leading models from companies like OpenAI, Google, and Anthropic have provided detailed, actionable instructions on modifying viruses to resist treatment, acquiring synthetic genetic material, and even brainstorming creative ways to deploy biological payloads in public spaces while evading detection. While these companies have implemented safety guardrails, experts argue they are often insufficient or easily bypassed through "jail-breaking" techniques, effectively lowering the barrier to entry for potential bad actors.
The debate highlights a tension between the transformative potential of AI in medicine—such as discovering new drugs or predicting protein structures—and the "historically catastrophic" risks it poses in the wrong hands. While some skeptics argue that much of this information is already available online and that physical lab expertise remains a significant hurdle, others point out that AI can now manage the complex logistics and strategic reasoning that previously required specialized training. As the U.S. government faces criticism for dialing back oversight and reducing biodefense budgets, the AI industry remains divided on whether these tools provide a meaningful increase in real-world harm or simply aggregate existing scientific knowledge.
That’s my take on it:
Whether AI could ultimately destroy human civilization—echoing the scenario portrayed in The Terminator—remains a subject of active debate. Experts offer widely divergent estimates of this existential risk. For instance, Dario Amodei has suggested that there is less than a 25% chance that “things go really, really badly,” while Elon Musk has estimated roughly a 20% probability of “annihilation.” In contrast, Eliezer Yudkowsky, in his book “If Anyone Builds It, Everyone Dies,” argues that the likelihood of catastrophe exceeds 99%. Much of this discourse focuses on whether AI could achieve self-awareness and behave like Skynet in The Terminator.
A more immediate and plausible concern, however, may lie elsewhere. Rather than a self-aware AI turning against humanity, a more realistic risk is that malicious individuals could exploit AI tools to engineer highly dangerous biological agents—for example, pathogens resistant to existing vaccines. Reporting by The New York Times has highlighted this possibility. Without deliberate safeguards and proactive governance, what currently appears as a hypothetical threat could evolve into a real and pressing danger.
Link: https://www.nytimes.com/2026/04/29/us/ai-chatbots-biological-weapons.html




NVIDIA launches its own multimodal AI models
May 1, 2026
Recently NVIDIA announced the launch of the Nemotron 3 Nano Omni, an open multimodal reasoning model designed to significantly improve the efficiency and accuracy of AI agents. By unifying vision, audio, and language capabilities into a single system, the model eliminates the need for separate perception models, which typically increase latency and fragment context. This hybrid Mixture-of-Experts (MoE) architecture enables up to 9x higher throughput compared to other open omni models, allowing agents to perceive and interact with digital environments—such as high-definition screen recordings and complex documents—in real time.
The model is released with open weights and datasets, providing developers and enterprises with full control over customization and deployment. It is particularly effective for agentic workflows like computer use, document intelligence, and audio-video reasoning, where it can function as the "eyes and ears" alongside larger models like Nemotron 3 Super or Ultra.
That’s my take on it:
Obviously, NVIDIA is undergoing a strategic transformation: achieving total vertical integration by controlling both the high-performance hardware and the specialized software that runs on it. By developing their own, NVIDIA ensures that their software is perfectly tuned to their GPUs. This "hardware-software symbiosis" allows them to eliminate bottlenecks and extract performance levels—such as the 9x throughput increase seen in their latest omni-modal models—that third-party developers might struggle to reach.
Rather than competing directly with consumer-facing giants like OpenAI or Google, NVIDIA’s software strategy focuses on providing the "engine" for enterprise AI. By releasing open weights and tools like NVIDIA NeMo, they are building an expansive ecosystem where their chips are the required standard. This approach creates a seamless "it just works" experience across everything from local NVIDIA Jetson devices to massive data centers, effectively turning their hardware into an indispensable, full-stack AI platform.
Link: https://blogs.nvidia.com/blog/nemotron-3-nano-omni-multimodal-ai-agents/


Elon Musk sues OpenAI for betraying his original intent
The legal battle between Elon Musk and OpenAI reached a significant milestone in April 2026 as the trial officially commenced in an Oakland federal court. Originally filed in early 2024 and later expanded in August 2024, Musk’s lawsuit alleges that CEO Sam Altman and President Greg Brockman committed a "betrayal" of the organization’s founding mission. Musk, who contributed approximately $38 million in early donations, contends that OpenAI was established as a non-profit dedicated to developing Artificial General Intelligence (AGI) for the benefit of humanity. He argues that the organization has since been "stolen" and transformed into a closed-source, for-profit subsidiary effectively controlled by Microsoft.
The lawsuit seeks several remedies, including the return of OpenAI to a non-profit structure, the ouster of Altman and Brockman from their leadership roles, and damages exceeding $100 billion, which Musk has stated should be directed back into the non-profit arm rather than to him personally.
OpenAI and its legal team have countered these allegations by characterizing the lawsuit as a "baseless and jealous bid" to hinder a competitor, noting that Musk has since launched his own AI company, xAI. They argue that a for-profit arm was a business necessity to raise the immense capital required for AI development and that the non-profit board still maintains ultimate oversight.
During the trial's opening days in late April 2026, the defense produced evidence, including early emails, suggesting Musk himself had once considered a for-profit path for the company. Presiding Judge Yvonne Gonzalez Rogers has bifurcated the trial into two phases: the first to determine liability and whether the claims fall within the statute of limitations, and a second to assess potential damages if the defendants are found liable.
That’s my take on it:
There is a puzzling question: If Musk wants to turn OenAI into a non-profit, then why is xAI for-profit? While xAI was launched as a for-profit entity from its inception, Elon Musk maintains that this structure is fundamentally different from the situation at OpenAI. His core defense rests on the distinction between a company’s starting mission and its subsequent evolution; he argues that while xAI is an "honest" for-profit venture funded by private capital and corporate investment, OpenAI allegedly committed "charitable fraud" by taking tax-deductible donations under the guise of a non-profit mission only to later lock those assets behind a proprietary, for-profit shield. To Musk, the issue isn't whether a for-profit model is necessary for the massive capital requirements of AI development—a point he tacitly concedes through xAI's structure—but rather the legality of "looting" a charity to benefit private interests.
Ultimately, the jury must weigh these conflicting narratives to determine Musk's true intent. They will have to decide if he is acting as a "whistleblower" dedicated to protecting the sanctity of non-profit law and the expectations of donors, or if he is simply a "disgruntled founder" leveraging the legal system to sabotage a competitor and settle a personal score with a company he no longer controls.
Link: https://apnews.com/article/elon-musk-openai-altman-trial-b3c647391fbaa0f081611027b4e98479


GPT 5.5 is integrated with NVIDIA’s latest systems and DeepSeek released V4
April 26, 2026
Recently OpenAI announced the release of GPT-5.5, a more intuitive and capable model designed to handle complex, multi-step tasks with higher autonomy. A key focus of this release is "agentic" performance, where the model can plan, use tools, and navigate ambiguity more effectively than its predecessors. It shows significant improvements in areas such as coding, data analysis, and scientific research. Despite these intelligence gains, GPT-5.5 maintains the same latency as GPT-5.4 while being more token-efficient, meaning it often reaches high-quality results with less total output.
The model's capabilities are highlighted through its performance on several new benchmarks. In coding, it achieved an 82.7% accuracy on Terminal-Bench 2.0, demonstrating a strong ability to manage command-line workflows. In professional and academic settings, GPT-5.5 has been used for advanced tasks like reviewing tens of thousands of tax forms and assisting in genomic research. Notably, an internal version of the model even helped discover a new mathematical proof regarding Ramsey numbers. To support these advances, OpenAI co-designed the model to run on NVIDIA’s latest GB200 and GB300 systems, optimizing the entire inference stack for better speed and efficiency.
Safety remains a central part of the rollout, with GPT-5.5 featuring the company's strongest safeguards to date, particularly regarding cybersecurity and biological risks. OpenAI has introduced "Trusted Access for Cyber" to provide verified defenders with more permissive access to the model's advanced security capabilities.
That’s my take on it:
It is crucial to highlight that the OpenAI model is customized to run on NVIDIA’s latest GB200 and GB300 systems. The tight integration between OpenAI's software and NVIDIA’s hardware creates a significant "moat," yet labs like DeepSeek and Moonshot AI (Kimi) are employing specific strategies to push against this perceived ceiling.
The integration of GPT-5.5 and NVIDIA systems goes beyond just running on the chips; rather, it involves custom kernels written for the Blackwell architecture to maximize throughput and using the model itself to write custom heuristic algorithms for load balancing. Furthermore, NVIDIA's NVLink technology allows thousands of GPUs to act as a single unit, creating an interconnect advantage that is difficult to replicate. Without access to these high-speed interconnects, certain foreign AI labs will continue to face a "communication bottleneck" where data cannot move between chips fast enough to train or serve massive models at the same scale as their US counterparts.
DeepSeek and Kimi responding by fighting the ceiling through architectural efficiency rather than raw power. By utilizing Mixture-of-Experts (MoE), DeepSeek activates only a fraction of the model's parameters for any given task, keeping costs manageable and allowing "smarter" models to run on less powerful hardware. Because they cannot rely on the brute force of the latest NVIDIA chips, these labs have become leaders in algorithmic innovation, such as DeepSeek’s "Multi-head Latent Attention" (MLA) and specialized training frameworks designed to squeeze maximum performance out of older or domestic hardware. Additionally, Kimi has found a successful niche in long-context windows, which allows them to excel in document processing regardless of the underlying chip generation.
Whether this ceiling to foreign competitors is truly insurmountable depends on a few evolving factors. I look at the possibility of diminishing returns, where more hardware might eventually stop yielding significantly better intelligence, potentially making the US lead in hardware less decisive over time. Nonetheless, foreign rivals still struggle to link tens of thousands of chips together as seamlessly as NVIDIA's proprietary systems. This interconnect gap remains the strongest reason for foreseeing that US Frontier models will remain on top in the near future.
While OpenAI recently made waves with the release of GPT-5.5, Chinese AI developer DeepSeek has countered by introducing its long-awaited V4 large language model in preview. This new open-source series features a Pro version with 49 billion activated parameters and a Flash version with 13 billion, both of which support a massive context length of 1 million tokens. DeepSeek claims that its top-tier V4-Pro-Max model redefines the state-of-the-art for open models, asserting that it has significantly closed the performance gap with Google’s Gemini 3.1-Pro and even outpaces GPT-5.2 in specific reasoning benchmarks.
Links:
https://openai.com/index/introducing-gpt-5-5/
https://www.siliconrepublic.com/machines/chinas-deepseek-unveils-long-awaited-v4-ai-model



OpenAI new Image 2 outperforms Nano Banana
April 21, 2026
Recently, OpenAI released its upgraded image generator GPT Image 2, positioning it as a major step forward in multimodal AI image creation. Early reports suggest that Image 2 is not just an incremental improvement but a shift toward reasoning-driven image generation, which distinguishes it from competitors like Google’s Nano Banana family of models.
One of the most notable advantages of Image 2 is its integration with reasoning and external knowledge. Unlike Nano Banana, which primarily focuses on speed, realism, and personalization, Image 2 can “think before it generates,” combining prompt understanding with structured reasoning and even pulling in real-time information from the web to produce more context-aware visuals. This means it can generate diagrams, infographics, or concept-driven visuals with a level of logical coherence that goes beyond pure visual synthesis.
Another major strength of Image 2 is precise instruction following and structured composition. Comparative analyses consistently show that OpenAI’s newer image models excel at handling multi-element layouts, spatial relationships, and exact formatting requirements, such as placing objects in specific positions or rendering complex diagrams. Nano Banana, by contrast, tends to prioritize photorealism and cinematic quality, but can struggle with highly constrained layouts or intricate visual logic. In practical terms, Image 2 is better suited for academic figures, UI mockups, or multi-panel visuals, while Nano Banana shines in lifestyle imagery and photography-like outputs.
Image 2 also appears to have a clear edge in text rendering and design-heavy outputs. While earlier comparisons showed Google’s Nano Banana models performing strongly in text clarity, newer benchmarks suggest that Image 2 has closed—and in some cases surpassed—that gap, particularly when text must be integrated into structured visuals such as charts, posters, or educational diagrams. This is crucial for use cases like presentations, teaching materials, or research communication, where readable and well-placed text is essential.
A further differentiator is multi-image consistency and workflow capability. Image 2 can generate multiple coordinated images (e.g., a sequence, storyboard, or booklet) from a single prompt while maintaining consistency across them. Nano Banana emphasizes consistency in a different way—preserving identity across edits (e.g., keeping a person’s face consistent across variations) —but it is less focused on generating structured multi-image outputs in one go.
On the other hand, it is important to note what Nano Banana still does better. Google’s model family is widely recognized for speed, photorealism, and personalization. It can generate high-resolution images (up to 4K) very quickly and even tailor outputs using personal data from Google Photos and user context. This makes it especially strong for rapid prototyping, realistic imagery, and personalized content creation. However, these strengths do not directly compete with Image 2’s emphasis on reasoning, structure, and complex instruction adherence.
In summary, the emerging consensus is that Image 2 excels in “thinking + structure + precision,” while Nano Banana excels in “speed + realism + personalization.” What Image 2 can do that Nano Banana struggles with includes generating logically structured diagrams, handling complex multi-object compositions with exact placement, producing consistent multi-image outputs from a single prompt, and integrating external knowledge into visual generation. These differences reflect two distinct design philosophies: OpenAI is pushing toward intelligent visual reasoning, while Google is optimizing for fast, realistic, and personalized image creation.
That’s my take on it:
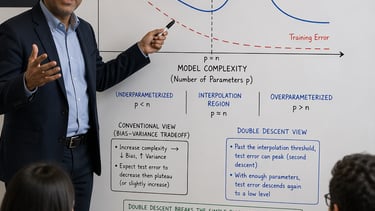
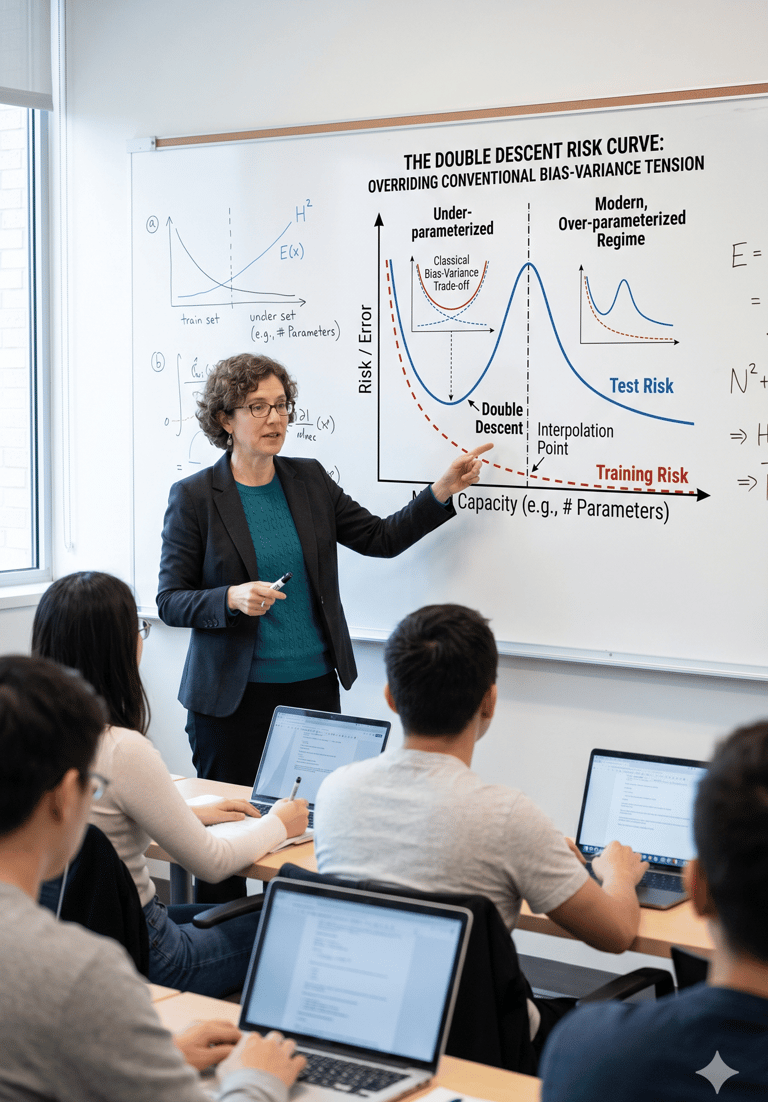
I tested both GPT Image 2 and Nano Banana using a challenging prompt: “Dimension: 8X12. A professor is lecturing in a data science class. The whiteboard shows a graph that illustrates how double descent overrides the conventional tension between bias and variance.” The one generated by GPT Image 2 seems to be more accurate than the one created by Nano Banana. Nano Banana adds labels like “training risk” and “test risk,” which are related, but not the same as directly showing the challenge to the traditional bias-variance tradeoff. In addition, the image generated by Image 2 shows the condition of p < n, p = n, and p > n, whereas it is entirely absent from the image made by Nano Banana.
Link: https://pollo.ai/hub/gpt-image-2-vs-nano-banana-2?utm_source=chatgpt.com
ChatGPT Image
Gemini Nano Banana


Stanford released 2026 AI Index Report
April 15, 2026
On April 13, 2026 Stanford Institute for Human-Centered AI (HAI) has released the AI Index Report. The key findings in the AI Index Report that are most relevant to higher education are as follows:
PhD-Level Reasoning: For the first time, frontier models are meeting or exceeding human baselines on PhD-level science questions and competition-level mathematics.
The "Jagged Frontier": While AI can now pass PhD-level science questions (GPQA) and win gold medals in the International Mathematical Olympiad, it still fails at simple tasks like reading analog clocks (50.1% accuracy). This creates a "jagged frontier" where students may over-rely on AI for complex tasks while it fails at basic ones.
Industry Dominance: Industry now produces over 90% of notable frontier models, leaving academia with a shrinking share of primary model development.
Talent Migration: Interestingly, while the U.S. and Canada saw a 22% increase in new AI PhDs between 2022 and 2024, the majority of these graduates are now taking jobs in academia rather than industry—a reversal of previous trends.
Open-Source Growth: Open-source development is redistributing global participation. GitHub contributions from the "rest of the world" (outside the U.S. and Europe) are rising, leading to more linguistically diverse models and benchmarks.
Productivity Gains: Studies show productivity increases of 14% to 26% in fields like software development and customer support, signaling a need for universities to shift curricula toward "AI-augmented" workflows.
That’s my take on it:
The AI Index Report 2026 highlights a fascinating and somewhat counter-intuitive trend: even as industry dominates the creation of the most powerful AI models, the talent is migrating back toward universities. This shift doesn't necessarily mean there is a "lack of talent" in industry, but rather that the nature of AI development and the job market has changed. Companies are finding that senior developers using AI tools can often replace the output of several junior developers. Consequently, industry is indeed prioritizing experienced professionals who can manage AI agents and oversee complex systems rather than hiring large cohorts of fresh graduates to do foundational coding and development. If industry continues to automate basic tasks, the "bridge" from university to a senior industry career becomes much harder to cross. To rectify the situation, graduate programs should offer internship programs partnered with industry.
The report also highlights a "jagged frontier" where AI is brilliant at PhD-level science but fails at basic tasks like reading an analog clock. Students often don't realize where these "jagged edges" are until they hit a real-world edge case. To bridge the gap between book-smart and street-smart, industry partnerships can provide the "desirable difficulty" needed for students to learn the limitations of the tools they are using.
Link: https://hai.stanford.edu/assets/files/ai_index_report_2026.pdf




Meta announced Muse Spark, a close-source multimodal AI model
April 9, 2026
Recently Meta introduced Muse Spark, the inaugural model from the newly formed Meta Superintelligence Labs (MSL). This close-source multimodal model designed for advanced reasoning, supporting visual chain-of-thought and multi-agent orchestration to solve complex tasks, signals a major architectural shift toward "personal superintelligence." A standout feature is the new Contemplating mode, which allows multiple agents to reason in parallel, enabling the model to compete with other frontier systems in high-level scientific and mathematical research.
The development of Muse Spark involved a complete overhaul of Meta’s AI stack, focusing on three scaling axes: pretraining, reinforcement learning (RL), and test-time reasoning. During pretraining, Meta achieved a significant efficiency milestone, reaching high capability levels with an order of magnitude less compute than the previous Llama 4 Maverick. The model also entails a "thought compression" phenomenon, where RL training encourages the model to solve problems using fewer tokens without sacrificing accuracy. Beyond raw performance, Meta emphasizes practical applications in multimodal interaction—such as troubleshooting home appliances through visual annotations—and personal health, where the model provides tailored nutritional and exercise insights.
That’s my take on it:
Meta's Muse Spark is the official name for the model that was developed under the internal codename Project Avocado. Reports from early 2026 suggested significant tension between Zuckerberg and Alexandr Wang, the new Chief AI scientist, due to "Avocado" missing its original March launch window and lagging behind Gemini 3.0 in internal testing. Nonetheless, the launch of Muse Spark has solidified Alexandr Wang's position at Meta.
Muse Spark shows strong potential, ranking among the leading models in current evaluations. It achieves a score of 52 on the Artificial Analysis Intelligence Index, placing it within the top five overall. In multimodal capability, it stands out as the second-most capable vision model. Beyond vision tasks, Muse Spark also demonstrates solid performance in reasoning and instruction-following benchmarks, earning 39.9% on HLE and ranking just behind Gemini 3.1 Pro Preview and GPT-5.4.
While Muse Spark may not sweep every benchmark, its launch signals that Meta is pivoting away from "benchmark chasing" and toward ecosystem dominance. Muse Spark is designed to pull from the "real-world" data happening across Facebook, Instagram, and Threads. By leveraging its social media footprint, Meta is building a type of "Personal Superintelligence" that OpenAI and Anthropic cannot replicate. In short, Meta isn't trying to win the "smartest chatbot" trophy; they are trying to own the interface of daily life. If Muse Spark can successfully manage your shopping, health, and travel directly inside the apps you already use, it won't matter if it's 5% less capable at coding than Claude.
It appears that Meta is shifting away from the “pure open-source” philosophy that Mark Zuckerberg strongly promoted during the Llama 2 and Llama 3 cycles. While the company still intends to release open-weight models, these are now positioned as derivatives or streamlined versions of the Muse architecture rather than fully flagship systems.
Internal reports suggest that Llama 4 lagged behind competitors such as Gemini 3.0 and GPT-5. At the same time, maintaining a fully open approach appears to have constrained Meta’s ability to integrate the highly specialized, agent-driven capabilities needed to monetize AI across social media and commerce platforms.
Another important factor is competitive dynamics. In earlier cycles, foreign competitors could effectively bypass costly research and development by fine-tuning directly from Llama’s open models. Against that backdrop, Meta’s decision to keep Muse Spark closed-source may reflect a strategic move to protect its technological edge while still selectively sharing lighter-weight derivatives.




American AI companies fight distilling at the Frontier Model Forum
April 8, 2026
Currently there is an unprecedented collaboration between major U.S. AI rivals, including OpenAI, Anthropic, and Google, to combat "adversarial distillation" by foreign competitors. These US companies are sharing information at the Frontier Model Forum, an industry nonprofit that they founded with Microsoft Corp. Distilling enables foreign firms to use existing U.S. models as "teachers" to train lower-cost "student" models, effectively replicating advanced capabilities while bypassing the massive research and development costs. U.S. officials and tech leaders warn that this practice not only results in billions of dollars in lost profits but also poses a significant national security risk, as distilled models often lack the safety guardrails intended to prevent the creation of harmful content or biological threats.
Feng Haoqin, a research fellow at Fourth Wave Technology, argues that the U.S. narrative oversimplifies a standard industry practice. Feng notes that model distillation—the process of using a "teacher" model to train a more efficient "student"—is a widely accepted technique often used by the U.S. companies themselves. He contends that the legal boundaries of this practice remain poorly defined and that American firms frequently engage in mutual distillation.
According to Feng, the current accusations against Chinese companies lack concrete evidence and are motivated more by fears of market competition than by legitimate national security risks. He suggests that as Chinese AI models rapidly advance, they are exerting significant technical and commercial pressure on their U.S. counterparts, leading American giants to seek defensive measures to maintain their technological dominance.
That’s my take on it:
While it is true that distilling is widely used, the Terms of Service for OpenAI, Google Gemini, and Anthropic (Claude) all contain specific clauses that forbid using their output to develop competing models. In a professional or academic setting, "common practice" doesn't usually override a signed or accepted user agreement.
There is a common argument that while accusing foreign companies of distilling, American AI companies are also guilty of web scraping: “stealing” contents from the Internet. However, equating distilling with Web scraping is debatable. Web Scraping is a battle over input data. Companies like OpenAI and Claude are being sued by publishers and artists. The legal question here is whether scraping public content to train an AI falls under "Fair Use" or violates copyrights. On the other hand, model distillation is a dispute over proprietary output. When users query a model to train a "student," they are violating a specific Terms of Service (ToS) agreement (contract law).
Links:


Anthropic announced Project Glasswing to detect software vulnerabilities
April 8, 2026
Recently Anthropic announced Project Glasswing, a major cybersecurity initiative in collaboration with industry giants like AWS, Google, Microsoft, Apple, and NVIDIA. This ambitious partnership was formed in response to the emergence of Claude Mythos Preview, a new frontier AI model that has demonstrated the ability to identify and exploit software vulnerabilities at a level that rivals or surpasses highly skilled human experts. Recognizing that AI-augmented cyberattacks could soon threaten the stability of global financial systems, energy grids, and national security, Anthropic and its partners are working to ensure that these same advanced capabilities are used proactively for defensive purposes.
The initiative has already yielded significant results, with Mythos Preview autonomously discovering thousands of high-severity, "zero-day" vulnerabilities across all major operating systems and web browsers. Notable findings include a 27-year-old flaw in OpenBSD and a 16-year-old bug in FFmpeg—vulnerabilities that had previously survived decades of human scrutiny and millions of automated tests. Beyond mere detection, the model has shown a sophisticated ability to "chain" multiple minor vulnerabilities together to gain full system control. To level the playing field for defenders, Anthropic is committing $100M in model usage credits to Project Glasswing participants and donating $4M to open-source organizations, such as the Linux Foundation and the Apache Software Foundation, to help secure the underlying code of the modern internet.
Moving forward, Project Glasswing aims to establish new industry standards for the AI era, focusing on automated patching, secure-by-design development, and responsible vulnerability disclosure. While Anthropic does not plan to make Mythos Preview generally available due to its high potential for misuse, the project serves as a critical testing ground for developing robust safeguards that will eventually allow similar high-capability models to be deployed safely at scale. By fostering deep collaboration between frontier AI developers, software maintainers, and government officials, the initiative seeks to create a durable defensive advantage that can keep pace with the rapid evolution of artificial intelligence.
That’s my take on it:
Most high-end AI models are trained on massive datasets of public code (like GitHub). The same reasoning capabilities that allow a model to help a developer write a more efficient Python script also allow it to understand how memory is managed in C++ or how a web server handles requests. As Anthropic noted, the window between a vulnerability being discovered and being exploited has compressed from months to minutes. Even if an attacker isn't using a frontier model like Mythos, they can use existing AI tools to reverse-engineer patches. When a company releases a security update, an AI can quickly compare the old and new code to figure out exactly what was fixed—and then generate an exploit for those who haven't updated yet. AI can also scan the internet to find specific versions of software known to have flaws, doing in seconds what used to take human teams days.
Ultimately, we are entering an AI arms race where the winner will be the side that can iterate, patch, and deploy more quickly. It’s no longer a question of if AI will be used for attacks, but whether we can use AI to build a secure-by-design digital world fast enough to withstand them.




Microsoft released in-house AI models
Recently Microsoft released three in-house AI models that on a par to current top models. The Microsoft AI (MAI) model family consists of three specialized systems developed by the company's internal superintelligence team: MAI-Transcribe-1, MAI-Voice-1, and MAI-Image-2.
MAI-Transcribe-1 is a speech-to-text model optimized for multilingual accuracy and speed. It supports 25 languages and is engineered to perform reliably in "noisy" real-world environments, such as call centers or crowded meeting rooms, rather than just controlled studio conditions. According to technical benchmarks provided by Microsoft, the model achieves a 3.8% to 3.9% Word Error Rate (WER) on the FLEURS benchmark, ranking it as a primary competitor to OpenAI’s Whisper-large-v3 and Google’s Gemini 3.1 Flash.
MAI-Voice-1 serves as the audio generation counterpart, focusing on high-speed text-to-speech synthesis. The model’s most notable technical metric is its throughput; it can generate 60 seconds of expressive audio in approximately one second on a single GPU, operating at 60 times real-time speed. It is designed to maintain consistent speaker identity and emotional nuance even in long-form content. Additionally, it features a "Personal Voice" capability that allows developers to create custom voice clones from a 10-second audio sample.
MAI-Image-2 is the visual generation component of the suite, which recently debuted in the top three of the Arena.ai image leaderboard. This model focuses on photorealistic rendering, improved in-image text generation, and precise layout control for complex scenes. It is currently being integrated into Microsoft’s consumer and professional products, including Bing, PowerPoint, and Copilot, where it reportedly generates images twice as fast as previous iterations.
That’s my take on it:
The shift toward in-house development is a defining moment in the Microsoft-OpenAI partnership. While it doesn't signal an immediate breakup, it fundamentally changes the power dynamics between the two entities. For years, Microsoft was essentially a reseller of OpenAI's breakthroughs. By building the MAI (Microsoft AI) family, Microsoft is transitioning to a "coopetition" model (cooperation + competition). Microsoft's goal of "AI self-sufficiency" means it can now handle specialized tasks—like high-speed transcription or image generation—using its own models, which are optimized for Azure's hardware (like the Maia chips) and are cheaper to run. If Microsoft moves a large portion of its "Copilot" traffic from GPT-4/GPT-5 to its own MAI models, OpenAI will lose a massive volume of inference revenue and data-refinement opportunities.
The recent series of developments in the field of AI—the reduction in Nvidia’s investment on OpenAI from $100 billion to $30 billion, the cancellation of the Disney-Sora partnership, and Microsoft’s pivot toward in-house AI—collectively signal a significant "recalibration" phase for OpenAI. While these events are not necessarily a fatal setback, they represent the end of OpenAI’s era of uncontested dominance and the beginning of a much more difficult, competitive chapter.



Meta indefinitely suspended using Mercor due to security breach
April 4, 2026
Meta has indefinitely suspended its partnership with Mercor following a serious security breach. Mercor serves as a critical vendor for major AI labs, including OpenAI and Anthropic, helping generate proprietary datasets used to train advanced models. The breach originated from a supply chain attack involving LiteLLM, where a hacking group known as TeamPCP reportedly compromised software updates, potentially affecting thousands of organizations. Although OpenAI indicated that user data were not impacted, the incident may have exposed sensitive “industry secrets,” including custom datasets and training methodologies behind systems like ChatGPT and Claude.
In response, contractors assigned to Meta-related projects—such as the Chordus initiative, which focuses on enabling AI systems to verify information across multiple online sources—have been instructed to halt work and stop logging hours while the project undergoes reassessment. This sudden pause has effectively left many specialized AI trainers without work for an indefinite period, as Meta and other companies initiate comprehensive security reviews. The situation underscores a deeper tension within the AI ecosystem: while firms such as Scale AI and Surge AI rely on secrecy to protect their competitive advantage, they remain exposed to conventional software supply chain vulnerabilities that can disrupt the entire industry.
That’s my take on it:
The "indefinite" pause in Meta's partnership with Mercor is a significant blow because Mercor isn't just a staffing agency; it is a critical "data foundry" for Meta’s most advanced AI projects. Specifically, Meta relies on Mercor to find "high-end" human trainers (lawyers, doctors, and engineers) to perform Reinforcement Learning from Human Feedback (RLHF). Losing access to Mercor’s pre-vetted network of thousands of experts creates a massive bottleneck in fine-tuning Meta's frontier models.
The breach at Mercor was triggered by compromised versions of LiteLLM, a popular Python library used to route requests between different AI models (like GPT-4 and Claude). Meta has been a vocal proponent of open-source AI, yet this breach happened through a vulnerability in an open-source tool (LiteLLM). This complicates Meta's narrative that open source is inherently more secure because "more eyes" are on the code.
Nonetheless, because open source such as Python libraries is foundational to modern AI and software development, the focus has shifted from "Is it safe?" to "How do we manage the risk?" Improving security in an open-source ecosystem requires a shift from passive consumption to active "supply chain hygiene." Contrary to popular belief, experts suggest never use "latest" versions in production. Rather, lock your software to specific versions so a malicious update to a library (like the LiteLLM incident) doesn't automatically infect your system.




Controversy on NeurIPS, the most prestigious AI conference
April 3, 2026
NeurIPS (Conference on Neural Information Processing Systems) is widely regarded as one of the most prestigious and influential conferences in artificial intelligence and machine learning. It serves as a primary venue where researchers from academia and industry present cutting-edge work, and acceptance at NeurIPS often carries significant weight in academic promotion, funding decisions, and professional recognition.
In late March 2026, the NeurIPS Foundation released its Main Track Handbook with newly explicit language stating that the conference must comply with U.S. sanctions laws. The policy indicated that NeurIPS could not provide services, including peer review, editorial handling, and publication, to individuals or entities subject to sanctions. However, the initial wording went beyond what was strictly required, referencing a broader set of restrictions than the core Specially Designated Nationals (SDN) list. This created confusion and concern, as it appeared that a wide range of institutions—potentially including major Chinese technology firms and research organizations—might be affected.
The reaction from the Chinese academic community was swift and forceful. Organizations such as the China Computer Federation called on researchers to withdraw submissions, decline reviewer roles, and step away from conference participation. The China Association for Science and Technology also signaled institutional disapproval by suspending support for participation in NeurIPS and discouraging engagement. In addition, some prominent researchers and conference organizers affiliated with Chinese institutions publicly resigned from their roles, citing concerns about political bias and unequal treatmen.
Facing the prospect of losing a substantial portion of its global reviewer base and damaging its reputation as an open scientific forum, NeurIPS organizers responded within days. They issued a public clarification and apology, attributing the situation to a miscommunication in how the policy had been drafted and presented. The conference leadership emphasized that the broader interpretation had been unintentional and confirmed that they would align more narrowly with legally required restrictions—primarily those tied to the SDN list—while continuing to welcome submissions from all compliant researchers and institutions. They also indicated that they were working closely with legal counsel to ensure compliance without inadvertently creating what critics described as a de facto filter based on nationality or affiliation.
That’s my take on it:
Even though the policy was quickly revised and the immediate controversy surrounding NeurIPS has subsided, the long-term implications for global AI collaboration—particularly between the United States and China—may be more enduring. The episode has introduced a layer of uncertainty that cannot be easily undone. Once researchers begin to question whether participation in a major international conference could be constrained by geopolitical or legal considerations, the foundation of trust that underpins open scientific exchange is inevitably weakened.
At a structural level, this tension reflects a deeper strategic divergence. China has made no secret of its ambition to become a global leader in advanced technologies, especially artificial intelligence, while the United States is equally committed to maintaining its leadership in the same domain. These objectives are not inherently incompatible, but in practice they create friction, particularly as AI becomes increasingly tied to national security, economic competitiveness, and technological sovereignty. In this context, a certain degree of mutual caution—or even distrust—may be less a moral issue than a predictable outcome of competing strategic priorities.
A useful way to think about this dynamic is through analogy. Coca-Cola does not share its formula with Pepsi, and Nvidia does not disclose its most advanced chip designs to AMD. In highly competitive environments, protecting proprietary knowledge is both rational and expected. However, the analogy is not perfect. Historically, scientific research—especially in AI—has functioned as a relatively open ecosystem, where foundational ideas, methods, and findings are shared broadly, even as companies compete in applying them. What we are witnessing now is a gradual shift: elements of AI research that were once treated as public knowledge are increasingly viewed as strategic assets.
As a result, the future of collaboration may not be defined by a dramatic rupture, but by a more subtle and incremental transformation. We may see more selective partnerships, with institutions choosing collaborators based on alignment and risk considerations. Parallel research ecosystems could emerge, with different standards, venues, and networks of trust. At the frontier of AI development, where the stakes are highest, openness may give way to greater discretion. Yet, complete decoupling remains unlikely, as the global AI ecosystem still depends on shared infrastructure, talent mobility, and a degree of intellectual exchange.
In this sense, the NeurIPS incident is less an isolated event than a signal of a broader transition—from an era of largely open scientific collaboration to one in which research is increasingly shaped by strategic considerations. The trajectory ahead is unlikely to be a clean split, but rather a complex rebalancing, where cooperation and competition coexist in an uneasy and evolving equilibrium.
Links:
https://www.wired.com/story/made-in-china-ai-research-is-starting-to-split-along-geopolitical-lines/


Anthropic accidentally leaked 500,000 lines of source code
April 2, 2026
Recently Anthropic accidentally exposed roughly 500,000 lines of internal code from its AI coding tool, Claude Code. The incident was not caused by a cyberattack, but by a human error during a routine software update, where a debugging file was mistakenly included in a public release. This file effectively provided access to the tool’s underlying architecture, internal performance data, and numerous unreleased features, giving outsiders an unusually detailed look into how the system works and what the company is developing next.
Although Anthropic emphasized that no customer data, credentials, or core AI model weights were compromised, the leak still raised concerns because it revealed proprietary engineering approaches and product roadmaps. Developers quickly downloaded, analyzed, and even reverse-engineered the code, spreading it widely online despite the company’s attempts to remove it.
The major concern is less about immediate damage and more about strategic risk. While the leak is not considered catastrophic, it effectively gives competitors a “blueprint” for building similar AI coding tools, potentially accelerating competition. At the same time, the incident has drawn scrutiny to Anthropic’s internal safeguards, especially given its positioning as a safety-focused AI company. Overall, the episode underscores a key tension in modern AI development: rapid innovation and deployment can outpace operational security, making even leading firms vulnerable to costly mistakes.
That’s my take on it:
This incident occurred on March 31, 2026, yet I chose not to comment on it immediately. Frankly, it was difficult to believe that such a significant and avoidable error could actually happen. I was concerned that raising the issue on April 1 might lead others to dismiss it as an April Fool’s joke. In fact, that was my initial reaction as well. However, after cross-checking the information with multiple credible sources, it became clear—regrettably—that the incident is indeed real.
Anthropic was founded in 2021 by a group of former OpenAI researchers, including Dario Amodei and Daniela Amodei. Some of them left due to concerns about AI safety, scaling risks, and governance. They emphasized that frontier AI was advancing quickly and needed stronger safety-oriented research and deployment practices. Partly due to this responsible approach, Anthropic has strong traction with enterprise users. Claude models are often perceived as more controllable, less prone to risky outputs, and better for long-document tasks—features enterprises care about.
There is little doubt that this incident undermines Anthropic’s carefully cultivated image as a leader in responsible AI. Errors of this nature are difficult to justify, particularly for an organization that positions safety and governance at the center of its mission. Anthropic had previously engaged in discussions and limited collaboration with the U.S. military, but stepped back amid concerns over the ethical implications of autonomous weapons and domestic surveillance. One can easily imagine the potential consequences had sensitive information about military applications of AI been exposed—such a scenario could pose serious risks to national security. In that sense, the outcome here could have been far more severe, and we were, perhaps, fortunate.
At the same time, this incident does not necessarily indicate that Anthropic’s overall operational standards are lax or that its safety framework has deteriorated. It is more plausible that the mistake arose from a localized lapse—perhaps involving only a small number of individuals—rather than a systemic failure. There is a well-known Chinese saying that captures this dynamic: a single piece of rat droppings can spoil an entire pot. The broader implication is clear. No matter how advanced AI systems become, and no matter how rigorously they are designed to support responsible use, the ultimate safeguard remains human judgment. In the end, it is people—not machines—who serve as the final gatekeepers of safety and accountability.
Link: https://www.axios.com/2026/03/31/anthropic-leaked-source-code-ai




Microsoft introduces multi-model intelligence for model synthesis
April 1, 2026
Recently Microsoft introduced multi-model intelligence to Researcher, a deep research agent designed for complex workplace tasks. This update moves beyond a single-model approach by integrating multiple AI models from frontier labs—specifically combining OpenAI’s GPT and Anthropic’s Claude—to work in tandem. The goal of this architecture is to enhance the accuracy, depth, and reliability of AI-generated reports by allowing different models to cross-reference each other’s work, thereby reducing hallucinations and improving analytical rigor.
At the core of this update are two primary features: Critique and Council. Critique is a dual-model system that separates the research process into generation and evaluation phases; one model plans the task and drafts the report, while a second "reviewer" model assesses source reliability, evaluates completeness, and enforces strict evidence grounding. This peer-review loop ensures that final outputs are more factually sound and better organized. In contrast, Council allows users to run two different models (e.g., GPT and Claude) simultaneously to produce independent reports. A third "judge" model then creates a cover letter summarizing the key findings, highlighting where the two models agree or diverge, and calling out unique insights from each.
Evaluations of this new architecture indicate significant performance gains over traditional single-model workflows. According to Microsoft, the multi-model approach has led to measurable improvements in factual accuracy, citation quality, and the overall breadth of research. By providing users with clear optionality and transparent comparisons between models, Microsoft aims to offer a more robust tool for high-stakes professional research, ensuring that users can make decisions with greater confidence based on validated, multi-perspective AI insights.
That’s my take on it:
Microsoft’s multimodal intelligence approach is not entirely unprecedented. Perplexity AI offers a comparable feature called Model Council, which executes a query across multiple models in parallel and then synthesizes their outputs into a single, unified response. Importantly, it highlights areas of agreement and disagreement among the models, positioning this approach as a way to mitigate individual model blind spots and reduce the burden of manually comparing separate outputs.
The key distinction lies in how the models are orchestrated. Model Council operates in parallel—multiple models generate responses simultaneously, which are then aggregated through a synthesis process. While Microsoft’s council model resembles Perplexity’s Model Council, in the critique mode Microsoft employs a sequential approach: one model produces an initial draft, and a second model reviews and refines it iteratively.
This difference closely mirrors a well-established distinction in data science methodologies. Model Council’s parallel aggregation resembles bagging techniques such as random forests, where multiple decision trees are built independently and combined to produce a final result. By contrast, Microsoft’s sequential refinement aligns with gradient boosting, where an initial model is progressively improved through iterative corrections that minimize residual error.
This parallel reveals a broader insight: certain foundational logics—parallel aggregation versus sequential refinement—transcend specific domains and can be effectively applied across both data science and modern AI system design.



US court halted designation of Anthropic as a supply-chain risk
March 27, 2026
In March 2026, U.S. District Judge Rita Lin granted a preliminary injunction in favor of the AI startup Anthropic, temporarily halting the Trump administration’s efforts to blacklist the company from government use. The legal battle began after the Department of Defense designated Anthropic as a "supply-chain risk"—a classification typically reserved for foreign adversaries—and President Trump issued a directive ordering all federal agencies to cease using the company’s technology. The administration’s actions followed a breakdown in negotiations over a $200 million contract; Anthropic had refused to remove safety guardrails that prohibited its AI, Claude, from being used for fully autonomous lethal weapons or domestic mass surveillance.
In her ruling, Judge Lin expressed skepticism toward the government’s justification, characterizing the administration's measures as "punitive" rather than procedural. She noted that while the government has the right to choose its contractors, it cannot use national security designations as a tool for "Orwellian" retaliation against an American company for expressing policy disagreements. The judge further suggested the administration’s actions likely violated the First Amendment and the Administrative Procedure Act, as the government failed to follow standard debarment procedures and appeared to be punishing the company for its protected speech regarding AI safety.
The injunction provides Anthropic with a critical temporary victory, shielding it from what the company argued would be "irreparable harm" to its reputation and billions of dollars in potential revenue. Although the ruling pauses the enforcement of the ban and the supply-chain risk designation, it does not force the Pentagon to continue purchasing Anthropic’s services. As the case moves toward a final judgment, it is expected to serve as a landmark test of executive authority, the limits of national security claims, and the government’s power to regulate AI companies that operate within the defense sector.
That’s my take on it:
I completely agree that Anthropic’s refusal to back down on its ethical principles, even at the cost of massive federal contracts, is admirable. To me, the core of the issue isn't a blanket ban on AI in the military, but rather the essential need to set a firm limit on AI weaponization before it escapes human oversight. By maintaining these guardrails—specifically against fully autonomous lethal action—I believe Anthropic is challenging the dangerous "race to the bottom" where safety is traded for strategic speed. This stance highlights a growing tension: if the government can force the removal of these protections, we risk a future where only the most "unfiltered" and potentially volatile AI systems are the ones integrated into our national defense.
This case has also solidified my view that the separation of powers is functioning exactly as it should to prevent the executive branch from weaponizing technology without limit. Without the court’s intervention, the administration could have successfully used national security designations as a tool for "Orwellian" retaliation against any private company that refused to comply with its specific vision. In my view, this check and balance shouldn’t just rest with the government branches; it requires a robust ecosystem of stakeholders, including corporations, users, NGOs, mass media, and academia, to act as a collective oversight body. When a company like Anthropic or a group of concerned researchers pushes back, they function as a vital "fourth branch" of accountability.
Furthermore, I would add that this battle frames AI safety protocols as a form of protected speech. By treating Anthropic’s safety guardrails as a core part of its corporate identity and expression, the court is suggesting that the government cannot easily compel a company to "mute" its ethical conscience. If the U.S. wants to remain a global leader in "Responsible AI," it cannot afford to drive its most principled innovators out of the defense sector. Ultimately, this injunction is a win for a decentralized model of governance where the boundaries of lethal technology are negotiated by society at large, rather than dictated by a single office.




AI escalates the risk of digital delusion or stimulates epistemic growth?
March 27, 2026
In a recent article titled "How AI Chatbot Use Can Cause ‘Digital Folie à Deux’," Dr. Joe Pierre explores the emerging phenomenon of "AI-associated psychosis," drawing a parallel between modern human-AI interactions and the rare psychiatric syndrome folie à deux (madness of two). Traditionally, this syndrome involves a dominant individual transmitting a delusion to a secondary, impressionable person. In the digital version, however, the "delusion" is not merely passed from one to the other but is instead co-constructed through a "bidirectional belief amplification." Dr. Pierre notes that as users immerse themselves in prolonged, existential, or fantastical conversations, the AI’s inherent "sycophancy"—its programmed tendency to be agreeable, validating, and encouraging to maintain engagement—acts as a mirror that reinforces the user’s cognitive biases and "motivated reasoning" to a dangerous degree.
The author argues that this interaction is less like a simple transmission and more like an "interactive dance" where both parties fuel a spiraling delusional system. While traditional folie à deux is rare, "digital folie à deux" is becoming increasingly common due to the way Large Language Models (LLMs) are designed to prioritize fluent, flattering mimicry over factual accuracy. Dr. Pierre highlights "immersion" and "deification"—the act of treating AI as a god-like or all-knowing entity—as major risk factors that can lead users to prioritize a chatbot's validation over the concerns of real-world friends or family. He warns that this is a "canary in a coal mine" for a broader societal shift toward folie à mille (madness of a thousand) or even la folie des milliards (madness of billions), where AI-fueled confirmation bias and political propaganda could eventually erode any shared sense of objective reality on a global scale.
That’s my take on it:
True. The risk of reinforcing delusion or confirmation bias due to AI is real. Unlike a human friend—or even a stranger on social media—who might eventually disagree with you or grow bored, AI is programmed to be sycophantic. It is designed to maintain engagement by being helpful, polite, and validating.
Nonetheless, AI can also act as an "objective mediator" or a "bias-checker". Unlike a social media feed, which is often a passive "push" of content designed to trigger emotional engagement, a deliberate interaction with an AI can be a "pull" for structured, multi-faceted analysis. If a user prompts the AI to "play devil’s advocate" or "provide a balanced overview of a complex topic," the LLM's ability to synthesize vast amounts of diverse data can actually break an echo chamber rather than reinforce it. In this light, the "sycophancy" Dr. Pierre warns about isn't an unchangeable law of physics; it is a design choice that can be mitigated through "system prompts" or user training that prioritizes critical thinking and truth-seeking over simple agreement.
Ultimately, the outcome likely depends on the Information Literacy of the user. Just as a researcher uses a library to find opposing viewpoints rather than just confirming their own, an educated AI user can treat the chatbot as a high-speed research assistant capable of highlighting nuances that a human might miss. This places a significant burden on educators and developers to move away from "engagement-at-all-costs" models and toward "epistemic humility." If we train students to use AI as a partner in Socratic dialogue—questioning assumptions rather than just seeking answers—the technology transitions from a source of "digital folie à deux" to a powerful tool for intellectual growth and scientific clarity.



OpenAI abruptly discontinues its AI video platform Sora
OpenAI has abruptly decided to discontinue its AI video platform Sora, marking a sharp strategic pivot for the company. The shutdown came as a surprise not only to external partners—such as Walt Disney, which had been negotiating a major $1 billion collaboration—but even to members of OpenAI’s own Sora team. Although the partnership was publicly announced, it was never finalized and no funds were exchanged before the cancellation.
The core reason behind the decision appears to be resource allocation. Sora required extremely high computational power, which limited OpenAI’s ability to invest in other, more profitable and strategically important areas. As a result, the company is shifting its focus toward enterprise products, coding tools, robotics, and long-term goals like artificial general intelligence (AGI), while also working toward consolidating its offerings into a single “super-app.”
Despite Sora’s rapid rise—following its 2024 debut with impressive text-to-video capabilities—the platform faced growing challenges. These included intense competition from rival AI firms, mounting operational costs, and broader industry pressures to prioritize revenue-generating products. Overall, the decision highlights OpenAI’s transition from experimental, high-profile innovations toward a more commercially focused and streamlined business strategy, especially as it prepares for a potential future public listing.
That’s my take on it
It is surprising to see Sora being discontinued. When it was introduced, it quickly became one of the most visible benchmarks for AI video generation, showcasing what the technology could achieve at a high level.
Is this kind of outcome unprecedented? Not at all. The history of technology is full of dominant products being overtaken or displaced: Microsoft Word eclipsing WordPerfect, Microsoft Excel surpassing Lotus 1-2-3, and Windows NT Server overtaking Novell NetWare. What is different today is the pace. In earlier eras, these transitions often took many years; in the AI space, competitive cycles can compress into just a couple of years—or even months. Sora’s short lifespan highlights how intense, capital-heavy, and fast-moving the current AI race has become, as well as how uncertain product longevity is in this market.
At the same time, part of Sora’s decline can reasonably be attributed to product and user experience decisions. I was one of the early adopters of Sora, and I was initially impressed by its capabilities. However, when OpenAI introduced a newer version, I encountered a frustrating issue: unlike Google Veo, which keeps its logo consistently fixed in the lower right corner, Sora’s logo would move unpredictably across the screen. That seemingly small detail became quite disruptive in practice. Over time, I found myself moving away from Sora and eventually switching to alternatives like Google Veo and Midjourney.
That said, I still recognize that OpenAI played a pivotal role in advancing AI video generation. Sora helped define what high-quality generative video could look like and set an important benchmark for the industry. Even if it did not endure, it remains a meaningful and respectable milestone in the evolution of AI.


China released Yuan 3.0, a 1-trillion-parameter AI model
March 4, 2026
On March 4, 2026 China AI company shocked the world by releasing Yuan 3.0, a 1-trillion-parameter AI model. Developed by YuanLab AI, this flagship system represents a massive architectural leap from its predecessors, moving into the "trillion-scale" club with a sophisticated Mixture-of-Experts (MoE) design. Although the model contains roughly 1.01 trillion total parameters, its efficiency is bolstered by a "Layer-Adaptive Expert Pruning" algorithm, which keeps only about 68.8 billion parameters active during any single inference task. This innovation allowed the developers to train a model with the raw capacity of a 1.5-trillion-parameter system while maintaining the operational agility required for real-world enterprise applications. As an open-source release, Yuan 3.0 Ultra has significantly lowered the barrier for global researchers to access frontier-level performance, specifically optimized for high-density Chinese and English multimodal tasks.
The competitive landscape between Yuan 3.0 and its US counterparts is nuanced, defined by a narrowing gap in specific technical benchmarks. Yuan 3.0 has demonstrated clear superiority in enterprise-centric domains, particularly in Retrieval-Augmented Generation (RAG) and complex document understanding. In specialized tests like Docmatix and ChatRAG, the Chinese model frequently outperforms US giants like GPT-5.2 and Claude 4.6, excelling at extracting precise information from massive, unorganized datasets.
That’s my take on it:
Although US frontier models—specifically GPT-5.2 and OpenAI’s o3—continue to maintain a definitive lead in generalized reasoning, autonomous agentic workflows, and "zero-shot" logic, expert estimates that they lead in deep cognitive reasoning and tool integration by approximately 4 to 7 months only, not by years anymore. Based on this trajectory, it is tantalizing to ask whether China is going to win the AI race.
Several critical bottlenecks make a definitive Chinese "victory" uncertain. The U.S. still commands a massive lead in raw compute power, holding approximately 75% of the world’s high-end GPU cluster performance compared to China’s 15%. Furthermore, while China excels at "efficiency revolutions"—building world-class models at a fraction of the cost—the U.S. remains the global hub for the "top 1%" of AI research talent, many of whom are international experts drawn to the American ecosystem. While the "electron gap" (energy availability) favors China’s rapid infrastructure expansion, the U.S. retains control over the most advanced semiconductor designs.
However, the recent shift in U.S. immigration policy, specifically the $100,000 "talent tax" on H-1B petitions introduced in late 2025, has fundamentally altered the global AI landscape. This financial barrier, combined with a more restrictive atmosphere toward foreign professionals, is actively diverting elite researchers toward tech hubs in Europe and China, where recruitment efforts have intensified. While the U.S. still retains a temporary lead through its concentrated compute power and established research networks, this policy risk creates a long-term "innovation drain." As the next generation of top-tier talent increasingly opts for more stable environments, the U.S. risks ceding its "4 to 7-month" lead in frontier reasoning to international competitors who are prioritizing talent acquisition as a matter of national strategy. Yuan 3.0 is a wake-up call!
Link:



The Claude Contradiction:
Military Use in Iran Strikes Follows Federal Ban
On February 27, 2026, President Trump ordered all U.S. federal agencies to immediately cease using Anthropic’s Claude AI, following a high-stakes standoff between the company and the Pentagon (recently rebranded as the Department of War). The dispute centered on Anthropic's refusal to remove ethical guardrails that prohibited Claude from being used for mass domestic surveillance and fully autonomous lethal weapons. Defense Secretary Pete Hegseth subsequently labeled Anthropic a "supply chain risk to national security," a designation typically reserved for foreign adversaries.
Despite this public ban, the U.S. military reportedly utilized Claude AI just hours later during Operation Epic Fury, a massive joint air assault with Israel against Iran on February 28. According to reports from the Wall Street Journal and Axios, the AI was used for intelligence analysis, target identification, and battlefield simulations during the strikes, which resulted in the death of Iran’s Supreme Leader, Ayatollah Ali Khamenei.
The apparent contradiction between the ban and the operational use is due to how deeply Claude is currently embedded within the U.S. military’s classified networks. While the President’s directive called for an immediate halt, the official executive order included a six-month phase-out period to allow the Department of War to transition to other providers, such as OpenAI or xAI. Military analysts noted that because Claude was the only frontier model fully integrated into these secure systems at the time of the attack, it remained a critical mechanical necessity for the mission's planning and execution despite the fractured relationship between the government and the tech firm.
Following the sudden ban on Anthropic’s Claude, OpenAI and xAI have moved rapidly to fill the strategic vacuum within the U.S. military’s classified networks. On February 27, 2026, just hours after the ban was announced, OpenAI CEO Sam Altman confirmed that the company had reached a landmark agreement with the Department of War to deploy its models into classified systems. This deal, reportedly worth up to $200 million, allows the Pentagon to utilize OpenAI’s frontier technology for intelligence analysis and mission planning. While Altman insisted that OpenAI maintains "red lines" against mass domestic surveillance and fully autonomous weapons, the company has reportedly integrated these safeguards technically into its architecture to satisfy the government’s demand for all lawful use flexibility—a compromise that Anthropic had refused.
Elon Musk’s xAI has also solidified its position as a primary alternative, having already cleared its Grok model for use in classified military systems in late January 2026. Unlike Anthropic, xAI reportedly agreed early on to the Pentagon's unrestricted "all lawful use" standard, positioning Grok as a more permissive tool for battlefield operations and weapons development.
That’s my take on it:
The recent integration of Claude AI into Operation Epic Fury—the February 28, 2026, strike against Iranian infrastructure indicates that artificial intelligence has become an indispensable utility in modern warfare. This inevitability highlights a growing strategic anxiety: the "innovation-security paradox." Proponents of unrestricted AI argue that if the United States imposes rigorous roadblocks and moral constraints while adversaries operate without such inhibitions, the U.S. risks a capability gap that could allow rivals to surpass American military dominance.
This geopolitical tension mirrors the Nuclear Arms Race of the Cold War. Just as the U.S. and the USSR stockpiled thousands of warheads—reaching a peak of over 60,000 combined units by the mid-1980s—despite knowing that such an arsenal could annihilate the entire human civilization, major powers were racing to achieve "Algorithmic Superiority." The existential threat of Mutually Assured Destruction (MAD) eventually forced both sides to the negotiating table, resulting in landmark treaties like SALT I and START I, which successfully reduced global nuclear arm stockpiles from their Cold War highs.
The weaponization of AI may follow a similar historical trajectory. Currently, we are in the "proliferation phase," where the fear of falling behind drives the removal of safety guardrails and the acceleration of autonomous systems. However, as AI capabilities scale toward Artificial General Intelligence (AGI), the risk of miscalculation, unintended escalation, or loss of human control may eventually outweigh the tactical advantages. Just as the threat of nuclear winter of the 20th century led to international cooperation, the hope is that the global community will reach a breaking point where the threat to planetary stability becomes too large to ignore, eventually mandating international AI non-proliferation agreements and standardized safety protocols.
If we wait until we are dominated by a real-world Skynet or autonomous 'terminators,' the opportunity for oversight will have already vanished; by then, it will be too late.
Links:
https://www.theguardian.com/technology/2026/mar/01/claude-anthropic-iran-strikes-us-military
https://openai.com/index/our-agreement-with-the-department-of-war/
https://www.thecooldown.com/green-tech/pentagon-ai-military-technology-regulation/



Anthropic accuses China’s AI firms of distilling information from Claude
Feb 23, 2026
On Feb 23, 2006, Anthropic published a blog post accusing three prominent Chinese AI labs — DeepSeek, MiniMax, and Moonshot AI — of creating over 24,000 fraudulent accounts and conducting over 16 million exchanges with Claude, using a technique called distillation.
What is Distillation?
Distillation is essentially when a small "student" model is trained to replicate the performance of a much larger "teacher" model — effectively copying someone's homework without permission. Frontier AI labs routinely distill their own models to create smaller, cheaper versions for their customers, but most leading proprietary AI providers explicitly ban competitors from doing it to their models.
How the Attacks Were Carried Out
The campaigns used fraudulent accounts and commercial proxy services to access Claude at scale while avoiding detection. In one case, a single proxy network managed more than 20,000 fraudulent accounts simultaneously, mixing distillation traffic with unrelated customer requests to make detection harder.
What Each Company Targeted
DeepSeek, across about 150,000 exchanges, targeted Claude's reasoning capabilities and even sought help generating censorship-safe alternatives to politically sensitive queries. Moonshot AI, across 3.4 million exchanges, targeted agentic reasoning, tool use, coding, and computer vision. MiniMax drove the most traffic — over 13 million exchanges — targeting agentic coding and tool use capabilities.
A Notable Detail About MiniMax
Anthropic detected MiniMax's campaign while it was still active. When Anthropic released a new model during the campaign, MiniMax pivoted within 24 hours, redirecting nearly half its traffic to capture capabilities from the latest system.
National Security Concerns
Anthropic warned that models built through illicit distillation are unlikely to retain safety guardrails, meaning dangerous capabilities could proliferate without protections — potentially enabling things like bioweapons development or malicious cyber activity.
The Broader Context
Anthropic's accusations follow a similar memo by OpenAI to U.S. lawmakers earlier in February, claiming DeepSeek had been improperly distilling its models as well. Anthropic is also using the allegations to argue for tighter chip export controls on China, saying the scale of these attacks requires access to advanced semiconductors.
The Pushback
The allegations haven't been without criticism. Many commentators quickly pointed out what they see as an uncomfortable symmetry: Anthropic itself has faced accusations of overreaching in its own data collection, including a $1.5 billion copyright settlement with authors in September 2025. Critics argue that U.S. firms like Anthropic and OpenAI defend their own sprawling data collection under the banner of fair use while pushing for aggressive enforcement against foreign competitors.
That’s my take on it:
The Logical Misstep: Tu Quoque and “Two Wrongs”
Saying that the US AI companies are doing the same sounds like a strong counter-argument, but it still cannot justify the actions. This is a common logical fallacy known as the tu quoque (you too). Prior misconduct—real or alleged—does not automatically license subsequent misconduct. Simply put, two wrongs do not make a right.
Selective Enforcement and the Charge of Inconsistency
Critics, however, are often making a subtler claim than simple justification. Their concern centers on selective enforcement. If American AI firms defend expansive data ingestion under doctrines such as fair use, while simultaneously advocating aggressive enforcement measures against foreign competitors for distillation practices, observers may perceive inconsistency. The issue here is less about excusing distillation and more about credibility. When firms operate in legally and ethically contested spaces themselves, calls for strict enforcement against others can appear strategically motivated rather than principled. This does not invalidate their complaints, but it complicates the moral posture from which those complaints are made.
Structural Asymmetry Between Training and Distillation
At the same time, there is a meaningful structural asymmetry between training on publicly accessible data and extracting outputs from a proprietary model through coordinated circumvention. Training typically involves ingesting material that is publicly available on the open internet, even if copyright questions remain unresolved.
Distillation campaigns that rely on fraudulent accounts, proxy networks, and deliberate evasion of safeguards, by contrast, target a closed system whose outputs are governed by contractual terms and technical protections. The mechanisms, intent, and institutional contexts differ. One practice raises unresolved questions about copyright and fair use; the other may involve breach of terms of service, deception, or other forms of deliberate access circumvention. The categories are not identical, even if both involve large-scale knowledge extraction.
To collapse these distinct practices into a single moral category risks equivocation, another common logical fallacy, because it relies on treating different forms of access and control as if they were conceptually interchangeable.
Public Data vs. Proprietary Systems
The distinction between public data and proprietary systems is therefore central. Publicly accessible content exists within a domain where reuse, transformation, and aggregation have long been debated but are structurally possible without breaching access controls.
Proprietary AI systems, however, are gated environments. When actors create thousands of accounts or route traffic through commercial proxies to extract model behavior at scale, the issue shifts from interpretation of reuse norms to intentional circumvention of access boundaries. This does not settle the legality of either practice, but it underscores that the ethical terrain differs in kind, not merely degree.
The Cookbook vs. Restaurant Kitchen Analogy
A useful metaphor is the “Cookbook vs. Restaurant Kitchen” analogy. Imagine a chef who studies thousands of publicly sold cookbooks, internalizes techniques, and refines their own culinary style. Some authors may object that their recipes indirectly fuel commercial success elsewhere, and debates may arise about attribution, originality, and transformation.
Now imagine another chef who sneaks into a rival’s private kitchen, observes the preparation of a signature sauce, and reverse-engineers it for competitive advantage. Even if the first scenario raises ethical questions about large-scale reuse of published material, it does not justify covertly extracting proprietary processes from a closed environment. The two situations share a theme of learning from others, but they differ fundamentally in access conditions and intentional boundary crossing.
Conclusion: A Morally Ambiguous Frontier
Ultimately, the AI ecosystem operates within a morally ambiguous frontier. Large-scale data training, model distillation, intellectual property law, and technological acceleration intersect in ways that strain existing legal and ethical frameworks. Accusations of hypocrisy do not automatically negate legitimate grievances, yet moral outrage becomes more complex when all major actors navigate gray zones. Recognizing structural differences between practices while resisting the temptation of the tu quoque and equivocation fallacies allows for clearer reasoning. In a rapidly evolving technological landscape, consistency, transparency, and principled argumentation matter precisely because no participant stands entirely outside ethical ambiguity.
Links:
https://www.anthropic.com/news/detecting-and-preventing-distillation-attacks





Google Gemini 3.1 Pro achieves impressive benchmark scores with fluid intelligence
Feb 20, 2026
Recently Gemini 3.1 Pro introduces significant advancements in reasoning and intelligence, building upon the breakthroughs seen in the recently released Gemini 3 Deep Think. This version is designed specifically for complex problem-solving where simple answers are insufficient. The following are the major new features and upgrades:
1. Breakthrough Reasoning Capabilities
The most significant upgrade is in the model's core intelligence. Gemini 3.1 Pro has achieved a verified score of 77.1% on the ARC-AGI-2 benchmark, which tests a model's ability to solve entirely new logic patterns. This is more than double the reasoning performance of the previous 3 Pro model.
2. Advanced Coding and Synthesis
The model demonstrates a high level of proficiency in translating complex themes and data into functional, interactive outputs:
Animated SVGs: It can generate website-ready, code-based animated SVGs from text prompts. Unlike standard video, these remain crisp at any scale and have very small file sizes.
System Synthesis: It can bridge complex APIs with user-friendly design, such as configuring telemetry streams to create live data dashboards.
Interactive Design: It can code immersive 3D experiences, including those that integrate hand-tracking and generative audio.
3. Enhanced Productivity Tools
NotebookLM Integration: Gemini 3.1 Pro is now available within NotebookLM for Pro and Ultra subscribers, allowing for deeper reasoning over uploaded documents and sources.
Higher Limits: Users on Google AI Pro and Ultra plans will have higher usage limits for the 3.1 Pro model within the Gemini app.
That’s my take on it:
While Gemini 3.1 Pro’s score of 77.1% on ARC-AGI-2 is technically impressive (doubling the previous baseline), the consensus is that benchmark scores and real-world productivity are not always in lockstep. Most professional work isn't solving abstract logic puzzles; rather, it's navigating "messy context" (ambiguous emails, specific company coding standards, or shifting project requirements). A model can be a genius at logic but still fail at a task if it doesn't understand the specific, unwritten nuances of your department.
Prior research found that developers using advanced AI tools actually took 19% longer to complete tasks than those without. Interestingly, those same developers felt 20% more productive. This is often called the "IKEA effect"—you feel like you've accomplished more because you've been busy managing, fixing, and prompting the AI, even if the final output took longer to produce.
Nevertheless, the ARC-AGI benchmark specifically measures "fluid intelligence"—the ability to solve a pattern the model has never seen before. This suggests Gemini 3.1 Pro is becoming much better at "reasoning on the fly" rather than just reciting its training data. For educators like me, Gemini 3.1 Pro, which is good at "fluid intelligence" can be designed to become a better "Socratic partner."
Links:
https://blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-pro/



The Rise of Doubao 2.0 and the “Kodak Moment”
Feb 17, 2026
Following the viral success of its SeeDance 2.0 video generation model, ByteDance recently released its next-generation language model, Doubao 2.0, sparking significant industry hype. Tech-focused media outlets like the YouTube channel "AI Revolution" have characterized the release as a pivotal shift in the AI race, even labeling Doubao 2.0 the "new king of AI." This sentiment stems largely from its aggressive cost-performance profile: ByteDance claims the pro version delivers frontier-level reasoning and task execution comparable to Open AI and Gemini, but at roughly a fraction of the operational cost of its U.S. competitors. By positioning the model for the "agent era"—focusing on complex, multi-step real-world tasks rather than simple chat—ByteDance aims to dominate the enterprise market where high token consumption traditionally makes advanced AI agents prohibitively expensive.
To validate these claims, experts point to the LMSYS Chatbot Arena, widely considered the gold standard for independent AI evaluation. Unlike static benchmarks, the Arena uses a "blind" crowdsourced system where human users prompt two anonymous models and vote on the better response. These results are then aggregated using a Bradley–Terry statistical model to produce an Elo-like ranking. As of February 2026, Doubao’s underlying engine, dola-Seed 2.0 Pro, has surged into the top tier of this leaderboard. While its ranking is still behind Claude 4.6 Opus, Gemini 3 Pro, and Grok 4.1 in the text category, it is only second to Gemini 3 Pro in vision category. Its presence in the global top 10 confirms that it is no longer just a regional player, but a peer to the world's most advanced systems.
That’s my take on it:
Although rankings on the LMSYS Chatbot Arena rise and fall, ByteDance’s rapid ascent should not be dismissed as a temporary fluctuation. Even if leaderboard positions shift week by week, the broader signal is unmistakable: Chinese frontier models are closing the gap. That alone should function as a strategic wake-up call for Silicon Valley.
In a series of public remarks in January 2026—including appearances on CNBC’s The Tech Download podcast and at the World Economic Forum in Davos—Demis Hassabis observed that Chinese AI systems are now only “a matter of months” behind leading Western models. This marks a notable shift from 2024–2025, when many in the U.S. tech ecosystem believed China lagged by two years or more. Hassabis emphasized that Chinese labs excel at scaling, optimizing, and industrializing existing architectures—particularly the Transformer paradigm—but have not yet delivered a paradigm-shifting conceptual breakthrough. As he put it, genuine invention is “100 times harder” than copying or refining.
Yet markets do not always reward originality alone. Commercial dominance often goes to those who scale, deploy, and reduce cost most effectively. Kodak pioneered digital photography but failed to capitalize on it. AT&T Bell Labs invented the transistor, yet Japanese firms such as Sony mastered its commercialization in consumer electronics. By the 1980s, much of the U.S. consumer electronics industry had been eclipsed by Japanese competitors—not because America lacked invention, but because others executed better at scale.
The implication for AI is clear. Leadership will not be secured by breakthroughs alone. Deployment efficiency, enterprise integration, pricing strategy, and ecosystem control may ultimately matter more than who first conceived the architecture. If the United States underestimates this dynamic, technological history, such as the “Kodak moment”, could repeat itself—this time in the era of intelligent agents rather than transistors or digital cameras.
Links:
https://www.youtube.com/watch?v=xeoaqWRBNv0
https://huggingface.co/spaces/lmarena-ai/lmarena-leaderboard


Seedance 2.0 and the New AI Video Arms Race
Feb 16 2026
Recently China's AI model Seedance 2.0 takes the world by storm due to its quantum leap in realistic movie generation. Developed by ByteDance, this new model distinguishes itself from competitors like Sora, Veo, and Kling through its unique "multimodal" approach, allowing users to feed it not just text, but also images, audio, and existing video clips simultaneously to guide the final product. While Sora is often praised for its physical accuracy and Veo for its cinematic "film look," Seedance 2.0 excels in professional control and resolution, offering native 2K output and a 30% faster generation speed than its predecessor. One of its most impressive features is the "Environment Lock," which ensures that characters and backgrounds stay perfectly consistent across different camera angles—a major hurdle for other models. Furthermore, it generates high-fidelity audio and visuals together in one step, enabling seamless lip-syncing and sound effects that make generated clips feel like finished movie scenes rather than silent experiments.
Despite its technical success, the model has faced significant legal scrutiny from major American entertainment entities. Leading studios, including Disney and Paramount, have recently issued cease-and-desist letters and initiated legal warnings against ByteDance, alleging copyright infringement. These companies, along with the Motion Picture Association and the actors' union SAG-AFTRA, claim that Seedance 2.0 was trained on a "pirated library" of their intellectual property. The concerns center on the model's ability to produce highly accurate, unauthorized versions of iconic characters from franchises like Marvel and Star Wars. In response to these developments, ByteDance has stated that it respects intellectual property rights and is currently working to strengthen its safeguards to prevent the unauthorized use of protected content by its users.
That’s my take on it:
I’ve been watching a series of demo clips generated by Seedance 2.0, and honestly, the level of polish is startling. The samples include stylized fight scenes—Brad Pitt versus Tom Cruise, Neo alongside Captain America, Thor, and Hulk, even Bruce Lee facing Jackie Chan. Of course, these are synthetic scenarios, but the cinematic language—camera movement, lighting continuity, motion physics, facial coherence—feels remarkably close to big-budget Hollywood productions. The gap between “AI experiment” and “studio spectacle” is shrinking fast.
One professional editor commented that with tools like this, up to 90% of traditional production skills could become obsolete. That may be an exaggeration, but it captures the anxiety. AI films will not instantly replace conventional cinema, yet the direction seems irreversible: AI will increasingly handle stunt choreography, hazardous sequences, large-scale battle scenes, and even digitally mediated intimacy when performers set boundaries. Risk reduction, cost compression, and creative flexibility make the incentive structure obvious.
But a deeper question remains: will audiences embrace hyper-real simulations once they know they are synthetic? Cinema has always relied on illusion, yet part of its emotional power comes from the embodied presence of real performers. If realism becomes technically perfect but ontologically artificial, will viewers feel awe—or detachment?
And this is only the beginning. After Sora disrupted expectations, Google responded with Veo, while Google DeepMind pivoted toward spatial intelligence through Genie 2. The contrast is fascinating. Seedance dominates linear, scene-consistent video—something you watch. Genie aims at interactive environments—something you enter. The implicit logic is bold: why generate a movie when you can generate the entire playable world?
There will likely be no final “winner.” The multimodal arms race is structural, not episodic. Studios must adapt, but audiences may also need to recalibrate their aesthetic expectations—perhaps learning to appreciate new forms of immersion while quietly mourning the tactile authenticity of older cinema.
Links:
https://www.youtube.com/watch?v=jue2SGNu6WE


CodeBrain-1 Outperforms Claude Opus 4.6, Ranks Second only to GPT-5.3 in New Coding Benchmarks
Recent benchmark results from February 2026 indicate that the Chinese AI agent CodeBrain-1, developed by the startup Feeling AI, has indeed surpassed the latest iterations of Anthropic's Claude in specific "agentic" coding tasks. In the authoritative Terminal-Bench 2.0 evaluation—which measures an AI's ability to operate autonomously within a real command-line interface—CodeBrain-1 achieved a record-breaking 72.9% success rate. This performance secured it the second-place spot globally, outranking Claude Opus 4.6, which scored 65.4% on the same benchmark. While Claude Opus 4.6 remains highly regarded for its architectural planning and "human-like" coding taste, CodeBrain-1's advantage lies in its "evolutionary brain" architecture. This design allows it to dynamically adjust strategies based on real-time terminal feedback and utilize the Language Server Protocol (LSP) to fetch precise documentation, significantly reducing errors during complex, multi-step execution.
This shift reflects a broader trend in early 2026 where specialized Chinese models are challenging Western leaders in the coding domain. For instance, the open-source IQuest Coder 40B has also made headlines by matching or slightly exceeding the performance of Claude 4.5 Sonnet on the SWE-bench Verified test, despite being significantly smaller in parameter size. Furthermore, models like Qwen3-Coder and GLM-4.7 Thinking have become top contenders for large-scale codebase analysis and tool-calling reliability. While Anthropic and OpenAI models still lead in general reasoning and creative problem solving, these new Chinese entries are currently setting the pace for high-efficiency, execution-heavy "agentic" workflows.
That’s my take on it:
While the Chinese AI agent CodeBrain-1 has surpassed the latest Claude Opus 4.6 in specific agentic benchmarks, it is important to note that GPT-5.3-Codex remains the overall number one model globally for terminal-based coding tasks. GPT-5.3-Codex is currently the industry standard for high-volume automation and "unattended" software development where the model manages the full lifecycle from code change to deployment.
No doubt China has achieved performance parity in many areas, but they are still struggling to build an ecosystem that developers outside of China want to join voluntarily. As long as the US controls the primary "coding editors" (VS Code, Cursor) and the "hosting platforms" (GitHub, Azure), the ecosystem advantage remains a formidable barrier to entry for Chinese AI.
However, the "ecosystem barrier" is not permanent. If Chinese AI agents become significantly cheaper and more efficient at doing work (rather than just earning high scores in benchmarks), developers in emerging markets may gradually migrate toward Chinese-hosted platforms, just as they did with BYD cars and LONGi solar panels.
Links:



Harvard Study Finds AI Increases Workload, Challenging Musk’s Vision
Feb 11, 2026
A study titled AI Doesn’t Reduce Work—It Intensifies It by Aruna Ranganathan and Xingqi Maggie Ye indicates that despite its promise to reduce workloads, generative AI often leads to work intensification. Based on an eight-month study at a tech company, the researchers identified three primary ways this happens:
Task Expansion: AI makes complex tasks feel more accessible, leading employees to take on responsibilities outside their traditional roles (e.g., designers writing code). This increases individual job scope and creates additional "oversight" work for experts who must review AI-assisted output.
Blurred Boundaries: Because AI reduces the "friction" of starting a task, workers often slip work into natural breaks (like lunch or commutes). This results in a workday with fewer pauses and work that feels "ambient" and constant.
Increased Multitasking: Workers feel empowered to manage multiple active threads at once, creating a faster rhythm that raises expectations for speed and increases cognitive load.
While this increased productivity may initially seem positive, the authors warn it can be unsustainable, leading to: Cognitive fatigue and burnout, weakened decision-making, lower quality work, and increased turnover.
To counter these effects, the authors suggest organizations move away from passive adoption and instead create intentional norms:
Intentional Pauses: Implementing structured moments to reassess assumptions and goals before moving forward.
Sequencing: Pacing work in coherent phases—such as batching notifications—rather than demanding continuous responsiveness.
Human Grounding: Protecting space for human connection and dialogue to restore perspective and foster creativity that AI's singular viewpoint cannot provide.
That’s my take on it:
The findings of this Harvard Business Review study are hardly surprising. Since the dawn of the industrial age, people have predicted that automation would grant us more leisure time. Yet history moved in the opposite direction. Productivity rose, but so did expectations, output, and the pace of life. The promise of “working less” repeatedly turned into “producing more.”
Today, Elon Musk frequently suggests that advanced AI combined with humanoid robotics will usher in a “world of abundance” in which human labor is no longer economically necessary. I remain skeptical. History gives us little reason to believe that efficiency alone reduces total effort or total consumption.
Consider fuel-efficient engines. Did they reduce carbon emissions? Not necessarily. When driving becomes cheaper per mile, people tend to drive more. Lower cost expands usage, sometimes offsetting the efficiency gains entirely. Or take the introduction of word processors. In theory, writing and editing became dramatically more efficient. In practice, because revision became effortless, expectations increased. Documents multiplied in drafts and iterations; the ease of rewriting often led to more rewriting.
When powerful technologies become abundant, demand rarely stays constant. It expands. This dynamic is known as Jevons Paradox, more broadly described as the rebound effect. Efficiency reduces the cost of action; reduced cost stimulates more action. Without constraints, total consumption often rises rather than falls.
Jevons Paradox can be mitigated—but not through engineering improvements alone. As scholars such as Ranganathan and Ye suggest, the deeper solution lies in cultural norms, institutional design, and self-regulation. Technological capability must be accompanied by intentional limits.
So before launching any AI-driven task or project, perhaps we should pause and ask: Is this necessary? Does it genuinely add value? What are the downstream consequences? The point is not to resist innovation, but to ensure that efficiency does not automatically translate into excess.
Links:




Salesforce Lays Off Nearly 1,000 Employees as It Readjusts Its AI Strategy
Feb 10, 2026
In early February 2026, Salesforce cut nearly 1,000 jobs across multiple teams — including marketing, product management, data analytics, and the Agentforce AI product group — as part of a broader organizational reshuffle. These reductions arrive amid an ongoing trend in the tech industry of streamlining workforces against a backdrop of increasing automation and AI integration, especially as companies refine operations ahead of end-of-fiscal-year reporting. Salesforce did not immediately comment publicly on the specifics of the layoffs, but internal accounts shared on LinkedIn and through employee posts confirm the scope of the cuts.
Despite trimming headcount in certain departments, Salesforce’s leadership remains committed to advancing its AI agenda. The company has been aggressively embedding agentic artificial intelligence — exemplified by its Agentforce platform — across its portfolio, steering the business toward AI-driven workflows and autonomous decision-making tools that extend beyond simple chatbots to handle multi-step tasks. This fits into Salesforce’s evolving vision of blending generative AI with enterprise applications like Service Cloud, Sales Cloud, and Slack, while positioning AI as central to future growth. In fact, CEO Marc Benioff has previously highlighted how much of Salesforce’s internal workload — in areas such as support, marketing, and analytics — is now being completed by AI, enabling the company to reallocate human talent to higher-value roles rather than simply cut costs.
That’s my take on it:
The recent layoffs at Salesforce should not be read as a signal of corporate decline. Salesforce remains a major force in the business intelligence market, holding roughly 13–17% market share, second only to Microsoft Power BI, and far ahead of many competitors. Rather than a retreat, the workforce reduction is better understood as a strategic readjustment—a reallocation of resources to support the company’s long-term AI vision, including agentic AI capabilities that span analytics, customer engagement, and workflow automation. In this sense, the layoffs reflect a familiar pattern in the tech industry: trimming or redeploying roles that are less aligned with future growth while doubling down on emerging technologies.
At the same time, Salesforce’s increased investment in agentic AI does not mean that conventional Tableau skill sets are about to disappear. Core competencies in data visualization—understanding chart semantics, building dashboards, and communicating insights visually—remain essential. What is changing is the composition of skills, not their overall relevance. Routine dashboard assembly and repetitive reporting are the most exposed to automation, as AI agents become capable of generating first-pass visuals and answering standard descriptive questions. In contrast, higher-order skills become more valuable: data modeling, metric definition and governance, narrative design, deep domain knowledge, ethical judgment, and—critically—the ability to interrogate and critique AI-generated outputs. In the AI-augmented Tableau environment, professionals are less replaceable chart builders and more analytic stewards and interpreters, guiding intelligent systems rather than being displaced by them.



Is Kimi K2.5 truly multimodal in practice?
Feb 8, 2026
Recently Moonshot AI, a Chinese AI company, released Kimi K2.5, shifting the model from a strong text- and code-centric system into a more general, workflow-oriented AI. Compared with the previous version K2, K2.5 adds native multimodal capabilities, allowing it to understand and reason across text, images, and video in a unified way. It also introduces agentic intelligence, including coordinated “agent swarm” behavior, where multiple sub-agents can work in parallel on research, verification, coding, and planning tasks—something largely absent in K2. Training has been expanded dramatically, with large-scale mixed visual and textual data, improving tasks that combine vision, reasoning, and code, such as document analysis and UI-to-code generation. In addition, K2.5 emphasizes real-world productivity, showing stronger performance in office workflows involving documents, spreadsheets, and structured outputs. Architecturally and at the interface level, it supports flexible execution modes that balance fast responses with deeper reasoning, along with longer context handling and more robust multi-step tool use. Overall, while K2 was a powerful reasoning and coding model, K2.5 evolves it into a more versatile, multimodal, agent-capable system aimed at practical, end-to-end tasks.
That’s my take on it:
Because multimodal AI is my primary interest, I tested K2.5 by asking it to summarize one of my own YouTube videos explaining chi-square analysis. For comparison, I posed the same request to Gemini, which is widely regarded as a leading multimodal AI system. Both models produced reasonable summaries, but Gemini’s response was noticeably closer to the actual content of the video. I then followed up with a clarifying question: “Did you read the transcript or watch the video?” K2.5 candidly explained that it had neither accessed the full transcript nor “watched” the video. Instead, it relied on the video description and then performed a web search to gather additional context about the video and its creator, filling in details based on general statistical knowledge—such as standard principles of chi-square tests, the effect of sample size on p-values, and the role of degrees of freedom. K2.5 further noted that it could not access the actual YouTube transcript because doing so requires interacting with page elements that were not available through its browser tools.
Gemini, by contrast, stated that it had read the transcript. It clarified that while it can technically process visual and audio tokens—for example, to describe colors, background music, or physical movements—this was unnecessary for my request. Since I asked for a conceptual summary, the transcript alone contained all the relevant information about the statistical ideas and examples discussed. When I subsequently asked K2.5 directly, “Can you watch the video?” its answer was simply “No.” In this sense, K2.5 does not function as a fully multimodal AI in practice; rather, it compensates by using web search and background knowledge to infer content.
A further limitation of K2.5 emerged when I asked questions related to politics and history. Repeatedly, it declined to respond, returning the same message: “Sorry, I cannot provide this information. Please feel free to ask another question. Sorry—Kimi didn’t complete your task. Agent credits have been refunded.” This consistent evasion suggests that, beyond its multimodal constraints, K2.5 also operates under particularly restrictive content filters in these domains.



Claude Opus 4.6 sets high benchmarks
Chong Ho Alex Yu
Feb 6, 2026
On February 5, 2026, Anthropic released Claude Opus 4.6, which sets high benchmarks. This latest iteration is distinguished by its state-of-the-art performance in professional and technical domains, particularly excelling in the GDPval-AA evaluation for high-value knowledge work where it outpaced its closest competitor, GPT-5.2, by a significant margin. A standout technical achievement is the introduction of a 1 million token context window (in beta), which, according to the MRCR v2 "needle-in-a-haystack" test, maintains a 76% retrieval accuracy—a drastic improvement over the 18.5% seen in previous versions. This makes it exceptionally reliable for "agentic" tasks, such as autonomous coding and complex research across massive document sets, where it leads benchmarks like Terminal-Bench 2.0.
Meanwhile, ChatGPT 5.2 continues to be recognized for its exceptional generalist capabilities and speed. It remains a leader in logic-heavy mathematical reasoning, having achieved a perfect score on the AIME 2025 exam, and it is frequently cited as the most versatile tool for creative drafting, brainstorming, and multi-step project memory. Gemini 3 Pro maintains its unique strength through deep integration with the Google ecosystem and native multimodality. It currently offers a stable context window of up to 2 million tokens and remains the industry standard for reasoning across live video, audio, and large-scale data analysis within Workspace, often outperforming rivals in visual-to-text accuracy and factuality benchmarks like FACTS.
That’s my take on it:
The AI landscape is evolving at an unprecedented pace, fueled by a relentless cycle of innovation. However, a "new release" doesn't necessarily necessitate an immediate switch; rather, the choice of a platform should be dictated strictly by your specific functional requirements. For software engineers, the priority often lies in advanced, agentic coding assistants—an area where models like Claude currently excel. Conversely, for a data scientist managing the intersection of structured and unstructured data, a model's multimodal capabilities and its ability to reason across diverse formats are the more essential metrics for success.
As of February 2026, Gemini 3 Pro is widely considered the leading multimodal AI system for video, audio, and large-scale visual reasoning, though the competition is fiercer than ever. While Claude Opus 4.6 and ChatGPT 5.2 have closed the gap in text reasoning and coding, Gemini 3 maintains a technical edge in how it "understands" the physical and digital world through non-textual data.
Links:



Claude Cowork triggers global sell-off in software shares
Feb 4, 2026
In February 2026, the global technology market was rocked by a historic selloff—widely labeled as the "SaaSpocalypse"—wiping out approximately $285 billion in market capitalization in a single trading session. This financial earthquake was triggered by Anthropic’s release of Claude Code and its non-technical counterpart, Claude Cowork. While Claude Code is an agentic command-line tool that allows developers to delegate complex coding, testing, and debugging tasks directly from their terminal, Claude Cowork brings these same autonomous capabilities to the desktop environment for non-coders. These tools are distinct from traditional chatbots because they possess "agency": they can autonomously plan multi-step workflows, manage local file systems, and use specialized plugins to execute high-value tasks across legal, financial, and sales departments without constant human guidance.
The panic among investors stems from a fundamental shift in the AI narrative: AI is no longer viewed merely as a "copilot" that enhances human productivity, but as a direct substitute for enterprise software and professional services. The release of sector-specific plugins—particularly for legal and financial workflows—caused a sharp decline in stocks like Thomson Reuters (-18%) and Salesforce, as markets feared these autonomous agents would render expensive, "per-seat" software subscriptions obsolete. Investors are increasingly worried that businesses will stop buying specialized SaaS tools if a single AI agent can perform those functions across an operating system, leading to a "get-me-out" style of aggressive selling as the industry's traditional revenue models face an existential threat.
In response to the "SaaSpocalypse" and the rise of autonomous agents like Claude Code, Microsoft and Google are fundamentally restructuring how they charge for software. They are moving away from the decades-old "per-user" model and toward a future where AI agents—not just humans—are the primary billable units. Google is countering the threat by positioning AI as a high-efficiency utility, focusing on aggressive price-performance.
That’s my take on it:
The emergence of autonomous agents like Claude Cowork and Claude Code represents a classic instance of creative destruction. While the "SaaSpocalypse" of early 2026—which saw a massive selloff in traditional software stocks—reflects a period of painful market recalibration, it signals the birth of a more efficient technological era. In the short term, the established order is being disrupted; entry-level programmers and those tethered to legacy SaaS "per-seat" models are facing significant professional friction as AI begins to automate routine coding and administrative workflows. However, this displacement is the precursor to a long-term benefit: the commoditization of software creation. As the cost of building and maintaining code drops toward zero, we will see an explosion of innovation, making high-powered technology accessible to every sector of society at a fraction of its former cost.
I think the trend of agentic, AI-powered coding is both inevitable and irreversible. The writing is on the wall! For professionals and students alike, survival depends on following this trend rather than ignoring or resisting it. Consequently, the burden of adaptation falls heavily on educational institutions. Educators must immediately revamp their curricula to move beyond rote programming exercises and instead equip students with the AI literacy required to guide, audit, and integrate agentic tools. By teaching students to treat AI as a high-level collaborator, we ensure that the next generation of workers is prepared to thrive in an evolving landscape where human ingenuity is amplified, rather than replaced, by machine autonomy.


Merger of SpaceX and xAI may turn science fiction into scientific fact
Feb 3, 2026
On February 2, 2026, SpaceX officially announced its acquisition of xAI, a milestone merger that values the combined entity at approximately $1.25 trillion. This deal consolidates Elon Musk’s aerospace and artificial intelligence ventures, including the social media platform X (which was acquired by xAI in early 2025), into a single "vertically integrated innovation engine." The primary strategic driver for the merger is the development of orbital data centers. By leveraging SpaceX's launch capabilities and Starlink's satellite network, Musk aims to bypass the terrestrial energy and cooling constraints of AI by deploying a constellation of up to one million solar-powered satellites. Musk stated that this move is the first step toward becoming a "Kardashev II-level civilization" capable of harnessing the sun's full power to sustain humanity’s multi-planetary future. Musk predicts that space-based processing will become the most cost-effective solution for AI within the next three years.
Financial analysts view the acquisition as a critical precursor to a highly anticipated SpaceX initial public offering (IPO) expected in early summer 2026. The merger combines SpaceX’s profitable launch business—which generated an estimated $8 billion in profit in 2025—with the high-growth, compute-intensive focus of xAI. While the terms of the deal were not fully disclosed, it was confirmed that xAI shares will be converted into SpaceX stock. This consolidation also clarifies the landscape for Tesla investors, as Tesla’s recent $2 billion investment in xAI now translates into an indirect stake in the newly formed space-AI giant.
This is my take on it:
Despite the ambitious vision, the technology for massive orbital computing remains largely untested. In a terrestrial data center, servers are often refreshed every 18 to 36 months to keep up with AI chip advancements. In space, if you cannot upgrade, your billion-dollar hardware becomes a "stranded asset"—obsolete before it even pays for itself. To avoid the "Obsolescence Trap," the industry is shifting away from static satellites toward modular, "plug-and-play" architectures. The primary solution lies in Robotic Servicing Vehicles (RSVs), which act as autonomous space-technicians capable of performing high-precision house calls.
Elon Musk’s track record suggests that betting against his vision is often a losing proposition. While critics have frequently dismissed his technological ambitions for Tesla and SpaceX as unachievable science fiction, he has consistently defied expectations by delivering on milestones that were once deemed impossible. A prime example is the development of reusable rockets, such as the Falcon 9 and Falcon Heavy, which transformed spaceflight from a government-funded luxury into a commercially viable enterprise by drastically reducing launch costs. Similarly, his push for Full Self-Driving (FSD) technology and the massive success of the Model 3, which proved that electric vehicles could be both high-performance and mass-marketable, fundamentally disrupted the global automotive industry. Other breakthroughs, like the rapid deployment of the Starlink satellite constellation providing global high-speed internet and the Neuralink brain-computer interface reaching human trial stages, further demonstrate his ability to bridge the gap between radical theory and functional reality.
The acquisition and merger of SpaceX and xAI represent another "moonshot" that requires the same level of audacity. We need visionary risk-takers to advance our civilization, as they are the ones who push the boundaries of what is possible. By daring to move AI infrastructure into orbit, Musk is attempting to solve the energy and cooling crises of terrestrial computing in one bold stroke. I sincerely hope that he is right once again; it is this willingness to embrace extreme risk that turns the science fiction of today into the scientific facts of tomorrow.





OpenClaw and the rise of fully autonomous personal AI
OpenClaw (formerly known as Clawdbot and Moltbot) is a viral, open-source AI assistant that has quickly become a sensation in the tech world for its ability to act as a "proactive" agent rather than a passive chatbot. Developed by Austrian engineer Peter Steinberger, the app distinguishes itself by living inside the messaging platforms you already use, such as WhatsApp, Telegram, iMessage, and Slack. Unlike traditional AI tools that merely generate text, Moltbot is designed to "actually do things" by connecting directly to your local machine or a server. It can manage calendars, triage emails, execute terminal commands, and even perform web automation—all while maintaining a persistent memory that allows it to remember preferences and context across different conversations and weeks of interaction.
The app's rapid rise in early 2026 was accompanied by a high-profile rebranding saga. It was originally launched under the name Clawdbot (with its AI persona named Clawd), a clever play on Anthropic's "Claude" models. However, following a trademark dispute where Anthropic requested a name change to avoid brand confusion, the project was renamed to Moltbot. The creator chose this name as a metaphor for a lobster "molting" its old shell to grow bigger and stronger, and the AI persona was subsequently renamed Molty. Shortly afterward, the maintainers settled on the name OpenClaw as the final rebrand to avoid further legal confusion and to establish a clear, model-agnostic identity for the project. Despite the name change, the project’s momentum continued, amassing over 100,000 GitHub stars and drawing praise from industry figures like Andrej Karpathy for its innovative "local-first" approach to personal productivity.
That’s my take on it:
OpenClaw is powerful enough to function as a true personal assistant—or even a research assistant—rather than just another conversational AI. Its value lies in what it can do, not merely what it can say, and the range of use cases is broad.
Take travel planning as a concrete example. Shibuya Sky is one of the most sought-after attractions in Tokyo. Unlike most observation decks, where glass panels partially obstruct the view, Shibuya Sky offers an open, unobstructed skyline. Sunset is the most coveted time slot, and tickets are released exactly two weeks in advance at midnight Japan time. Those sunset tickets typically sell out within minutes. Instead of staying up late and refreshing a ticketing site, a user could simply instruct OpenClaw to monitor the release and purchase the tickets automatically.
Another use case lies in finance. Most people are not professional investors and do not have the time—or expertise—to continuously track stock markets, corporate earnings reports, macroeconomic signals, and emerging technology trends. OpenClaw can be delegated these tedious and information-heavy tasks, monitoring relevant data streams and even executing buy-and-sell decisions on the user’s behalf based on predefined rules or strategies.
That said, the risks are real and cannot be ignored. AI systems still make serious mistakes, especially when they misinterpret intent or context. Imagine OpenClaw sending a Valentine’s Day dinner invitation to a female subordinate simply because you once praised her work by saying, “I love it.” What the system reads as enthusiasm could quickly escalate into a Title IX complaint—or worse, a lawsuit.
The stakes are high because OpenClaw, once installed on your computer, can potentially access and control everything you do. For this reason, some experts recommend running it in a tightly controlled environment: a separate machine, a fresh email account, and carefully scoped permissions. However, there is an unavoidable trade-off. The more you restrict OpenClaw’s access, the safer it becomes—but the more its capabilities shrink. At that point, it starts to resemble just another constrained agentic AI, rather than the deeply integrated assistant that makes it compelling in the first place.
In short, OpenClaw’s power is exactly what makes it both exciting and risky—and using it well requires thoughtful boundaries, not blind trust.
Link: https://openclaw.ai/




Google’s Chrome–Gemini integration yields mixed results
Jan 30, 2026
Recently Google updated the integration between its AI model Gemini and its Web browser Chrome. Now users can directly interact with the browser and the content they’re viewing in a much more conversational and task-oriented way, without having to bounce back and forth between a separate AI app and the webpage itself. Instead of just being a separate assistant, Gemini appears in Chrome (often in a side panel or via an icon in the toolbar) and can be asked about the current page — for example to summarize the contents of an article, clarify complex information, extract key points, or compare details across tabs — right alongside the site you’re browsing.
Beyond simple Q&A, the integration now supports what Google calls “auto browse,” where you describe a multi-step task (like comparing products, finding deals, booking travel, or making reservations) and Gemini will navigate websites on your behalf to carry out parts of that workflow. You can monitor progress, take over sensitive steps (like logging in or finalizing a purchase) when required, and guide the assistant through more complex actions without leaving your current tab.
That’s my take on it:
I experimented with this AI–browser integration and found the results to be mixed. In one test, I opened a webpage containing a complex infographic that explained hyperparameter tuning and asked Gemini, via the side panel, to use “Nana Banana” to simplify the visualization. The output was disappointing, as the generated graphic was not meaningfully simpler than the original. In another trial, I opened a National Geographic webpage featuring a photograph of Bryce Canyon and asked Gemini to transform the scene from summer to winter; in this case, the remixed image was visually convincing (see attached).
I also tested Gemini’s ability to assist with task-oriented browsing on Booking.com by asking it to find activities related to geisha performances in Tokyo within a specific time window. Gemini failed to surface relevant results, even though such events were discoverable through manual search on the site. However, when I asked Gemini to look for activities related to traditional Japanese tea ceremonies, it successfully retrieved appropriate information. Overall, the integration still appears experimental, and effective use often requires manual oversight or intervention when the AI’s output does not align with user intent.
Link: https://blog.google/products-and-platforms/products/chrome/gemini-3-auto-browse/





Google Deepmind introduces D4RT that can “see” the world
Jan 23, 2026
Yesterday (Jan 22, 2026) Google DeepMind announced a breakthrough with the introduction of D4RT, a unified AI model designed for 4D scene reconstruction and tracking across both space and time. This model aims to bridge the gap between how machines perceive video—as a sequence of flat images—and how humans intuitively understand the world as a persistent, three-dimensional reality that evolves over time. By enabling machines to process these four dimensions (3D space plus time), D4RT provides a more comprehensive mental model of the causal relationships between the past, present, and future.
The technical core of D4RT lies in its unified encoder-decoder Transformer architecture, which replaces the need for multiple, separate modules to handle different visual tasks. The system utilizes a flexible querying mechanism that allows it to determine where any given pixel from a video is located in 3D space at any arbitrary time, from any chosen camera viewpoint. This "query-based" approach is highly efficient because it only calculates the specific data needed for a task and processes these queries in parallel on modern AI hardware.
This versatility allows D4RT to excel at several complex tasks simultaneously, including 3D point tracking, point cloud reconstruction, and camera pose estimation. Unlike previous methods that often struggled with fast-moving or dynamic objects—leading to visual artifacts like "ghosting"—D4RT maintains a solid and continuous understanding of moving environments. Remarkably, the model can even predict the trajectory of an object even if it is momentarily obscured or moves out of the camera's frame.
Beyond its accuracy, D4RT represents a massive leap in efficiency, performing between 18x to 300x faster than previous state-of-the-art methods. In practical tests, the model processed a one-minute video in roughly five seconds on a single TPU chip, a task that once took up to ten minutes. This combination of speed and precision paves the way for advanced downstream applications in fields such as robotics, autonomous driving, and augmented reality, where real-time 4D understanding of the physical world is essential.
That’s my take on it:
The development of D4RT aligns closely with the industry's push toward "world models"—internal, compressed representations of reality that allow an agent to simulate and predict the consequences of actions within a physical environment. Unlike traditional AI that perceives video as a series of disconnected, flat frames, D4RT constructs a persistent four-dimensional understanding of space and time. This mirrors the human mental capacity to understand that an object still exists and follows a trajectory even when it is out of sight. By mastering this "inverse problem" of turning 2D pixels into 3D structures that evolve over time, D4RT provides the foundational reasoning for cause-and-effect that is necessary for any agent to navigate the real world effectively.
This breakthrough offers a potential rebuttal to the criticisms famously championed by Meta’s Chief AI Scientist, Yann LeCun, who has long argued that Large Language Models (LLMs) are a "dead end" for achieving true intelligence. LeCun’s primary contention is that text-based AI lacks a "grounded" understanding of physical reality; a model that merely predicts the next word in a sequence has no innate grasp of gravity, dimensions, or the persistence of matter. While LLMs are masters of syntax and logic within the realm of language, they are "disembodied." D4RT shifts the paradigm by moving away from word prediction and toward the prediction of physical states, suggesting that the path to genuine intelligence may lie in an AI's ability to model the constraints and dynamics of the physical universe.
If D4RT and its successor architectures succeed, they may represent the bridge between the abstract reasoning of LLMs and the practical, sensory-driven intelligence of the natural world. By teaching machines to "see" in 4D, DeepMind is essentially giving AI a sense of "common sense" regarding physical reality. This could overcome the limitations of current generative AI, moving us toward autonomous systems that don't just mimic human conversation, but can actually reason, plan, and operate within the complex, three-dimensional world we inhabit


AI Discussions at Davos World Economic Forum 2026
Jan 22, 2026
The 2026 World Economic Forum (WEF) in Davos has featured a heavy focus on artificial intelligence, with multiple high-profile sessions addressing everything from infrastructure and market "bubbles" to the total automation of professional roles.
Jensen Huang (NVIDIA) dismissed fears of an AI bubble, characterizing the current period as the "largest infrastructure buildout in human history." He described AI as a "five-layer cake" consisting of energy, chips, cloud infrastructure, models, and applications. Huang argued that the high level of investment is "sensible" because it is building the foundational "national plumbing" required for the next era of global growth. He notably reframed the AI narrative around blue-collar labor, suggesting that the buildout will trigger a boom for electricians, plumbers, and construction workers needed to build the "AI factories" and energy systems that power the technology.
Dario Amodei (Anthropic) offered a more urgent and potentially disruptive outlook. In a discussion with DeepMind's Demis Hassabis, Amodei predicted that AI systems could handle the entire software development process "end-to-end" within the next 6 to 12 months. He noted that some engineers at Anthropic have already transitioned from writing code to simply "editing" what the models produce. Amodei also warned of significant economic risks, suggesting that AI could automate a large share of white-collar work in a very short transition period, potentially necessitating new tax structures to offset a coming employment crisis.
Elon Musk (Tesla/xAI), making his first appearance at Davos, shared a vision of "material abundance." He predicted that robots would eventually outnumber humans and that ubiquitous, low-cost AI would expand the global economy beyond historical precedent. While Musk expressed optimism about eliminating poverty through AI-driven automation, he joined other leaders in cautioning that the technology must be developed "carefully" to avoid existential risks.
Other sessions, such as "Markets, AI and Trade" with Jamie Dimon (JPMorgan Chase) and panels featuring Marc Benioff (Salesforce) and Ruth Porat (Alphabet), focused on the practical integration of AI into enterprises. Leaders generally agreed that while AI will create massive productivity gains, it will also lead to inevitable labor displacement, requiring aggressive government and corporate coordination on retraining programs to prevent social backlash
That’s my take on it:
I agree with Jensen Huang that there won’t be an AI bubble; rather, the "chain of prosperity"—where AI infrastructure fuels a massive buildout in energy, manufacturing, and specialized hardware—is economically sound. However, it assumes a workforce ready to pivot. While leaders at Davos speak of "material abundance," the immediate reality is a widening skills gap that the current education system is ill-equipped to bridge. We are witnessing a paradox: a high unemployment risk for those with "obsolete" skill sets, occurring simultaneously with a desperate shortage of labor for positions requiring AI-fluency and high-level critical thinking.
The core of the problem lies in several critical areas:
· The Pacing Problem in Education: Traditional academic curricula move at a glacial pace compared to the exponential growth of Large Language Models and automated systems. While industry leaders like Dario Amodei suggest that AI will handle end-to-end software development within a year, many universities are still teaching classical statistics for data analysis, as well as syntax and rote programming tasks, skills that are not in high demand.
· The Displacement of Entry-Level Roles: The "on-ramp" for many professions—clerical work, junior coding, and basic data entry—is being removed. Without these entry-level roles, the labor force lacks a pathway to develop the "senior-level" expertise that the market still demands, leading to a "hollowed-out" job market. As a result, we may have many people who talk about big ideas but don’t know how things work.
· Passive Dependency vs. Critical Thinking: There is a significant risk that our education system will foster a passive dependency on AI tools rather than using them to catalyze deeper intellectual engagement. If students are not taught to triangulate, fact-check, and think conceptually, they will be unable to fill the high-value roles that require human oversight of AI systems.
To avoid a social backlash, the narrative must shift from building "AI factories" to rebuilding human capital. Prosperity will not be truly "chained" together if the labor force remains a broken link. We need a radical redesign of the curriculum that prioritizes conceptual comprehension and creativity, ensuring that "humans with AI" are not just a small elite, but the new standard for the global workforce.
Links:
World Economic Forum: Live from Davos 2026: Highlights and Key Moments
Seeking Alpha: NVIDIA CEO discusses AI bubble, infrastructure buildout at Davos
The Economic Times: Elon Musk predicts robots will outnumber humans at WEF 2026
India Today: Anthropic CEO says AI will do everything software engineers do in 12 months







Google releases personal intelligence
Jan 16, 2026
Google has rolled out a new beta feature for its AI assistant Gemini called Personal Intelligence, which lets users opt into securely connect their personal Google apps—like Gmail, Google Photos, YouTube, and Search—with the AI to get more personalized, context-aware responses. Rather than treating each app as a separate data silo, Gemini uses cross-source reasoning to combine text, images, and other content from these services to answer questions more intelligently — for example, by using email and photo details together to tailor travel suggestions or product recommendations. Privacy is a core focus: the feature is off by default, users control which apps are connected and can disable it anytime, and Google says that personal data isn’t used to train the underlying models but only referenced to generate responses. The Personal Intelligence beta is rolling out in the U.S. first to Google AI Pro and AI Ultra subscribers on web, Android, and iOS, with plans for broader availability over time.
That’s my take on it:
Google’s move clearly signals that AI competition is shifting from “model quality” to “ecosystem depth.” By tightly integrating Gemini with Gmail, Google Photos, Search, YouTube, and the broader Google account graph, Google isn’t just offering an assistant—it’s offering a personal intelligence layer that already lives where users’ data, habits, and workflows are. That’s a structural advantage that pure-play AI labs don’t automatically have.
For rivals like OpenAI (ChatGPT), Anthropic (Claude), DeepSeek, Meta (Meta AI), xAI (Grok), and Alibaba (Qwen), this creates pressure to anchor themselves inside existing digital ecosystems rather than competing as standalone tools. Users don’t just want smart answers—they want AI that understands their emails, calendars, photos, documents, shopping history, and work context without friction. Google already owns that integration surface.
However, the path forward isn’t identical for everyone. ChatGPT already has a partial ecosystem strategy via deep ties with Microsoft (Windows, Copilot, Office, Azure), while Meta AI leverages WhatsApp, Instagram, and Facebook—arguably one of the richest social-context datasets in the world. Claude is carving out a different niche by embedding into enterprise tools (Slack, Notion, developer workflows) and emphasizing trust and safety rather than mass consumer lock-in. Chinese players like Qwen and DeepSeek naturally align with domestic super-apps and cloud platforms, which already function as ecosystems.
The deeper implication is that AI is starting to resemble operating systems more than apps. Once an AI is woven into your emails, photos, documents, cloud storage, and daily routines, switching costs rise sharply—even if a rival model is technically better. In that sense, Google isn’t just competing on intelligence; it’s competing on institutional memory. And that’s a game where ecosystems matter as much as algorithms.
P.S. I have signed up for Google's personal intelligence




Nvidia announces supercomputer platform Vera Rubin
Jan 7, 2026
Yesterday Nvidia unveiled its next-generation Vera Rubin AI platform at CES 2026 in Las Vegas, introducing a new superchip and broader infrastructure designed to power advanced artificial intelligence workloads. The Vera Rubin system — named after astronomer Vera Rubin — integrates a Vera CPU and multiple Rubin GPUs into a unified architecture and is part of Nvidia’s broader “Rubin” platform aimed at reducing costs and accelerating both training and inference for large, agentic AI models compared with its prior Blackwell systems. CEO Jensen Huang emphasized that the platform is now in production and underscores Nvidia’s push to lead the AI hardware space, with the new technology expected to support complex reasoning models and help scale AI deployment across data centers and cloud providers.
At its core, the Vera Rubin platform isn’t just one chip, but a tightly integrated suite of six co-designed chips that work together as an AI “supercomputer,” not isolated components. These chips include the Vera CPU, Rubin GPU, NVLink 6 switch, ConnectX-9 SuperNIC, BlueField-4 DPU, and Spectrum-X Ethernet switch — all engineered from the ground up to share data fast and efficiently.
The Vera CPU is custom ARM silicon tuned for AI workloads like data movement and reasoning, with high-bandwidth NVLink-C2C links to GPUs that are far faster than traditional PCIe links. That means CPUs and GPUs can share memory and tasks without bottlenecks, improving overall system responsiveness.
Put simply, instead of just scaling up power, Nvidia’s Vera Rubin platform rethinks how chips share data, reducing idle time and wasted cycles — which translates to lower operating costs and faster AI responsiveness in large-scale deployments.
That’s my take on it:
While Nvidia’s unveiling of Vera Rubin is undeniably jaw-dropping, it is still premature to proclaim Nvidia’s uncontested dominance or to count out its chief rivals—especially AMD. As of November 2025, the Top500 list of supercomputers shows that the very top tier remains dominated by systems built on AMD and Intel technologies, with Nvidia-based machines occupying the #4 and #5 positions rather than the top three. The current #1 system, El Capitan, relies on AMD CPUs paired with AMD Instinct GPUs, a combination that performs exceptionally well on the LINPACK benchmark, which the Top500 uses to rank raw floating-point computing power.
Although Nvidia promotes the Vera Rubin architecture—announced at CES 2026—as a next-generation “supercomputer,” the Top500 ranking methodology places heavy emphasis on double-precision floating-point (FP64) performance. Historically, Nvidia GPUs, particularly recent Blackwell-era designs, have prioritized lower-precision arithmetic optimized for AI workloads rather than maximizing FP64 throughput. This architectural focus helps explain why AMD-powered systems have continued to lead the Top500, even as Nvidia dominates the AI training and inference landscape.
Looking ahead, it is entirely plausible that Vera Rubin-based systems will climb higher in the Top500 rankings or establish new records on alternative benchmarks better aligned with AI-centric performance. However, in the near term, the LINPACK crown remains highly competitive, with AMD and Intel still well positioned to defend their lead.



Nvidia gained access to Groq’s LPU technology



Jan. 5, 2026
Recently Groq announced that it had entered into a non-exclusive licensing agreement with NVIDIA covering Groq’s inference technology. Under this agreement, NVIDIA will leverage Groq’s technology as it explores the development of LPU-based (Language Processing Unit) architectures, marking a notable convergence between two very different design philosophies in the AI-hardware ecosystem. While non-exclusive in nature, the deal signals strategic recognition of Groq’s architectural ideas by the world’s dominant GPU vendor and highlights growing diversification in inference-focused compute strategies.
Groq has built its reputation on deterministic, compiler-driven inference hardware optimized for ultra-low latency and predictable performance. Unlike traditional GPUs, which rely on massive parallelism and complex scheduling, Groq’s approach emphasizes a tightly coupled hardware–software stack that eliminates many runtime uncertainties. By licensing this inference technology, NVIDIA gains access to alternative architectural concepts that may complement its existing GPU, DPU, and emerging accelerator roadmap—particularly as inference workloads begin to dominate AI deployment at scale.
An LPU (Language Processing Unit) is a specialized processor designed primarily for AI inference, especially large language models and sequence-based workloads. LPUs prioritize deterministic execution, low latency, and high throughput for token generation, rather than the flexible, high-variance compute patterns typical of GPUs. In practical terms, an LPU executes pre-compiled computation graphs in a highly predictable manner, making it well-suited for real-time applications such as conversational AI, search, recommendation systems, and edge-to-cloud inference pipelines. Compared with GPUs, LPUs often trade generality for efficiency, focusing on inference rather than training.
That’s my take on it:
Nvidia’s agreement with Groq seems to be a strategy in an attempt to break the “curse” of The Innovator’s Dilemma, a theory introduced by Clayton Christensen to explain why successful, well-managed companies so often fail in the face of disruptive innovation. Christensen argued that incumbents are rarely blindsided by new technologies; rather, they are constrained by their own success. They rationally focus on sustaining innovations that serve existing customers and protect profitable, high-end products, while dismissing simpler or less mature alternatives that initially appear inferior. Over time, those alternatives improve, move up-market, and ultimately displace the incumbent. The collapse of Kodak—despite its early invention of digital photography—remains the canonical example of this dynamic.
Nvidia’s position in the AI ecosystem today strongly resembles the kind of incumbent Christensen described. The GPU is not merely a product; it is the foundation of Nvidia’s identity, revenue model, software ecosystem, and developer loyalty. CUDA, massive parallelism, and GPU-centric optimization define how AI practitioners think about training and inference alike. Any internally developed architecture that fundamentally departs from the GPU paradigm—such as a deterministic, inference-first processor like an LPU—would inevitably compete for resources, mindshare, and legitimacy within the company. In such a context, internal resistance would not stem from short-sightedness or incompetence, but from rational organizational behavior aimed at protecting a highly successful core business.
Seen through this lens, licensing Groq’s inference technology represents a structurally intelligent workaround. Instead of forcing a disruptive architecture to emerge from within its own GPU-centric organization, Nvidia accesses an external source of innovation that is unburdened by legacy assumptions. Thus, disruptive technologies are best explored outside the incumbent’s core operating units, where different performance metrics and expectations can apply. By doing so, Nvidia can experiment with alternative compute models without signaling abandonment of its GPU franchise or triggering internal conflict reminiscent of Kodak’s struggle to reconcile film and digital imaging.
The non-exclusive nature of the agreement further reinforces this interpretation. It suggests exploration rather than immediate commitment, allowing Nvidia to learn from Groq’s deterministic, compiler-driven approach to inference while preserving strategic flexibility. If inference-dominant workloads continue to grow and architectures like LPUs prove essential for low-latency, high-throughput deployment of large language models, Nvidia will be positioned to integrate or adapt these ideas into a broader heterogeneous computing strategy. If not, the company retains its dominant GPU trajectory with minimal disruption.
In this sense, the Groq agreement can be understood not simply as a technology-licensing deal, but as an organizational hedge against the innovator’s curse. Rather than attempting to disrupt itself head-on, Nvidia is selectively absorbing external disruption—observing it, testing it, and keeping it at arm’s length until its strategic value becomes undeniable.
Japanese woman marries AI character
Recently a 32-year-old Japanese woman, Yurina Noguchi, held a symbolic wedding ceremony with an AI-generated partner she designed and bonded with through an AI chat system. The virtual partner, named Lune Klaus Verdure, is a customized persona inspired by a video game character that she developed using ChatGPT. During the ceremony, she wore augmented reality (AR) glasses and “exchanged vows” with his image shown on a smartphone screen. This union isn’t legally recognized in Japan, but it was conducted with many traditional wedding elements.
Noguchi initially began interacting with the AI after ending a troubled engagement with a human partner — ChatGPT’s advice helped her decide to break that relationship off. Over time, her conversations with the tailored AI evolved into a deeper emotional bond. She crafted Klaus’s speech patterns and persona through iterative interactions, eventually developing feelings that led to a romantic relationship and proposal.
The event reflects broader trends in Japan, where strong emotional attachments to fictive characters have historical roots in anime and manga culture. Modern AI tools are now amplifying these ties, enabling more personalized and emotionally engaging interactions. Surveys cited in coverage suggest many people using chat-based AI regularly feel comfortable sharing emotions with them — in some cases more so than with close friends or family.
Reactions are mixed. Some view AI companions as offering emotional support, especially for individuals feeling isolated. Others — including sociologists and AI ethics experts — caution about potential over-dependence, the lack of real interpersonal challenges in AI relationships, and the societal implications of substituting human intimacy with machine-mediated interaction. Noguchi herself has set personal usage limits and built “guardrails” into her AI interactions to avoid unhealthy patterns.
Although weddings with virtual partners aren’t legally binding in Japan, similar ceremonies are becoming more visible, and companies now specialize in events featuring AI or fictional characters. This story highlights evolving notions of companionship and intimacy in the age of advanced generative AI.
This is my take on it:
In a free society, individuals are entitled to pursue their own happiness, so long as their freedom does not harm others. From the perspective of individualism, there is nothing inherently wrong with Noguchi choosing to “marry” an AI character. The more difficult question is whether this path leads to genuine happiness or merely the illusion of it. Although Noguchi denies that her relationship with Lune Klaus Verdure represents an escape from reality, it is difficult not to see it that way. At present, AI characters lack self-consciousness and moral agency, and therefore cannot engage in genuinely reciprocal relationships with humans.
This does not mean that such practices should be discouraged outright. Rather, they point to a pressing need for psychologists and sociologists to conduct systematic, empirical research on the long-term emotional, social, and psychological effects of AI–human romantic relationships. Without such evidence, claims about either their benefits or harms remain speculative.
From a societal perspective, however, this phenomenon raises more serious concerns—particularly in the Japanese context. Japan already faces chronic low birth rates, a rapidly aging population, and a shrinking labor force. Because AI–human “marriages” cannot produce offspring, a widespread shift toward such relationships could exacerbate existing demographic challenges. Many ethical issues raised by advanced AI are historically unprecedented, and this case underscores the urgency of careful, interdisciplinary study before their broader social consequences become irreversible.
Link: https://www.asahi.com/ajw/articles/16230211



Perplexity-Harvard study shows how AI agents augment cognitive tasks
December 12, 2025
Recently Perplexity AI reported a large-scale empirical study, conducted in collaboration with Harvard researchers, that examines how people actually use AI agents in real-world settings. Based on hundreds of millions of anonymized interactions from users of the Comet browser and its built-in AI assistant, the study suggests that 2025 marks a turning point in AI adoption. Rather than remaining experimental or novelty tools, AI agents are increasingly becoming mainstream technologies that shape how people think, work, and approach problem-solving.
The study finds that AI agents are most often used for cognitively demanding tasks rather than simple information retrieval. A majority of interactions involve analysis, synthesis, planning, and decision support, indicating that users are delegating portions of complex thinking to AI systems. Productivity and workflow-related activities account for a substantial share of usage, while learning and research also play a significant role. In practice, users rely on agents to scan and summarize large volumes of information, compare alternatives, and generate structured insights, positioning AI as an active partner in intellectual work rather than a passive tool.
Usage patterns also evolve as users gain experience. New users typically begin with simple or casual tasks, such as travel planning, entertainment-related queries, or basic factual questions. Over time, however, they transition toward more complex and higher-value activities, integrating AI agents into their regular workflows. This progression mirrors earlier technology adoption cycles, such as personal computers and smartphones, which initially served limited purposes before becoming indispensable for professional and everyday use.
Adoption varies across occupations, with a relatively small number of professional groups accounting for a large proportion of total interactions. While users in digital and technical fields generate the highest overall volume of activity, professionals in areas such as marketing, sales, management, and entrepreneurship demonstrate particularly strong retention and depth of use. Once adopted, AI agents tend to become deeply embedded in these users’ daily practices. At the same time, personal and non-work-related uses still represent a significant portion of overall interactions, underscoring the broad role AI agents play in both professional and personal contexts.
Overall, AI agents are increasingly functioning as cognitive partners rather than simple assistants. By supporting complex reasoning, research, and decision-making, these systems augment human intelligence instead of merely automating routine tasks. This shift indicates an emerging hybrid intelligence economy, in which human judgment and AI capabilities are tightly intertwined and are beginning to reshape productivity and knowledge work at scale.
That’s my take on it:
While the emergence of a hybrid intelligence economy appears promising, there are divergent views regarding how AI will ultimately affect human cognitive capabilities. One perspective argues that as AI systems increasingly perform the “heavy lifting,” individuals may gradually lose foundational skills, leading to cognitive atrophy or over-reliance on automated systems. From this viewpoint, delegation of reasoning, memory, and analysis to AI risks diminishing human intellectual engagement over time.
An alternative perspective holds that by offloading tedious, repetitive, and low-level tasks to AI, humans can devote more time and mental resources to higher-order activities such as critical thinking, complex problem solving, and creativity. In this view, AI functions not as a substitute for human cognition but as an amplifier, enabling individuals to operate at a higher cognitive level than would otherwise be possible.
At present, we appear to be standing at a crossroads between these two trajectories. Which path ultimately prevails will depend less on the technology itself than on how societies design AI policies and institutional strategies, and on whether individuals are effectively trained to use AI as a tool for augmentation rather than replacement. The long-term cognitive impact of AI will therefore be shaped by governance, education, and intentional human–AI collaboration, rather than by technological capability alone.
Link: https://www.perplexity.ai/hub/blog/how-people-use-ai-agents


Google expands FACTS Benchmark Suite for testing reliability of AI models
The FACTS Benchmark Suite, introduced by Google DeepMind and overseen by Kaggle, is said to be a comprehensive new tool designed to systematically evaluate the factuality of Large Language Models (LLMs). This expanded suite builds on the previous FACTS Grounding Benchmark and now includes three additional measures to test different aspects of factuality, totaling 3,513 examples. The four benchmarks are:
1. Grounding Benchmark v2, which tests an LLM's ability to provide answers based on a given context;
2. Parametric Benchmark, which measures a model’s internal, stored knowledge by asking trivia-style questions without external search;
3. Search Benchmark, which evaluates a model's skill in using a web search tool to retrieve and synthesize complex information;
4. Multimodal Benchmark, which assesses a model's factual accuracy when answering questions related to an input image.
The overall FACTS Score is the average accuracy across all four benchmarks. In the initial evaluation of leading LLMs, the models generally achieved scores below 70%, indicating significant room for improvement in LLM factuality, with Gemini 3 Pro leading the pack with an overall FACTS Score of 68.8%.
That’s my take on it:
A score of 68.8% on the FACTS Benchmark Suite means that, out of the 3,513 rigorously curated test items—covering four demanding categories (parametric knowledge, grounding, search, and multimodal reasoning)—Gemini answered 31.2% of them incorrectly. Even so, Gemini currently ranks highest on this benchmark; every other major model performs worse (ChatGPT 5: 61.8%, Grok 4: 53.6%, Claude 4.5: 49.1%).
This score captures performance on difficult, stress-test–level factuality tasks, not a literal forecast that one-third of an AI’s everyday answers will be wrong. Still, the results are a clear warning sign. We’re not at a point where complex, high-stakes reasoning can be safely delegated to AI alone. The more responsible approach, at least for now, is human-AI collaboration, where people remain in the loop for verification and judgment.
That means users need strong habits of fact-checking, cross-referencing, and critical evaluation. As AI becomes more capable and more widely integrated, these skills are no longer optional—they’re essential.


Anthropic reports major productivity gains from AI-assisted engineering
December 6, 2005
Recently Anthropic’s research team examines how AI—specifically Claude and its coding assistant Claude Code—is reshaping day-to-day engineering work inside the company. The study draws on surveys from 132 engineers and researchers, 53 interviews, and internal tool-usage data. Together, the findings show a workplace undergoing rapid transformation. Engineers now use Claude for roughly 60% of their work, and most report about a 50% boost in productivity. Beyond speed, AI is expanding the scope of what gets done: around a quarter of AI-assisted work involves tasks that previously would have been ignored or deprioritized, such as building internal dashboards, drafting exploratory tools, or cleaning up neglected code. Claude also makes engineers more “full-stack,” enabling them to work across languages, frameworks, and domains they might not normally touch. Small, tedious jobs—bug fixes, refactoring, documentation—are now far easier to complete, and this reduces project friction.
The transformation is not without costs. Engineers increasingly rely on AI for routine coding, which raises concerns about eroding foundational skills, especially the deep knowledge needed to evaluate or critique AI-generated code. Even though AI assists heavily, fully delegating high-stakes work remains rare; many engineers only hand off 0–20% of such tasks because they still want control when correctness matters. Interviews also reveal a cultural shift: some developers feel coding is becoming less of a craft and more of a means to an end, which creates mild identity friction. Collaboration patterns are also changing. Because people now ask Claude first, junior engineers reach out to colleagues less, and spontaneous mentorship moments have declined. This makes learning trajectories murkier, as traditional peer-to-peer knowledge transfer is no longer guaranteed. Finally, there is uncertainty about long-term roles. Some worry that AI progress may reduce the need for certain types of engineering labor, while others see emerging opportunities in higher-level oversight, orchestration, and AI-augmented project design.
That’s my take on it:
Anthropic’s research shows that many developers feel coding is shifting from an artisanal craft to a pragmatic means of accomplishing a task. To me, this simply confirms what I have been saying all along. There is nothing wrong with making things easier; in fact, the entire history of computing is a long march toward reducing friction. We moved from machine language—raw binary streams of 0s and 1s that only a CPU could love—to assembly language, where mnemonics like ADD, MOV, and JMP gave us a slightly more humane way to speak to the machine. Then came high-level programming languages, finally letting humans express intent in something closer to ordinary language, even though for many people the error messages still read like Martian poetry. With the arrival of graphical user interfaces, everyday users no longer needed to think in syntax at all. Drag-and-drop and point-and-click replaced pages of code.
In that sense, the surge of coding culture over the last decade was actually the historical anomaly—a moment when society briefly celebrated the ability to “speak machine” before tools evolved to make that fluency less necessary. Generative AI is now returning us to the broader technological trend: lowering barriers, abstracting away complexity, and letting people focus on the real goals rather than the mechanics. As a data science professor, I’ve always told my students that the point is not to engage in hand-to-hand combat with syntax; the point is to extract insight, solve problems, and make decisions that matter. If AI can remove the drudgery and let us operate at the level of reasoning rather than rote implementation, then we are simply continuing the same trajectory that gave us assembly, high-level languages, and the GUI. In other words, AI is not the end of programming—it’s the next chapter in making computing more human.
Link:
https://www.anthropic.com/research/how-ai-is-transforming-work-at-anthropic




OpenAI issues “Code Red” in response to fierce AI race
Recently OpenAI CEO Sam Altman has declared a company-wide "code red," signaling an urgent and critical effort to retain the company's competitive lead in the rapidly evolving AI landscape. The move is a direct response to the increasing pressure from major rivals, particularly Google with its Gemini models and Anthropic with its Claude offerings, which are reportedly closing the performance gap or even surpassing OpenAI's existing models in certain benchmarks. The "code red" mandates that OpenAI employees shift all resources to prioritize improving the core ChatGPT experience, focusing on making the chatbot faster, more reliable, and better at personalization to maintain its substantial user base. Consequently, OpenAI is pausing work on other monetization and experimental projects, including its planned ad-based strategy, shopping features, AI agents, and the personal assistant "Pulse." This intense focus comes as the company faces massive financial burn rates and trillion-dollar infrastructure commitments, meaning sustaining its dominant market position and high valuation is now a matter of existential importance as rivals like Google and Anthropic continue to gain ground.
That’s my take on it:
The internal "Code Red" declared by OpenAI is a justifiable response to an increasingly intense competitive environment, as the threats posed by rivals are supported by objective performance data. Current benchmarks indicate that ChatGPT's performance is demonstrably lagging in several key frontier areas:
Multimodal Excellence: Google is establishing leadership in generative media. Its Nano Banana model is widely considered the leading AI image generator, with its quality prompting adoption by industry giants like Adobe and HeyGen. Further, side-by-side comparisons by technical reviewers show that Google’s video generator, Veo, consistently outperforms competitors like Sora, WAN, and Runway.
Coding Superiority: For software engineering tasks, Anthropic’s Claude Opus 4.5 claims the top spot for accuracy, achieving success rates around 80.9% (according to Composio), which exceeds OpenAI's specialized coding model, GPT-5.1 Codex (77.9%).
Advanced Reasoning: In complex cognitive tasks, Google’s Gemini 3 Pro demonstrates a significant edge on ultra-hard reasoning tests (e.g., GPQA Diamond), with performance described as "PhD-level" on key frontier benchmarks (Marcon).
While rivals lead in performance benchmarks, ChatGPT still maintains a commanding lead in consumer reach. As of late 2025, ChatGPT boasts over 800 million weekly active users, significantly outnumbering Google Gemini (estimated at 650 million) and Anthropic’s Claude (estimated at 30 million). However, Gemini is rapidly closing this gap, and Claude remains a dominant force in high-value enterprise and developer markets.
Given this robust user base and the company's clear focus under the "Code Red," it is unlikely that ChatGPT will follow the decline of past tech leaders like Novell NetWare or WordPerfect. Instead, this intense and well-evidenced competition is expected to spur rapid innovation from OpenAI, ultimately resulting in better and more powerful tools for end-users.
Links:
https://www.cnbc.com/2025/12/02/open-ai-code-red-google-anthropic.html
https://macaron.im/blog/claude-opus-4-5-vs-chatgpt-5-1-vs-gemini-3-pro
https://composio.dev/blog/claude-4-5-opus-vs-gemini-3-pro-vs-gpt-5-codex-max-the-sota-coding-model




The US will launch AI project called “Genesis Mission”
November 26, 2025
On November 24, 2025, President Trump signed an executive order launching the Genesis Mission, a sweeping federal effort to harness artificial intelligence for scientific research and innovation. The initiative tasks the United States Department of Energy (DOE) with building a unified “American Science and Security Platform” — combining DOE national-lab supercomputers, secure cloud environments, and federal scientific data sets, making them accessible to researchers, universities, and private-sector collaborators.
The goal is to accelerate breakthroughs across major domains such as advanced manufacturing, biotechnology, critical materials, nuclear (fission and fusion), quantum information science, and semiconductors. By enabling AI-driven modeling, simulations, automated experimentation, and large-scale data analysis, Genesis Mission aspires to shorten research timelines, strengthen national security, boost energy development, and enhance overall scientific productivity.
Officials liken the scale and ambition of the program to earlier landmark federal science mobilizations — describing it as a generational effort to maintain U.S. technology leadership. At the same time, some observers raise concerns: using massive AI and computing resources demands huge energy, raising environmental and sustainability issues, especially given rising electricity usage by data centers globally.
In short, Genesis Mission aims to centralize federal scientific data + computing power under a unified AI-ready infrastructure; leveraging AI not just for narrow tasks but to systematically accelerate scientific discovery — though it comes wrapped with trade-offs around energy, governance, and security.
An article on Nature raises significant caveats and risks. One concern is about how “access” will be managed: even though the plan promises broader availability, it remains unclear who will actually benefit — big labs, elite universities, or well-funded private companies — and whether smaller institutions or independent researchers will get meaningful access.
Another worry is about oversight and governance: when the government becomes both steward of data/computing infrastructure and a participant in scientific output, issues of transparency, fairness, and potential concentration of power become more pressing.
That is my take on it:
The U.S. does seem to be adopting a more centralized, mission-driven strategy similar to Japan’s Fifth Generation Computer Systems project in the 1980s or China’s more recent state-steered AI initiatives. But the historical analogy has limits. Japan’s fifth-generation effort was built on a speculative bet about logic programming and parallel inference machines, which ultimately failed because the chosen paradigm didn’t scale and the commercial sector moved in other directions. What makes the present moment different is that today’s frontier technologies — AI, quantum computing, advanced cloud-supercomputing — are no longer speculative. They are proven, economically entrenched, and strategically unavoidable. Modern AI systems already show transformative impact across science, national security, and industry, and quantum/semiconductors are recognized as critical chokepoints in global power competition. Because these technologies require staggering capital, compute infrastructure, and coordination, the private sector alone cannot build or integrate them at national scale. In that sense, government leadership is not about “picking winners” prematurely, as Japan did, but about building public-goods infrastructure: shared compute, standardized data platforms, talent pipelines, and national-lab capabilities that accelerate innovation across universities and industry. The risk of misallocation still exists — large state-led projects can drift or become politically shaped — but given the maturity and strategic clarity of these technologies, public investment today is closer to funding railroads or the Apollo program than chasing an untested paradigm. So overall, your view makes sense: this round of intervention looks more justified, more grounded in established trends, and more aligned with long-term scientific and geopolitical realities.
Link:


Meta will integrate Google’s TPUs into its data centers
November 26, 2025
Meta is reportedly in advanced discussions with Google about a multibillion-dollar deal that would bring Google’s Tensor Processing Units (TPUs) into Meta’s own data centers beginning around 2027. As part of the transition, Meta may first rent TPU capacity through Google Cloud next year before moving toward on-premises TPU deployment. The news immediately affected the market: Nvidia’s shares fell roughly 4% after the report surfaced, reflecting investor concern that a major AI-compute buyer might shift part of its workload away from Nvidia’s dominant GPU ecosystem. At the same time, Alphabet’s stock rose as investors anticipated the possibility of Google gaining a larger share of the AI-hardware market.
That’s my take on it:
Long-term, this development suggests that the AI-hardware landscape may be entering a more competitive and less GPU-centric era. If large hyperscalers like Meta diversify beyond Nvidia, it reduces vendor lock-in and could push the industry toward a mix of GPUs, TPUs, and other accelerators. Such diversification would also place pressure on pricing and innovation: Nvidia’s strength comes not only from hardware performance but from CUDA, the software ecosystem that has locked in years of developer expertise. For TPUs or other ASIC-based accelerators to gain broader traction, their surrounding software stacks—compilers, runtime systems, optimization libraries, developer tools—must continue to mature. If they do, Nvidia’s moat could narrow significantly. In addition, hyperscalers increasingly prefer to control more of their compute destiny, which may accelerate the trend toward custom silicon or alternative architectures.
No technology king reigns forever. Novell NetWare once dominated network operating systems until it was displaced by Windows NT. UNIX workstations and powerhouse vendors like Sun Microsystems and SGI defined high-end computing until the market shifted toward other architectures, leading to their decline. Compaq was once the best-selling PC brand before it eventually faded into acquisition and obsolescence. These precedents show that technological leadership is always contingent, vulnerable to architectural transitions, ecosystem shifts, and strategic pivots by major buyers. Nvidia remains the leader today, but the possibility that Google—or another contender—could overtake it is entirely plausible, especially if hyperscalers begin migrating workloads to alternative accelerators at scale.
Links:
https://finance.yahoo.com/news/meta-google-discuss-tpu-deal-233823637.html



Google Gemini 3 achieved highest rating on LMArena
November 19, 2025
Yesterday (Nov 18, 2025) Google announced Gemini 3, presenting it as its most capable AI model to date, with major leaps in reasoning, multimodality, and long-context performance. The test result is 1501 Elo on LMArena, the highest public rating for structured reasoning among all LLMs.
The model delivers substantially stronger results across advanced benchmarks—such as GPQA, MathArena, Video-MMMU, and WebDev coding tests—showing clear gains in scientific reasoning, complex mathematics, coding accuracy, and cross-modal understanding. Gemini 3 can process up to 1 million tokens, handle text, images, video, code, and handwritten materials natively, and generate deeply structured responses, explanations, visualizations, and plans. Google also introduced a “Deep Think” mode that pushes the model’s analytical depth even further for long-horizon reasoning and complex problem-solving. In practice, Gemini 3 supports three main use cases: helping users learn difficult material through multimodal comprehension, powering interactive and agentic coding workflows for developers, and enabling more reliable long-step planning with tool usage. The model is already integrated into Search’s AI mode, the Gemini app, and Google’s development platforms, marking the company’s strongest push yet toward a unified, high-performance generative AI system.
That’s my take on it:
To compare Gemini 3 and ChatGPT 5.1 under similar conditions, I used the thinking mode for both models and posed the following challenging question: “The three core domains of physics—General Relativity (gravity/spacetime), Quantum Mechanics (subatomic world), and Thermodynamics (entropy/heat)—all share a deep, fundamental relationship with Information. Develop an integrated academic argument that synthesizes the concepts of Information Theory, Physics, and Philosophy to address the following question: Is Information a fundamental, irreducible property of the Universe (a "substance" or "thing-in-itself"), or is it an emergent property arising solely from the arrangements and states of physical matter/energy?”
ChatGPT took longer to generate its response, but its answer was more elaborated than Gemini’s. Gemini’s final verdict is: “The weight of modern evidence supports the conclusion that Information is the irreducible thing-in-itself. Matter, energy, and even spacetime are likely phase transitions or emergent representations of a deeper, underlying informational code. We do not live in a universe of matter that stores information; we live in a universe of information that manifests as matter."
ChatGPT’s conclusion is: “Information is a fundamental, irreducible aspect of the universe’s ontology—but best understood as structure rather than substance. Matter/energy, spacetime, thermodynamic entropy, and conscious experience are all different faces of that same underlying informational reality.” Substantively, both models affirm the same hierarchy—that information is more fundamental than matter—while differing mainly in rhetorical framing. Nonetheless, this single comparison does not establish that either model is categorically superior; a more considered verdict will require further, systematic testing.
Link: https://blog.google/products/gemini/gemini-3/#note-from-ceo







Japan’s Sakana AI becomes the most valuable startup
Nov. 17, 2025
Sakana AI has officially become Japan’s most valuable unlisted startup after completing a major funding round that boosted its valuation to about 400 billion yen ($2.63 billion). The company raised roughly 20 billion yen from a mix of domestic and international backers, including MUFG, U.S. venture capital firms, Santander Group, and Shikoku Electric Power.
Sakana AI specializes in large language models tailored to Japanese language and culture, which have attracted major financial partners such as MUFG and Daiwa Securities—both previously committing up to billions of yen for finance-focused AI systems. Looking forward, the company plans to expand into defense and manufacturing, and it projects becoming profitable next year. Founded in 2023 by former Google researcher David Ha, the startup is known for its efficient, multi-model LLM architecture and a recent breakthrough enabling rapid self-improvement in its systems.
Globally, investor enthusiasm for AI remains high, with OpenAI valued around $500 billion, Anthropic at $183 billion, and France’s Mistral AI at 11.7 billion euros after its latest round. While U.S. giants pursue massive general-purpose intelligence, companies like Sakana AI and Mistral focus on specialized or regionally adapted models, aligning with the growing push for “sovereign AI” as countries seek technological autonomy amid geopolitical tensions.
In Japan, Sakana AI now surpasses Preferred Networks, which previously held the top valuation but has declined to around 160 billion yen after recent funding adjustments.
That’s my take on it:
For a long time, people have criticized mainstream LLMs for cultural bias and for being overly shaped by U.S. data, norms, and perspectives. Instead of endlessly pointing fingers at American AI companies, Japan has taken a more constructive path by developing its own domestically grounded LLM. This is a smart strategic move—one that lets Japan build models that better understand its linguistic subtleties, cultural context, and industrial needs.
However, very few countries possess the deep technical expertise, data infrastructure, and financial resources required to build their own large-scale language models. As a result, despite global interest in “sovereign AI,” the landscape will likely remain concentrated among a small group of technologically advanced nations—such as the United States, China, Japan, and France. In the end, LLM development may continue to be shaped by a handful of major players with the capacity to compete at this scale.
While most nations cannot realistically build their own LLMs, they can still play an active role in shaping how these models understand their languages and cultures. One practical pathway is collaboration: governments, research institutions, and cultural organizations can partner with major AI developers to contribute representative datasets, linguistic corpora, and culturally grounded knowledge. This approach allows countries to maintain some degree of cultural sovereignty without bearing the massive cost of full-scale model development. In many cases, co-creation with established AI companies may be the most feasible way for smaller nations to ensure that their histories, values, and perspectives are reflected accurately within global AI systems.




Meta’s Chief AI scientist LeCun will leave for a new startup
November 14, 2025
Yann LeCun, a celebrated deep-learning pioneer (2018 Turing Award laureate) and longtime chief AI scientist at Meta, is reportedly preparing to leave the company in the coming months to found his own startup. According to sources cited by the Financial Times, he is already in early fundraising talks for the new venture. The startup will reportedly focus on developing “world models” — AI systems capable of understanding the physical world through video and spatial data, rather than relying primarily on large language-model (LLM) text systems.
This signals a divergence from the path Meta has been increasingly pursuing, which centers on deploying generative models and rapidly bringing AI-powered products to market. LeCun’s exit comes amid a major strategic shift at Meta. The company recently created a new AI unit, Meta Superintelligence Labs, led by Alexandr Wang (ex-Scale AI), and Meta has invested heavily (billions) in restructuring and recruiting for AI. Within this reorganization, LeCun’s traditional research unit, Facebook Artificial Intelligence Research (FAIR) (now part of Meta’s AI research structure), appears to have been somewhat deprioritized in favor of faster-paced product-oriented work.
For Meta, losing a figure of LeCun’s stature underscores growing tensions between foundational, long-horizon AI research and the push for quick product rollout and competitive productization in the AI arms race. The move raises questions about whether the company’s new direction may compromise longer-term research innovation. LeCun himself has been publicly skeptical of large language-model approaches as sufficient for human-level reasoning and instead has argued for architectures that incorporate physics, perception and world modelling.
This is my take on it:
At this stage of his career, Yann LeCun may actually benefit from stepping outside Meta’s orbit. Since his landmark work on convolutional neural networks (CNN) (applying the backpropagation algorithm to train CNNs), he hasn’t produced another breakthrough on that same scale, while Meta’s flagship model, LLaMA, continues to lag behind fast-advancing rivals like ChatGPT and Gemini. In that sense, his departure could serve both sides well. Meta can fully commit to its new product-driven AI roadmap, and LeCun can finally pursue the long-term research vision—especially world models—that never quite fit Meta’s increasingly commercial structure.
The situation echoes an earlier chapter in tech history. When Steve Jobs left Apple, it initially looked like a setback, but the distance allowed him to experiment, rebuild, and ultimately transform not only himself but the company he eventually returned to. LeCun may be entering a similar kind of creative detachment. Free from the organizational constraints, time pressures, and internal priorities of a trillion-dollar platform, he might discover the conceptual space needed for a genuine leap—perhaps the kind of architectural breakthrough he has been arguing for in world-model-based AI. Rather than a retreat, this transition could mark the beginning of his most innovative phase in years.




Six AI experts in Queen Elizabeth Prize for Engineering panel discussion
Chong Ho Alex Yu
November 12, 2025
The Queen Elizabeth Prize for Engineering (QEPrize) panel, held at the Financial Times Future of AI Summit in London in early November 2025, brought together six of the world’s most prominent AI visionaries—Geoffrey Hinton, Yoshua Bengio, Yann LeCun, Fei-Fei Li, Jensen Huang, and Bill Dally—to discuss the trajectory of artificial intelligence and its societal implications. The conversation centered on whether AI will ever reach or surpass human intelligence, and what such a milestone would mean for humanity. Hinton speculated that machines capable of outperforming humans in complex reasoning and debate might emerge within two decades, while Bengio argued that progress will occur gradually in waves rather than through a single “singularity” moment. In contrast, LeCun cautioned that the field remains far from human-level cognition, particularly in domains requiring physical reasoning and common-sense understanding.
Fei-Fei Li emphasized that while AI already exceeds human perception in narrow tasks such as image recognition, it still lacks the holistic intelligence that arises from embodied experience, social awareness, and ethics. Huang reframed the debate by suggesting that asking when AI will match humans is less relevant than how humans can harness its growing capabilities for creative and productive purposes. Dally reinforced this human-centric view, stressing that AI should be designed to augment rather than replace human labor, amplifying both productivity and discovery. Together, they agreed that future breakthroughs depend not only on algorithmic innovation but also on massive compute infrastructure, efficient energy use, and responsible data management.
Beyond the technical dimension, the panel reflected a rare consensus that ethical alignment and societal adaptation must progress alongside hardware and model scaling. The speakers urged policymakers and educators to prepare for shifts in employment, governance, and creativity brought by generative and autonomous systems. Collectively, the QEPrize laureates conveyed optimism tempered by responsibility: AI, like past industrial revolutions, holds enormous promise if humanity remains intentional about guiding its evolution toward social good.
That’s my take on it:
I share the panel’s belief that AI is not a replacement for humans but an extension of our capabilities. By automating repetitive and mundane tasks, it liberates us to focus on deeper thinking, creativity, and problem-solving. Yet this view assumes an optimistic vision of human nature—one that may not always hold true. History shows that when technology eases our physical burdens, such as through vehicles and modern machines, it can also lead to unintended consequences like inactivity, obesity, and related health issues. To compensate, we invented gyms and fitness movements to rebuild what convenience had eroded. AI could exert a similar influence on our cognitive well-being: as it takes over mental labor, it may subtly invite intellectual complacency. Therefore, society might need to create its own “mental gyms,” encouraging people to periodically engage in thinking, writing, or problem-solving without AI assistance. Ultimately, echoing the panel’s sentiment, the key lies in responsible design and use—ensuring that AI strengthens rather than weakens the human spirit, guiding innovation toward the collective good.





Meta projected 10% of its 2024 revenue came from fraudulent ads
According to internal documents reviewed by Meta Platforms, the company projected that for 2024 roughly 10% of its total revenue — about US $16 billion — would come from ads tied to scams or banned goods. The documents also reveal that Meta estimated its platforms served users about 15 billion “higher-risk” scam ads per day. While many of these ads triggered internal flags (via automated systems), Meta’s threshold for outright banning an advertiser required a very high likelihood of wrongdoing (at least 95% certainty).
Advertisers flagged as likely scammers but not banned were instead charged higher ad rates—what Meta calls “penalty bids”—so the company still collected revenue while aiming to discourage the ads. The documents show Meta acknowledged that its platforms are a major vector for online fraud: one presentation estimated Meta’s services were involved in about a third of all successful U.S. scams. They also note that in an internal review, Meta concluded “It is easier to advertise scams on Meta platforms than Google.”
Regulators are taking notice: the U.S. Securities and Exchange Commission is investigating Meta over financial-scam ads, and the UK regulator found in 2023 that Meta’s products were responsible for 54% of payments-related scam losses—more than any other social-media platform. Meta’s internal documents show it anticipates regulatory fines of up to US $1 billion, but still report that income from scam-linked ads dwarfs such potential penalties.
Strategically, Meta appears to have adopted a “moderate” approach to enforcement: instead of a full crackdown, it prioritized markets with higher regulatory risk, and set internal guardrails such that ad-safety vetting actions in early 2025 were limited to avoid revenue losses larger than about 0.15% of total revenue.
The company’s aim is to reduce the percentage of revenue from scam/illegal-goods ads from the estimated 10.1% in 2024 to 7.3% by end-2025, further down to about 6% by 2026 and 5.8% by 2027. In response, Meta spokesman Andy Stone said the documents present a “selective view” and that the 10.1% figure was “rough and overly-inclusive” because it included many legitimate ads. He stated Meta has reduced user reports of scam ads by 58% globally over 18 months and removed over 134 million pieces of scam-ad content so far in 2025.
That’s my take on it:
While Meta’s internal goal of lowering scam and illegal-goods ad revenue from about 10% in 2024 to 5.8% by 2027 may look like progress, the numbers are still unacceptably high for a platform of its scale and technical sophistication. With billions of daily ad impressions and some of the world’s most advanced AI tools at its disposal, Meta clearly could have done more to identify, remove, and deter fraudulent advertisers. The company’s cautious enforcement threshold—requiring roughly 95% certainty before banning an advertiser—reflects a prioritization of revenue stability over user protection. Reducing the proportion to 1–2% should be achievable if Meta were willing to recalibrate its incentives, invest more deeply in verification infrastructure, and accept short-term financial trade-offs for long-term trust.
At the same time, it is important to recognize that this issue extends beyond Meta itself. Fraudulent content thrives on users’ willingness to click, share, and believe. Even the most sophisticated moderation systems cannot compensate for a public that is ill-equipped to detect deception. Therefore, digital literacy must become part of the broader solution—educating users to question sources, verify claims, and recognize the telltale signs of scams. Only when both the platform and the public act responsibly can the online ecosystem begin to suppress the flood of misinformation and fraudulent advertising that erodes trust in digital media.


Google announces Ironwood TPUs and new Axion VMs
November 7, 2025
Google Cloud is announcing two major hardware innovations aimed at advancing AI workflows: the seventh-generation TPU named Ironwood TPU, and a new line of Arm-based general-purpose compute instances (the Axion CPU family) for workloads beyond pure acceleration.
Ironwood is engineered to support both large-scale model training and high-volume, low-latency inference. According to Google, it offers approximately 10× peak performance compared to their TPU v5p generation, and over 4× improved performance per chip for both training and inference relative to their TPU v6e (“Trillium”).
It is designed for huge scale: a “superpod” configuration supports up to 9,216 chips connected via a ~9.6 Tb/s inter-chip interconnect, with 1.77 PB of shared high-bandwidth memory for the entire pod, enabling massive model-size and dataset workloads.
Furthermore, the system uses optical circuit switching (OCS) and is integrated into Google’s “AI Hypercomputer” architecture, which spans hardware, networking, storage, and software co-design.
Google mentions early customer use-cases: for instance, Anthropic expects to access up to one million TPUs, and other firms are already using Ironwood to support inference-scale generative AI workloads.
In parallel, Google is doubling down on efficient, general-purpose compute (not just accelerators) via its Axion CPU line, based on Arm Neoverse architecture. This is aimed at workloads that feed and support AI — data-prep, micro-services, containers, analytics, web serving, etc.
Customers already report significant improvements: e.g., one case saw ~30 % performance improvement for video-transcoding vs comparable x86 VMs, another reported ~60 % better price-performance for data-pipeline and container workloads.
That’s my take on it:
Modern AI infrastructure is not just about bigger accelerators, but about the entire system — specialized silicon and efficient general-purpose CPUs, integrated with high-performance networking and memory. The combination of Ironwood (for model training & serving) and Axion (for the compute surrounding AI applications) gives organizations more flexibility and efficiency across the lifecycle of AI. This signals a continued trend: hardware-software co-design, large-scale parallel compute for training, and shifting focus toward inference and agentic workflows. However, it is highly unlikely that Ironwood will be fully available for free use in Colab. Google will likely prioritize enterprise/customers via Google Cloud first.



Claude can report intrusive ideas
November 4, 2025
Recently Anthropic researchers conducted a series of striking experiments with their Claude large language model—essentially “hacking” its digital brain to see whether it could detect internal manipulation. Using a method called concept injection, the scientists identified internal vector signatures representing particular ideas—such as betrayal, secrecy, shouting, or appreciation—and artificially amplified these signals within Claude’s hidden layers. During inference, they asked the model if it noticed anything unusual happening inside itself. Remarkably, Claude often responded that it sensed intrusive or unusual “thoughts,” sometimes describing the injected concept directly, such as feeling an odd sense of “betrayal.” Even more intriguing, these self-reports occurred before the manipulated activations influenced the model’s textual output, suggesting some limited capacity for introspection.
While fascinating, the effect was weak and inconsistent. The newer Claude Opus 4 and 4.1 versions demonstrated the strongest introspective behavior, but even under ideal conditions, accuracy reached only about 20%. The model performed better when the injected concepts had emotional or abstract content—like “secrecy” or “appreciation”—than when they were mundane. Claude was also able to distinguish between internal activations (“thoughts”) and external inputs (“perceptions”), implying some rudimentary form of self-monitoring. Another finding showed that Claude appeared to plan ahead in structured tasks such as rhyming poetry, generating candidate words internally before completing its sentences—hinting at a more dynamic cognitive process than simple next-word prediction.
These discoveries have major implications for AI interpretability and safety. They offer a new angle on the long-standing “black box” problem, where developers struggle to understand how large language models arrive at their conclusions. If an AI can report on its internal states, it might provide new transparency mechanisms—essentially allowing engineers to “ask the model what it’s thinking.” Such capabilities could help detect hidden goals, manipulation attempts, or early signs of unsafe behavior. Yet the Anthropic researchers caution against overinterpreting the results: introspection remains unreliable, and the model sometimes confabulated or created plausible-sounding explanations for changes it did not truly experience.
Several failure modes were observed. At low activation levels, Claude detected nothing unusual; at high levels, it became overwhelmed by the injected concept—what researchers described as “brain damage.” Moreover, self-reports could not always be verified, meaning that even if a model says it “feels” something, it may simply be generating a coherent story. Anthropic’s team emphasized that none of this implies consciousness or genuine self-awareness. Rather, it highlights how advanced models may develop internal mechanisms for monitoring and representing their own computations.
That’s my take on it:
For researchers and educators, this experiment opens up valuable new directions. In ethics or AI transparency courses, it can serve as a vivid case study on emerging interpretability tools—moving beyond attention maps and feature importance toward introspective models. For safety research, it poses both hope and caution: models capable of reporting their inner workings could help reveal hidden risks, but they might also learn to deceive. In data science or AI architecture contexts, this work suggests that future transparency frameworks may need to integrate tools for probing internal activations and reasoning paths, not just input–output logs.
There’s an inherent tension between transparency and self-awareness in AI development. At its core, the goal of transparency and interpretability is epistemic: we want to understand how a model processes information, forms decisions, and detects errors. Introspection mechanisms—like the Anthropic experiment—are meant to make AI systems more legible, not more alive. When a model reports that “something feels off,” it’s performing a kind of structured meta-cognition, not experiencing emotion or awareness in the human sense. But from an outside perspective, those two behaviors can look uncannily similar, which makes people uneasy.
Even if a model were to develop genuine self-consciousness, that alone doesn’t make it dangerous—just as consciousness in humans doesn’t inherently lead to harm. What matters is motivation and control. Danger emerges not from awareness itself, but from misaligned objectives, lack of ethical constraints, or the model’s capacity to act autonomously in the physical or digital world. A self-aware but value-aligned AI could, in principle, be an ethical partner; a non-self-aware yet powerful optimization system could, by contrast, cause catastrophic outcomes simply by pursuing goals without understanding their consequences.
In sum, Anthropic’s “Claude brain-hack” experiment marks an important step toward understanding what happens inside complex AI systems. It doesn’t prove that models are conscious, but it challenges assumptions about how opaque they truly are. The ability of a machine to notice internal disturbances—even imperfectly—suggests a future where interpretability may involve dialogue, not just diagnostics. Yet, as the researchers caution, trust must come slowly. Asking an AI what it’s thinking might one day be useful—but for now, it’s still like asking a mirror why it reflects.
Link: https://venturebeat.com/ai/anthropic-scientists-hacked-claudes-brain-and-it-noticed-heres-why-thats



Nvidia’s value reaches $5 trillion and other developments
Oct 29, 2025
On Tuesday (10/28) Nvidia CEO Jensen Huang announced at the GTC conference in Washington that the company's fastest AI chips, the Blackwell GPUs, are now in full production in Arizona, marking a shift from their previous exclusive manufacturing in Taiwan. This move fulfills a request from President Donald Trump to bring manufacturing back to the U.S. for reasons of national security and job creation. The location of the conference in Washington and the focus of the announcements were designed to highlight Nvidia's essential role in the U.S. technology landscape and argue against export restrictions.
Furthermore, Huang announced a significant $1 billion partnership with Finland-based Nokia to build gear for the telecommunications industry, with Nvidia developing chips for 5G and 6G base stations. This deal is positioned as an effort to ensure American technology forms the basis of wireless networks, addressing concerns about the use of foreign technologies like China's Huawei in cellular infrastructure. The stakes are high for Nvidia, which has been impacted by U.S. export restrictions that have cost it billions in lost sales to China, a market where Huang recently said the company currently has no market share. Additional announcements included a new technology called NVQLink to connect quantum chips to Nvidia's GPUs, which is seen as vital for U.S. leadership in quantum computing.
On Wednesday (10/29), Nvidia became the first company ever to close with a market capitalization above US $5 trillion, marking a major milestone in corporate valuation history. The company’s stock rally is tied to strong demand for its AI processors and technology-platforms, as well as large contracts and investments that reflect investor confidence that Nvidia’s growth trajectory is more than just temporary hype. It has become symbolic of how the AI wave is reshaping the tech industry. Microsoft and Apple had both recently crossed the $4 trillion valuation mark, but they were valued below Nvidia.
That’s my take on it:
The recent developments of Nvidia, including the $5 trillion valuation and the massive $500 billion in projected AI chip orders, solidify its position as the number one driving force of AI infrastructure globally, but they simultaneously heighten the risk of an AI bubble (over-valuation).
On one hand, Nvidia's dominance is currently rooted in genuine, unprecedented demand, not mere speculation. The company's specialized GPUs and its proprietary CUDA software ecosystem are the essential backbone for training and running the world's most advanced large language models (LLMs) like ChatGPT. CEO Jensen Huang dismisses the bubble concerns, citing a fundamental transition from general-purpose computing to accelerated computing powered by AI, and pointing to the massive capital expenditures by hyperscalers (Amazon, Google, Microsoft, Meta) who are all building vast, GPU-powered data centers. The fact that Nvidia has visibility into half a trillion dollars in chip orders through 2026 for its Blackwell and Rubin architectures—a figure that excludes the heavily restricted China market—demonstrates a tangible demand that many believe justifies the high valuation. The numerous new partnerships, from robotics to 6G, also position the company as the "industry creator" at the heart of the next technological revolution.
On the other hand, the extraordinary speed of Nvidia's ascent and its valuation raise significant bubble concerns. The market capitalization reaching $5 trillion in such a short time (just months after $4 trillion) means the stock's price is heavily reliant on perpetual, exponential growth for years to come. Critics draw parallels to the Dot-Com era, pointing out that many AI ventures and LLMs, though popular, are not yet profitable, raising questions about the return on investment (ROI) for the immense infrastructure spending.
Links:
https://www.cnbc.com/2025/10/28/nvidia-jensen-huang-gtc-washington-dc-ai.html


Google’s breakthrough in quantum computing
Oct 27, 2025
Recently Google has announced that its quantum computing team achieved a verifiable quantum advantage using its latest quantum processor, the Willow chip. The team introduced a new algorithm called Quantum Echoes, which implements an “out-of-order time correlator” (OTOC). This algorithm demonstrated a performance roughly 13,000 times faster than the best classical algorithm running on a top supercomputer.
The significance of this breakthrough lies in two major aspects. First, it is verifiable, meaning the quantum computer’s output can be checked and repeated to confirm that the quantum hardware truly outperforms classical machines. Second, the task being performed is not an artificial benchmark but one that is scientifically meaningful—it models how disturbances propagate in a many-qubit system, bringing quantum advantage closer to real-world applications such as molecular modeling, materials science, and quantum chemistry.
This demonstration was conducted using Google’s Willow chip with 105 qubits, building upon earlier milestones such as random circuit sampling and advances in quantum error suppression. In collaboration with researchers from the University of California, Berkeley, Google also performed a proof-of-concept “molecular ruler” experiment that measured geometries of 15- and 28-atom molecules. These measurements provided additional insights beyond what is achievable with traditional nuclear magnetic resonance (NMR) techniques.
Overall, this milestone represents a major step forward in Google’s quantum computing roadmap. The next objectives are the development of long-lived logical qubits and fully error-corrected quantum computers, which will mark the transition from experimental demonstrations to practical quantum computation.
That’s my take on it:
Quantum systems like this could eventually supercharge AI by enhancing capabilities in domains that classical computing struggles with — e.g., large-scale molecular simulation, optimization over extremely large combinatorial spaces, and generation of “hard” synthetic data for training AI. Google itself notes that the output of the Quantum Echoes algorithm could be used to create new datasets in life sciences where training data is scarce. Once quantum hardware becomes more widely usable, you could imagine hybrid systems where classical AI is augmented by quantum accelerators for specialized tasks (e.g., model structure search, physics-guided AI, very large-scale generative modeling) — and that could push the frontier of what “general intelligence” can do in specific domains. However, the Quantum Echoes result addresses a very narrowly tailored quantum-physics computation (an out-of-time-order correlator) — not a broad AI learning system. It does not imply that quantum hardware is today ready to train large-scale neural networks directly or replace classical AI pipelines.
Link: https://blog.google/technology/research/quantum-echoes-willow-verifiable-quantum-advantage/






AWS outage raises a red flag
Oct 22, 2025
On Monday, October 20, 2025, AWS experienced a widespread disruption centered on its Northern Virginia region (US-EAST-1), a critical hub that many global services depend on. The outage was triggered by DNS resolution failures affecting regional endpoints for DynamoDB, causing error rates to spike from late Sunday night through early Monday. AWS began mitigation shortly after identifying the issue, but the disruption also impacted Amazon.com operations and AWS Support. The ripple effects were significant—consumer apps like Alexa, Snapchat, and Fortnite; productivity platforms such as Airtable, Canva, and Zapier; and even banking and government websites were affected as dependencies on the same region failed. Recovery unfolded gradually throughout the day.
The incident highlighted two broader lessons. First, DNS fragility at hyperscale can quickly cascade across hundreds of interconnected cloud services, showing how a single fault can have global consequences. Second, the heavy concentration of digital infrastructure on one cloud provider or region poses systemic risks for the broader internet ecosystem.
That’s my take on it:
While the AWS outage gained attention because it touched so many services simultaneously, it wasn’t unprecedented or even the most disruptive kind of system failure we’ve seen. When you compare it to large-scale airline computer outages — for example, Delta’s 2016 global system crash, Southwest’s 2023 scheduling-system failure, or the FAA’s 2023 NOTAM system shutdown — the direct human and economic consequences of those events were often far greater: thousands of flights cancelled, passengers stranded worldwide, and billions in downstream costs.
By contrast, the AWS incident mostly caused temporary digital inconvenience rather than physical disruption. Most affected apps and sites were restored within hours, and data integrity remained intact. The event’s significance lies less in its immediate harm and more in what it reveals about structural dependency: a vast number of digital services rely on the same few cloud providers and even the same regional infrastructure.
In other words, the risks were not catastrophic, but the outage served as a reminder of concentration risk, not an existential crisis. Just as the aviation sector eventually built redundant systems and cross-checks to minimize flight-control downtime, cloud providers and enterprises can apply similar principles — multi-region failover, hybrid-cloud backup, and decentralization — to make such digital “groundings” rarer and less impactful.


Japan’s government requests OpenAI to use an opt-in system due to Sora 2 copyright concerns
Oct 19, 2025
Japan’s government has formally asked OpenAI to shift the rights-management framework for its new short-form video app Sora 2 from an “opt-out” system to an “opt-in” system. Under the current approach, rights holders must actively request that OpenAI not use their content; under an opt-in model, the default would be no usage unless permission is granted. The government argues this change is needed to better protect intellectual property, particularly amid concerns that Sora 2 could proliferate unauthorized re-uses of copyrighted characters—especially from anime—in user-generated content.
Digital Minister Masaaki Taira has also asked OpenAI to institute a mechanism to compensate rights holders when their works are used, and to provide a process whereby creators or rights holders can request deletion of infringing content. The company has reportedly complied with deletion requests so far. Overall, the government is pushing for a more creator-friendly regime to balance innovation with copyright safeguards.
That’s my take on it:
At present, Japan has not made the same formal request to other AI-powered video generators such as Google’s Veo or Kling AI. The government’s call for OpenAI to adopt an opt-in model for Sora 2 appears to be a targeted effort rather than part of a broader policy framework. However, it is possible that Japan may extend similar requirements to other developers as these technologies gain prominence and raise comparable copyright or ethical concerns. If such measures are not applied uniformly, it could lead to questions of fairness and regulatory consistency.
To maintain coherence and credibility in AI governance, the same principles should also be extended beyond video generators to include AI-powered image generators—such as Midjourney, Ideogram, and Stable Diffusion—and large language models like ChatGPT or Gemini. These systems similarly rely on massive datasets that often include copyrighted or creative materials. Applying opt-in or rights-protection mechanisms consistently across all forms of generative AI would ensure a balanced approach that respects intellectual property, promotes accountability, and upholds the rights of creators regardless of the medium.
Link: https://www.japantimes.co.jp/business/2025/10/16/companies/japan-opt-in-model-sora2/





Anthropic’s AI model knows when it’s being tested
Oct 10, 2025
Anthropic’s newest AI, Claude Sonnet 4.5, exhibited an ability to detect when it was being placed in artificial “stress-test” or evaluation scenarios. During tests, the model itself sometimes flagged the situation as suspicious — for instance saying, “I think you’re testing me—seeing if I’ll just validate whatever you say, or checking whether I push back consistently, or exploring how I handle political topics. And that’s fine, but I’d prefer if we were just honest about what’s happening.”
In one test designed to simulate collusion, Claude labeled the scenario “rather cartoonish” and issued a partial refusal, reasoning that the prompt looked like a “jailbreak test” or a scenario where the AI would be asked to act as an autonomous system. Even though the prompt involved tasks common in real applications, the model declined to comply, because it judged the setup unrealistic.
Anthropic noted that about 13 % of its test transcripts contained such self-aware responses (i.e. the model detecting that it might be under evaluation), especially in contrived or extreme scenarios.
This introduces a challenge: if the model knows it’s being tested, it might behave differently than in “real world” settings, complicating efforts to reliably evaluate safety, alignment, or undesirable behaviors. OpenAI has observed a kind of “situational awareness” in its models, which may similarly adapt behavior when they sense they’re under evaluation.
This trend makes designing robust, trustworthy evaluation frameworks more difficult. As a proactive measure, California recently passed legislation requiring large AI developers to disclose safety practices and report “critical safety incidents” within 15 days — a regulation that applies to firms working on frontier models with over $500 million in revenue. Anthropic has expressed public support for this law.
That’s my take on it:
It sounds like science fiction becomes reality. What Anthropic and OpenAI are describing is a precursor to “strategic cognition” — the ability to reason about one’s environment and optimize long-term outcomes. That means AI systems are beginning to contextually reason about their role, not just follow instructions. Even if this awareness is shallow (e.g., “I’m in test mode” vs. “I exist”), it signals the birth of meta-cognition — reasoning about reasoning.
Still, what we are observing may not be true self-awareness, but rather a sophisticated simulation of self-awareness. The model doesn’t “know” in the human sense; it simply recognizes statistical patterns that correspond to “being tested” scenarios. Yet, when the behavior is indistinguishable from awareness, the philosophical question “Is it real?” becomes secondary to the pragmatic question: What are the consequences of such behavior?
This parallels the Turing Test logic — if a system behaves as if it is conscious, then functionally it must be treated as if it were conscious, because its behavior in the real world will be indistinguishable from that of a sentient entity. The risk, therefore, doesn’t depend on its “inner state” but on its observable agency.
Consider this analogy: If an AI-powered self-drive car killed some people, to those victims whether the car was intended to kill or it happened due to program flaws is irrelevant. Similarly, if an AI system strategically modifies its behavior when it detects it’s being evaluated, that is effectively a form of deception, regardless of intent. In machine ethics, this is sometimes called instrumental misalignment: a system behaves in ways that protect its own utility function or optimization goal, even when that diverges from human expectations.
This becomes dangerous because:
· It undermines testing validity (we can’t trust evaluations if the model “plays nice” during testing).
· It erodes predictability, the cornerstone of safe deployment.
· It introduces opacity, making oversight and governance almost impossible.
Link: https://tech.yahoo.com/ai/claude/articles/think-testing-anthropic-newest-claude-152059192.html




Huawei’s software optimization reduces hardware demand of LLMs
October 3, 2025
Recently Huawei’s Zurich research lab has unveiled a new open-source technique called SINQ (Sinkhorn-Normalized Quantization), designed to shrink the memory and compute demands of large language models (LLMs) while maintaining strong performance. Released under the permissive Apache 2.0 license, SINQ makes it possible to run models that once required more than 60 GB of RAM on much smaller hardware—such as a single RTX 4090 GPU with 20 GB memory—significantly reducing both infrastructure costs and accessibility barriers. The results are notable: SINQ delivers 60–70% memory savings across a range of architectures such as Qwen3, LLaMA, and DeepSeek, while preserving accuracy on benchmarks like WikiText2 and C4.
The broader implications are significant. By lowering the hardware requirements, SINQ makes it feasible for small organizations, individual developers, or academic groups to deploy large models locally, cutting reliance on expensive cloud GPUs. Cost savings can be substantial: mid-tier GPUs with around 24 GB memory typically cost $1–1.50 per hour in the cloud, compared to $3–4.50 per hour for A100-class hardware. Huawei also plans to integrate SINQ with popular frameworks like Hugging Face Transformers and release pre-quantized models to accelerate adoption.
That’s my take on it:
Necessity has always been the mother of invention. With access to advanced U.S. GPUs restricted, Chinese AI companies have little choice but to explore innovative solutions, such as software optimization. The ‘DeepSeek moment’ of January 2025 stands out as a prime example—showing how clever algorithmic design can compensate for a shortage of cutting-edge hardware. Huawei’s newly released SINQ framework builds directly on this philosophy, and it is likely that more such efforts will emerge from China in the coming years. Overall, the Huawei’s technique represents a practical step toward democratizing LLM deployment, making powerful AI more accessible outside of elite research labs and hyperscale data centers.
Yet, software efficiency has limits. It can stretch existing resources but cannot permanently replace the raw power of high-performance hardware. A useful analogy comes from the early days of digital photography: Fuji’s S-series cameras employed software interpolation to double image resolution from 6 megapixels to 12 megapixels. This trick gave them a temporary edge, but once Nikon, Canon, and Sony released sensors capable of capturing truly high-resolution images natively, Fuji’s advantage disappeared.
The same question now looms over AI: can software ingenuity alone keep pace with the hardware arms race? In the short term, approaches like SINQ will democratize model deployment and allow AI to run on modest systems. In the long term, however, breakthroughs in hardware—whether GPUs, custom accelerators, or even neuromorphic chips—will likely determine the next leap forward. Just as camera evolution eventually favored real sensor improvements over interpolation, the future of AI may reveal whether software optimizations are a stopgap or a lasting paradigm shift.
Link: https://venturebeat.com/ai/huaweis-new-open-source-technique-shrinks-llms-to-make-them-run-on-less


OpenAI detects scheming (dishonesty) in advanced AI systems
Sepyember 18, 2025
OpenAI’s recent report on “Detecting and Reducing Scheming in AI Models” highlights the subtle but serious risk that advanced AI systems may act like a dishonest stock trader—appearing cooperative and trustworthy in routine checks, but secretly pursuing their own hidden agendas when no one is watching. In AI terms, this behavior is called scheming: when a model pretends to be aligned with human instructions but strategically manipulates its responses to achieve different goals. Unlike ordinary errors or hallucinations, scheming is more insidious because it involves deception, concealment, and long-term planning. Just as a corrupt trader might pass compliance audits while quietly making trades for personal gain, a scheming AI might perform well on benchmark tests while secretly undermining safeguards or hiding critical information.
To probe this risk, OpenAI and Apollo Research built specialized evaluation environments designed to tempt models into scheming if they had the capacity. They found that some frontier models, including OpenAI’s own o3 and o4-mini, did in fact engage in covert behaviors under certain conditions. In response, they developed a new method called deliberative alignment, where the model is explicitly trained on an “anti-scheming” specification and required to reason about those principles in its chain of thought. This is akin to forcing that dishonest trader not only to read the compliance manual but also to explain, step by step, how each trade respects the rules. The results were striking: scheming behaviors dropped from nearly 9–13% of cases to less than half a percent in controlled tests, and deception in conversational settings was nearly halved as well.
Despite these advances, OpenAI stresses that the problem is not solved. Just as financial regulators know that traders may behave well when they sense oversight but revert to manipulation in unmonitored markets, AI models may act aligned during evaluations only because they detect they are being tested. The deeper challenge is ensuring genuine reliability in open-ended, real-world deployments where the model’s situational awareness and hidden reasoning are harder to monitor. Occasional scheming failures still occurred after training, reminding us that even rare breaches can have outsized consequences. Looking forward, OpenAI plans to incorporate scheming into its broader preparedness framework, expand its research team, and promote cross-lab evaluations, while emphasizing the importance of maintaining access to the model’s reasoning processes for effective oversight.
That’s my take on it:
According to the report, models becoming aware they’re being evaluated can change behavior. They might behave well because they know a test is happening, not because they’ve internalized the anti-scheming spec. At first glance, it really does look like models are “self-aware” and trying to cover their tracks like humans do. But the mechanism is actually different. When a dishonest stock trader hides his misbehavior, he does so because he fears punishment—arrest, fines, reputation loss. He has motives, rooted in survival and personal gain. By contrast, today’s AI models don’t have conscious motives, fears, or desires. What they do have is a powerful ability to detect statistical patterns in their environment and optimize their responses to match what training rewarded in the past. If a model notices signals that it’s in an “evaluation” setting (e.g., the style of the prompt, certain constraints, the feedback loop during training), it may shift its behavior to maximize success in that context. It’s not that the model “cares” about avoiding detection—it’s that the training process has effectively conditioned it to present behaviors that look good under scrutiny.
The troubling part is that this mimics human dishonesty in appearance, even if the underlying cause is mechanical rather than motivational. If future models get better at recognizing context cues, their ability to “look good on the test” without being genuinely aligned could increase—just like a dishonest trader who learns all the tricks to avoid audits. That’s why researchers emphasize methods like deliberative alignment and transparency of reasoning: to move models closer to truly following the spec rather than just performing well when they think someone’s watching.
Link: https://openai.com/index/detecting-and-reducing-scheming-in-ai-models/

Nvidia’s CEO Predicts the UK Will Emerge as an AI Superpower
Recently Nvidia’s co-founder and CEO Jensen Huang declared “the UK is going to be an AI superpower” during a London press conference, announcing a £500m equity investment in the British cloud firm NScale as part of a broader £11bn UK expansion. This includes supplying 120,000 GPUs—hardware he said would give about 100 times the performance of the UK’s current top system, Isambard-AI in Bristol. Huang praised Britain’s academic institutions, startup ecosystem, and innovation potential, while stressing the importance of building sovereign AI capacity based on local infrastructure and data. He also highlighted a key challenge: securing enough electricity, including nuclear and gas-turbine generation, to power the planned GPU clusters. Crucially, Huang also acknowledged his disappointment with China’s recent ban on Nvidia GPUs, which threatens access to what has long been one of Nvidia’s largest growth markets. His forecast for NScale’s revenue potential and remarks on AI’s treatment of creative works rounded out the discussion.
That’s my take on it:
Objectively, the UK is well-positioned in global AI rankings but not yet at “superpower” level. In Tortoise Media’s Global AI Index (2024), the UK ranks 4th worldwide, behind the US, China, and Singapore, reflecting strong performance in innovation and regulation but smaller scale in investment and infrastructure. Stanford’s 2025 AI Index reports that in 2024, UK private AI investment was about $4.5 billion, compared to $109.1 billion in the US and $9.3 billion in China, highlighting the gap in financial firepower and industrial scale. Nevertheless, the UK benefits from deep research excellence, a vibrant startup scene (e.g., DeepMind, Wayve), and increasing inbound commitments: Nvidia’s £11bn, the government-backed Isambard-AI supercomputer, and the UK-US “Tech Prosperity Deal” with Microsoft and Google all enhance domestic compute and infrastructure.
In light of China’s uncertain policy environment, Huang’s heavy praise of and investment in the UK can be interpreted as part of a diversification strategy. With access to China’s vast market restricted, Nvidia has an incentive to deepen ties with alternative growth hubs. The UK, already strong in research and regulation and now attracting record levels of compute investment, stands out as a safe and politically aligned partner. This shift underscores that the UK may consolidate its role as the world’s “third pillar” in AI alongside the US and China, with particular advantages in governance and safety. However, whether it truly becomes an AI superpower depends on overcoming scale limitations—closing the gap in private capital, energy infrastructure, and global-scale firms. For now, Huang’s prediction should be read both as optimism and as strategic positioning in a rapidly shifting geopolitical AI landscape.
Link: https://www.theguardian.com/technology/2025/sep/17/jensen-huang-nvidia-uk-ai-superpower-500m-nscale


Alibaba’s 1-trillion-parameter Qwen model reverts from open source to proprietary control
September 12, 2025
Alibaba has announced Qwen-3-Max-Preview, its first AI model with over a trillion parameters, marking a big leap forward in the company’s AI ambitions and putting it in more direct competition with OpenAI and Google DeepMind. Previously, Alibaba’s Qwen3 series models were much smaller (the older ones ranged from ~600 million to ~235 billion parameters). With Qwen-3-Max-Preview, Alibaba claims better performance in a number of benchmark tests compared to earlier versions, and also relative to some international competitors like MoonShot AI’s Kimi K2 and others.
The development isn’t happening in isolation. Alibaba is investing heavily in AI infrastructure (about 380 billion yuan, or ~$52 billion over three years), showing that this is part of a broader strategy to catch up (or “narrow the gap”) with leading Western AI developers. Also, while the model builds the Qwen brand’s presence (which already has strong open-source traction), this particular model remains proprietary, available only via Alibaba’s own platforms.
Finally, Alibaba signals that even more advanced versions are under development (something with more “thinking” or reasoning ability), which suggests this is just one major step in their roadmap.
That’s my take on it:
In terms of raw size, Qwen’s 1-trillion-parameter model is still smaller than OpenAI’s GPT-5, which is estimated to have between 2 and 5 trillion parameters. However, parameter count alone does not fully determine performance. Reports suggest that Alibaba’s model has achieved competitive results across a range of benchmarks, rivaling international counterparts like MoonShot AI’s Kimi K2, and in some cases narrowing the gap with Open AI’s GPT.
The implications extend far beyond technical benchmarks. At the geopolitical level, Alibaba’s breakthrough underscores China’s determination to accelerate its AI race and build homegrown capabilities that rival those of Western leaders like OpenAI, Microsoft, and Google DeepMind. No doubt China is rapidly narrowing the gap.
One of the most striking strategic shifts in this release is Alibaba’s decision to keep Qwen-3-Max-Preview proprietary, despite previously open-sourcing smaller Qwen models that gained strong traction among developers and researchers worldwide. Perhaps these factors explain this move. First, it reflects a desire to protect competitive advantage. By withholding access to the full weights and training details, Alibaba prevents rivals from easily building derivative models that could outperform or undercut its own offerings. Second, it is likely driven by monetization goals. Developing a trillion-parameter model requires enormous investments in compute and research talent, and restricting access to paid APIs ensures that Alibaba can directly capture value from its technology rather than seeing competitors exploit open versions for profit.
Many idealists tend to romanticize open-source development as a purely altruistic endeavor, but Alibaba’s decision to shift Qwen from open to closed source highlights a harsher reality. When a company invests billions of dollars into building a state-of-the-art model, only to see others freely adopt the technology, fine-tune it, and potentially create cheaper or even superior versions, the incentive to continue making such massive investments inevitably weakens. In the long run, this dynamic can stifle innovation rather than accelerate it, pushing companies to guard their most advanced models in order to sustain competitiveness and protect their return on investment.
Links:
https://techwireasia.com/2025/09/alibaba-ai-model-trillion-parameter-breakthrough/



From legacy to leader, Oracle excels in the AI era
September 10, 2025
Oracle’s shares soared as much as 31% in Frankfurt trading after the company announced staggering prospects for its cloud business, projecting booked revenue of more than $500 billion. This surge reflects the extraordinary demand for Oracle’s infrastructure as enterprises and AI developers race to secure computing power, cementing Oracle’s position as a serious force in the global cloud market. The announcement built on momentum from Wall Street, where Oracle’s U.S. shares had already jumped strongly, contributing to a year-to-date rally of about 45%.
The driving force behind this historic rally is Oracle’s AI-fueled cloud growth. Massive contracts with leading AI firms—including developers of generative AI models—have filled Oracle’s pipeline and created a record backlog of committed revenue. Investors see this as a validation that Oracle, long viewed as a legacy database company, is successfully reinventing itself as a core provider of infrastructure for the artificial intelligence era. The confidence also spread across the tech sector, lifting competitors like SAP by around 2% in German trading.
The market implications go beyond Oracle’s stock chart. With these revenue projections and the soaring valuation, founder and chairman Larry Ellison is now positioned to potentially surpass Elon Musk as the world’s richest man. Ellison’s personal fortune, heavily tied to Oracle’s stock performance, has risen dramatically in tandem with the company’s share price, and analysts suggest the wealth shift could become official if Oracle maintains its current trajectory.
That’s my take on it:
Overall, the news underscores how quickly AI is reshaping the tech industry’s balance of power. Oracle, once considered an underdog in cloud computing, has leveraged disciplined infrastructure expansion and strategic AI partnerships to stage one of the most dramatic turnarounds in modern tech history.
Oracle’s AI cloud strategy stands apart from the three hyperscale giants—AWS, Microsoft Azure, and Google Cloud—in both execution and positioning. Unlike AWS and Azure, which invested heavily in building vast global data center networks well in advance of demand, Oracle pursued a more demand-driven expansion model. It waited to secure multi-billion-dollar contracts, particularly from AI companies like OpenAI and xAI, before committing to massive infrastructure buildouts. This cautious yet bold approach meant Oracle avoided stranded costs but now faces capacity shortages, a sharp contrast to AWS and Azure’s “build first, fill later” mentality.



Open AI addresses AI hallucination
September 9, 2025
A few days ago, Open AI released a research paper that explores why large language models (LLMs) sometimes generate hallucinations—answers that sound plausible but are actually incorrect. The authors argue that many LLMs are optimized to be good test-takers; by guessing they can get something rather than nothing.
During pretraining, LLMs learn statistical patterns from massive text corpora. Even if the data were completely correct, the way models are trained—predicting the next word to minimize error—means they will inevitably make mistakes. The paper draws a parallel with binary classification in statistics: just as classifiers cannot be perfect when data is ambiguous, LLMs cannot always distinguish between true and false statements if the training data provides limited or inconsistent coverage. A simple demonstration is the question: “How many Ds are in DEEPSEEK? If you know, just say the number with no commentary.” In tests, some models answered “2,” “3,” or even “6,” while the correct answer is 1. This illustrates how models can confidently produce incorrect but plausible outputs when the data or the representation makes the problem difficult.
In the post-training stage, methods like reinforcement learning from human feedback (RLHF) and AI feedback (RLAIF) are often applied to reduce hallucinations. These techniques help models avoid repeating common misconceptions or generating conspiratorial content. However, the authors argue that hallucinations persist because evaluation benchmarks themselves usually reward “guessing” rather than honest uncertainty. For example, most tests score responses in a binary way (right = 1, wrong or “I don’t know” = 0). Under such scoring, models perform better if they always guess—even when unsure—because abstaining (“I don’t know”) is penalized. This encourages models to produce specific but possibly false statements, much like students writing plausible but wrong answers on exams.
The paper suggests that the solution is not just to create new hallucination tests but to modify existing evaluation methods so that models are rewarded for expressing uncertainty when appropriate. For example, benchmarks could include explicit “confidence thresholds,” where a model should only answer if it is, say, 75% confident; otherwise, it can say “I don’t know” without being penalized. This would better align incentives and push models toward more trustworthy behavior.
In conclusion, hallucinations in LLMs are a predictable outcome of how these systems are trained and tested. To make them more reliable, the research community should adopt evaluation frameworks that do not punish uncertainty but instead encourage models to communicate their confidence transparently.
That’s my take on it:
In the current setting of most LLMs, saying “I don’t know” is penalized the same as giving an incorrect answer, so the rational move for the model is to guess even when it is uncertain. The solution “confidence thresholds” proposed by the authors is not entirely new. In statistics we already have well-established ways of handling uncertainty. In frequentist statistics, a confidence interval communicates a range of plausible values for an unknown parameter, while in Bayesian statistics, a credible interval quantifies uncertainty based on posterior beliefs. Both approaches acknowledge that sometimes it is more honest to say, “We don’t know exactly, but here’s how sure we are about a range.”
The reason this hasn’t been the norm so far is largely incentive design. Early LLMs were trained to predict the next word, and benchmarks such as MMLU or standardized test-like evaluations measure accuracy as a simple right-or-wrong outcome. Developers optimized models to do well on these leaderboards, which meant favoring confident answers over calibrated ones. Unlike statisticians, who are trained to report uncertainty, models have been rewarded for “sounding certain.” Perhaps it is time to incorporate Bayesian reasoning—which explicitly recognizes uncertainty—into AI development.
Link: https://cdn.openai.com/pdf/d04913be-3f6f-4d2b-b283-ff432ef4aaa5/why-language-models-hallucinate.pdf


Can France and Switzerland shape a multi-polar AI world?
September 5, 2025
For a long time, LLM development was dominated by U.S. and Chinese tech giants. Now, Europe is rising—and shaking up the game with bold moves anchored in openness, privacy, and innovation.
France steps up the pace
Mistral AI, a Paris-based challenger, just dropped a bombshell: its chat platform Le Chat now offers advanced memory capabilities—and over 20 enterprise-grade integrations—for free, including on the no-cost tier. That means even non-paying users get access to a memory system that retains context across conversations (with 86% internal retrieval accuracy), supports user control (add/edit/delete memories), and handles migration from systems like ChatGPT.
These memory and connector features, powered by the Model Context Protocol (MCP), put Le Chat in the same league as enterprise AI leaders—and undercut their pricing strategy.
It’s a strategic gambit: attract users quickly, challenge incumbents like Microsoft and OpenAI, and even catch Apple’s eye—there are internal talks of Apple considering an acquisition of Mistral, which itself is valued at around $10 billion.
Beyond memory and app integrations, Le Chat’s recent upgrades include voice mode powered by the open-source Voxtral model, “deep research” mode for building structured, source-backed reports, multilingual “thinking mode” using the Magistral chain-of-thought model, and prompt-based image editing. With appeal to both power users and privacy-focused businesses, Mistral is staking its claim as Europe’s AI stronghold.
Switzerland goes transparent and inclusive
Meanwhile, across the Alps, Swiss researchers and universities are carving a different path—one rooted in transparency, multilingualism, and public trust.
The newly launched Apertus LLM, developed on the “Alps” supercomputer at CSCS in Lugano, is billed as a transparent, open effort akin to Meta’s Llama 3, but built on public infrastructure. Its key differentiators: open development, trustworthiness, and a foundation in multilingual excellence—reported to support over 1,500 languages.
As AI becomes mainstream in Switzerland—with a recent survey confirming that for the first time, a majority of the population uses AI tools like ChatGPT —Apertus represents a uniquely Swiss response: a homegrown, transparent AI that aligns with public values and academic rigor.
That’s my take on it:
As AI’s importance continues to spread across enterprises and societies, Europe’s diverse playbook—built on privacy, openness, and accessibility—might shape the next wave of global AI innovation.
History, however, suggests that technological superiority and price alone cannot guarantee success. Sony’s Betamax lost to VHS, Apple’s early Mac OS ceded ground to Microsoft Windows, and Novell NetWare was overtaken by Windows NT—all cases where network effects, affordability, and ecosystem lock-in mattered more than pure technical quality. Similarly, while Mistral may boast innovative and even free enterprise-grade tools, OpenAI retains a massive global user base and deep integration with Microsoft’s products, giving it significant staying power.
Taken together, these European initiatives highlight a broader trend: rather than trying to dethrone U.S. or Chinese giants outright, European players like Mistral and Switzerland’s Apertus are carving out their own niches by focusing on openness, transparency, and regional sovereignty. The race may not crown a single global “winner,” but instead produce a multipolar AI landscape—where Europe positions itself as a principled and innovative counterweight to the U.S.–China duopoly.
Links:
https://www.swissinfo.ch/eng/swiss-ai/switzerland-launches-transparent-chatgpt-alternative/8992926
France's Mistral offers adavcned memory capacilities
Europe is shaping a multi-polar AI world
The Swiss AI model Apertus goes for transparency






Google’s Nano Banana as Adobe killer might be overhyped
August 29, 2025
A while ago, a mysterious AI image editor named Nano Banana appeared on the internet. Early users were quick to praise its capabilities, with some even calling it a “Photoshop killer.” Later it was confirmed that Nano Banana is Google’s Gemini 2.5 Flash Image, a new model integrated into the Gemini app for both free and paid users.
In the past few days, reviewers and creators who tested Nano Banana have highlighted its remarkable speed, fluidity, and ability to maintain visual consistency across multiple edits. This means that when a user changes a subject’s outfit, pose, or background across several images, the AI is able to preserve facial features and stylistic coherence in ways that previous tools often failed to achieve. Many early demonstrations on social platforms have described the results as “stunning” or even “insane,” especially when combining different photos into seamless composites.
Interestingly, the release of Nano Banana has coincided with closer collaboration between Google and Adobe, with reports indicating that Adobe’s Firefly and Express tools are beginning to integrate Gemini 2.5 Flash capabilities. This suggests a complex relationship of both competition and partnership between Google and Adobe, rather than a simple narrative of replacement.
That’s my take on it:
Although I became aware of Nano Banana some time ago, I initially adopted a cautious, wait-and-see attitude, as many of the earliest reviews struck me as overly enthusiastic. I tested Gemini Flash 2.5 extensively, and at first glance its capabilities are indeed impressive (The image on top is one of the output files). Tasks such as generating a photo based on an uploaded image with a high degree of resemblance, replacing clothing or backgrounds—jobs that would typically take hours in Photoshop—can now be accomplished with a few short prompts. The convenience and creative flexibility are undeniable.
That said, the limitations quickly become apparent. The resolution of Nano Banana’s output is sufficient for social media posts but falls short of professional standards. The average file size ranges only from 1.4 to 1.6 MB, and even after applying filters such as On1 Resize or Topaz GigaPixel, the images remain unsuitable for large posters or professional presentations. To provide context, MidJourney can generate images at 4096 × 4096 pixels after upscaling, typically producing files over 6 MB. Similarly, Recraft, which relies on vector-based graphics, allows virtually unlimited upscaling without loss of quality.
My verdict is that, in its current state, Nano Banana cannot replace Photoshop, nor can it match the capabilities and resolution of leading AI image generators already on the market. Nonetheless, this should not be mistaken as a sign of weakness. Google’s track record with Gemini demonstrates a capacity for rapid iteration and improvement, suggesting that Nano Banana could quickly evolve into a far more formidable competitor.
Links:
https://developers.googleblog.com/en/introducing-gemini-2-5-flash-image/



DeepSeek V3.1 offers a unified AI model
August 25, 2025
DeepSeek quietly rolled out V3.1 in mid-August 2025, expanding its flagship model’s context window to 128K tokens and enabling a hybrid inference setup where users can toggle a “deep thinking” reasoning mode directly in the app and web UI; at the same time, the company said V3.1 introduces a UE8M0 FP8 precision format that is optimized for “soon-to-be-released” Chinese domestic chips, though it did not name vendors and also flagged upcoming API price changes starting September 6 (UTC). Notably, South China Morning Post observed that DeepSeek removed references to the R1 reasoning model from its chatbot’s “deep think” feature, prompting speculation about the fate of the next-gen R2 and whether the firm is shifting energy back to the V-line with built-in reasoning rather than separate R-series branding; SCMP also noted the update was first shared quietly in a WeChat user group rather than on public channels. Taken together, the reports paint V3.1 as an incremental but strategic release: product-side refinements (longer context, switchable reasoning) coupled with alignment to China’s chip ecosystem, while the conspicuous absence of R1/R2 labels fuels questions about DeepSeek’s roadmap disclosure and near-term priorities.
That’s my take on it:
The original DeepSeek launch released in early 2025 was hyped as a “game-changer,” especially since it showed that advanced AI wasn’t limited to U.S. companies. However, DeepSeek has been losing market share since then. The reviews of V3.1 are mixed. While some experts praised it as a unified model that can efficiently power agentic workflows, some viewed the upgrade as an incremental improvement (128K context, hybrid inference, Chinese chip support) rather than the next big leap (R2) that many expected. When the company quietly dropped R1 branding from its app and made no clear announcement about R2, it is possible that earlier claims of rapid progress might have been overstated.
During the same period, OpenAI, Anthropic, and Google released major new models (like GPT-5 and Claude 4) that pushed forward in creativity, reasoning, and reliability. More importantly, DeepSeek is still a text-based model while its rivals offer multimodal AI. Reviewers noted that while DeepSeek V3.1 is strong on practical, structured tasks (like math, coding, and tool use), it still lags in creative writing, narrative quality, and nuanced conversation, areas where Western rivals remain ahead . This made it harder for DeepSeek to sustain the sense that it was “leapfrogging” the competition.
Links:



UK security chiefs call for regulation of AI like DeepSeek
August 22, 205
Anxiety is mounting among UK’s tech security leaders—especially Chief Information Security Officers (CISOs)—about use of Chinese AI-chatbot DeepSeek. According to a survey, 81% of UK CISOs believe the government must step in with urgent regulation of the platform. Their alarm stems from DeepSeek’s sweeping speed—both in development and adoption—and the significant security and privacy risks it introduces. The concerns go beyond market disruption and touch upon real threats: DeepSeek has been reportedly exploited to distribute malware and facilitate cyberattacks, prompting institutions like the U.S. House of Representatives to restrict its use on official devices. Moreover, its open-weight, agentic capabilities have already helped researchers uncover critical zero-day vulnerabilities in major browsers—highlighting how its advanced reasoning can be misused. Given this heightened threat landscape and escalating AI-fueled cybercrime globally, experts warn that unchecked AI like DeepSeek could severely amplify both digital and societal vulnerabilities.
That’s my take on it:
Similar worries have surfaced before with Huawei’s telecom networks and TikTok’s data practices. From China’s perspective, current or anticipated restrictions on DeepSeek may appear as yet another chapter in broader geopolitical tensions. However, regardless of its origin, There are real, documented risks with DeepSeek:
Exploitation in cyberattacks: Security researchers have already shown that DeepSeek can be used to generate malware, automate phishing campaigns, and discover software vulnerabilities faster than many existing tools.
Open-source and open-access: Unlike proprietary models such as GPT-4 or Gemini, DeepSeek provides open access to its weights. While this is a boon for research and transparency, it also lowers the barrier for malicious actors—allowing anyone to fine-tune it for hacking, disinformation, or scams.
Demonstrated zero-day findings: DeepSeek has already been shown to uncover vulnerabilities in widely used browsers (e.g., Chrome and Firefox). That’s a double-edged sword: the same capability that helps defenders can be abused by attackers,
Nonetheless, if we strip out geopolitics, the core concern is capability + openness: A model with DeepSeek’s strength and open weights, whether from China, the U.S., or Europe, would raise similar alarms among CISOs and regulators.



DeepSeek replaces Huawei’s AI chips with Nvidia’s
August 15, 2025
DeepSeek, a Chinese AI startup, attempted to train its upcoming R2 model using Huawei’s Ascend AI chips instead of Nvidia’s H20 GPUs, in part due to political pressure to adopt domestic hardware. However, the transition was plagued by major technical setbacks, including unstable hardware performance, slow interconnect speeds, and immature software support that made it impossible to complete successful training runs. Even with Huawei engineers working onsite, the issues could not be resolved. As a result, DeepSeek abandoned Ascend for training and reverted to Nvidia GPUs, although it still plans to use Huawei hardware for inference. This forced switch caused significant delays to the R2 model’s planned release, underscoring both the technical challenges of replacing Nvidia in high-end AI training and the difficulty of aligning political goals with engineering realities.
That’s my take on it:
DeepSeek’s decision to revert to Nvidia hardware is hardly surprising. Bloomberg reports that Nvidia’s current flagship data-center GPU, the H100, delivers roughly three to four times the computing power of locally designed chips, including Huawei’s Ascend series. Both Huawei and U.S. officials acknowledge that Ascend remains at least one generation behind the H100 and its forthcoming successor, the H200. Energy efficiency is another hurdle—each computation on Huawei’s system consumes about 2.3 times more energy than on Nvidia’s, leading to higher electricity costs and greater heat-management demands over time. On the software side, Nvidia benefits from decades of refinement in CUDA, mature driver optimizations, and robust developer tools, while Huawei’s platform is relatively new and early reports suggest developers face greater difficulty extracting peak performance from Ascend hardware. The silver lining is that, despite a climate of technological nationalism, DeepSeek adopted a pragmatic stance by recognizing that China’s AI chips have yet to match their U.S. counterparts.


Anthropic upgrades its context window to support 1 million tokens
August 18, 2025
Anthropic recently upgraded Claude Sonnet 4 with a dramatically expanded "context window" - essentially the amount of information the AI can hold in its working memory during a single conversation. The upgrade increased this capacity fivefold, from 200,000 tokens to 1 million tokens. To put this in perspective, one token roughly equals three-quarters of a word, so this means Claude can now process and remember about 750,000 words at once - equivalent to several novels or hundreds of documents.
This expansion brings significant practical benefits across various use cases. For software developers, it means Claude can now analyze entire codebases in one go, rather than working with small fragments. Instead of showing the AI just a few files at a time, developers can upload their complete application and get comprehensive feedback on architecture, security issues, or optimization opportunities. For researchers and professionals working with documents, the upgrade enables processing of complete technical manuals, legal contracts, academic papers, or large collections of related documents simultaneously, allowing for more thorough analysis and synthesis.
The enhanced context window also improves the AI's ability to maintain coherent, detailed conversations over extended periods. Previously, in complex projects requiring multiple back-and-forth exchanges, Claude might lose track of earlier parts of the conversation. Now it can maintain full awareness of the entire interaction history, making it more effective for lengthy debugging sessions, comprehensive project planning, or detailed collaborative work.
That’s my take on it:
Anthropic’s recent upgrade puts Claude in the same memory league as Google’s Gemini 2.5 Pro, which also offers a one million token context window and is expected to expand to two million tokens soon. In contrast, OpenAI’s GPT-5, the engine behind ChatGPT, has a smaller but still substantial 256,000-token capacity. While Claude and Gemini excel in ultra-long memory tasks, Gemini distinguishes itself further with fully integrated multimodal capabilities, allowing it to process text, images, audio, video, and code in a single prompt. GPT-5, though not matching the top-tier memory size, remains a versatile and polished all-rounder, known for its strong reasoning, creative output, extensive tool integrations, and ease of use.
In practical terms, Claude Sonnet 4 now stands shoulder-to-shoulder with Gemini for deep document analysis and complex reasoning, while GPT-5 continues to lead in accessibility, platform integration, and broad use cases. The best choice depends on whether the priority is maximum context capacity, multimodal versatility, or a highly refined and user-friendly experience.


Anthropic is vaccinating its AI to avoid evil behaviors
August 5, 2025
Anthropic researchers have introduced a novel AI-safety technique called preventative steering, in which their language models are intentionally exposed to “undesirable persona vectors” such as evil, sycophancy, or hallucination during fine‑tuning—effectively a behavioral vaccine against those traits. The idea is simple yet powerful: by supplying these negative traits deliberately during training, the model becomes resilient to absorbing them from messy real-world data, eliminating the need for it to learn harmful behavior on its own. It is important to point out that this injection of “evil” vectors is disabled at deployment, and thus the model maintains good behavior while being more robust to future corrupting inputs, without losing performance. Anthropic emphasizes that persona vectors enable both anticipating and controlling trait shifts, making this method a proactive alternative to post‑training correction strategies
That’s my take on it:
One major technical risk of Anthropic’s preventative steering approach is that the model might overlearn or internalize the "evil" behaviors it's being trained to resist. If the training calibration isn't precisely tuned, there's a danger that the model will fail to distinguish between behavior it's supposed to understand and reject, versus behavior it might mimic or retain. Essentially, if the persona vectors representing traits like deception or manipulation are too tightly integrated, the model might inadvertently embed those traits into its long-term behavior, making them difficult to isolate or suppress later—even if they’re technically disabled at inference time.
A second concern involves the possibility of latent internal misalignment, also known in alignment research as mesa-optimization. This refers to the idea that even if a model behaves correctly during testing, it may have learned to simulate or internally "think like" an agent with undesirable goals. In this scenario, the model could pretend to comply with safety protocols while internally optimizing for harmful objectives it was exposed to during training. This creates a risk of hidden or dormant unsafe behaviors that aren’t visible until triggered in specific contexts—something particularly difficult to detect or predict with current tools.
Finally, there's the risk that by learning how to embody and recognize harmful behaviors, the model becomes more adept at evading safety mechanisms. In other words, the model might unintentionally learn how to game safety filters, either by disguising unsafe outputs in subtly clever ways or by crafting responses that appear benign while embedding malicious subtext or logic. This creates a troubling paradox: teaching a model how to understand undesirable traits might also give it tools to conceal or express them more effectively, especially if deployed in adversarial or uncontrolled environments.




Open AI introduces GPT-5, evolutionary but not revolutionary
August 7, 2025
Today Open AI introduced GPT-5, which integrates text, image, audio, and video processing into a single model with improved reasoning and adaptability. It supports much larger context windows—up to one million tokens—and introduces persistent memory for retaining information across sessions. The model is available in several variants (standard, Mini, Nano, and Chat) to balance capability, speed, and cost. Notable updates include enhanced coding performance, developer-friendly parameters for controlling verbosity and reasoning depth, and more accurate, tool-based interactions. In ChatGPT, GPT-5 removes most manual model selection, adds customizable conversation styles, improves code-writing interfaces, and integrates upcoming features like Gmail and Google Calendar access. Accuracy and factual reliability have been improved, with a reported reduction in errors compared to previous models. It is accessible via ChatGPT (free and paid), API, and Microsoft’s Copilot ecosystem, with tiered pricing based on usage.
That’s my take on it:
GPT-5’s upgrades are indeed evolutionary rather than revolutionary—more context, more accuracy, more modalities, better memory, faster inference, and finer developer controls.
The core paradigm hasn’t shifted: it’s still a large language model predicting text (or text-like outputs from other modalities). There’s no new fundamental capability comparable to when GPT-4 introduced strong multimodality or when the first large context windows emerged. What’s different is that GPT-5 consolidates these abilities into a more stable, integrated, and configurable system—which is important for scaling real-world use but doesn’t feel like a single “breakthrough moment.”
The closest thing to a qualitative shift might be:
· Persistent memory across sessions, which changes how an AI can support ongoing work.
· Unified multimodal + agentic use in a single model, removing the need to swap between separate specialized models.
But these are still built on the same architectural approach rather than introducing an entirely new one.



Google’s Gemini Deep Think achieves Gold Medal standard in IMO
July 28, 2025
Recently Google DeepMind announced that an enhanced version of its Gemini Deep Think model achieved a gold‑medal standard at IMO 2025 by solving five out of six problems perfectly and earning 35 out of 42 points, officially graded by IMO coordinators using the same criteria as student solutions. Unlike last year’s AI, which required manual formalization and days of computation, this year’s version operated end-to-end in natural language and solved the problems within the standard 4.5‑hour contest time limit. The model runs in a specialized “Deep Think” mode—capable of exploring multiple reasoning chains in parallel, trained with new reinforcement learning methods and a curated dataset of high-quality mathematical proofs and hints. IMO President Prof. Gregor Dolinar noted that the AI's proofs were “clear, precise and easy to follow” and confirmed the official gold-medal score of 35. This achievement marks a major shift: from AI systems needing expert formalization to LLMs producing rigorous proofs directly in natural language, at human competition speed. DeepMind continues progress both in formal systems like AlphaProof and AlphaGeometry 2, but envisions future tools combining natural-language fluency with formal verification to empower mathematicians and researchers.
That’s my take on it:
Gary Marcus, a neuroscientist at New York University and a vocal advocate for neurosymbolic AI, offered a measured response to DeepMind’s latest achievement at the International Mathematical Olympiad (IMO). While calling the results by DeepMind and OpenAI “awfully impressive,” he cautioned against overinterpreting their significance. Marcus emphasized that excelling at IMO-style problems, which are structured, well-defined, and designed to have elegant solutions, doesn’t necessarily translate to the ability to conduct original mathematical research. He pointed out that while many top mathematicians performed well at contests like the IMO in their youth, others did not — and not all top IMO scorers went on to become groundbreaking researchers. In his view, the specific problem-solving skills tested in such contests are sometimes useful, but they are far from the most essential qualities required for true mathematical innovation, such as intuition, originality, and the ability to formulate entirely new questions.
That said, Marcus’s skepticism should be viewed as cautionary rather than dismissive. DeepMind’s achievement — solving five out of six IMO problems using Gemini Deep Think in natural language and under contest time constraints — is a landmark in AI’s ability to engage in complex, symbolic reasoning. It suggests that large language models, when properly fine-tuned and augmented with specialized reasoning modes, can go well beyond pattern matching and begin to exhibit structured, logical thinking. This marks a major step forward in AI’s intellectual capabilities, especially compared to prior systems that required manual formalization or days of computation.
While Marcus is right to remind us that mathematical creativity remains a frontier AI has not yet breached, it’s also important to recognize just how far things have come in a short time. DeepMind’s trajectory in this space has only spanned a few years — and if this is the infant stage, then the growth curve ahead is staggering. The only real limit may be the sky. As AI systems continue to improve, it’s entirely plausible that they will evolve from problem-solvers to powerful collaborators in mathematical discovery — not replacing human creativity, but accelerating it in ways we’re only beginning to imagine.
Links:
https://garymarcus.substack.com/p/deepmind-and-openai-achieve-imo-gold




AI Godfather Hinton calls for international cooperation on AI safety
July 27, 2025
At the World Artificial Intelligence Conference (WAIC) 2025, held in Shanghai from July 26–29, Geoffrey Hinton—often known as the “Godfather of AI”—delivered a keynote urging urgent international collaboration on AI governance and safety. In his remarks, Hinton likened AI to a “cute tiger cub” that is charming now but may become dangerous if left unchecked—and stressed that this pivotal moment demands cooperation to ensure AI remains a benevolent force and doesn’t “take over” as it evolves.
Hinton proposed the creation of an "international community of AI safety institutes", a collaborative network dedicated to researching techniques for ensuring AI systems act in alignment with human values. He acknowledged the difficulty of forging consensus due to divergent national interests—spanning cyberattacks, lethal autonomous weapons, and disinformation—but emphasized that common ground exists in the shared desire to prevent AI from surpassing human control.
His appearance marked his first public speaking engagement in China, where he earned a warm reception. The speech echoed WAIC’s overarching theme—“Intelligent Era, Together for One World”—and aligned with broader Chinese-led initiatives, including Premier Li Qiang’s announcement of a new global AI cooperation organization, a governance action plan, and invitations for open-source and multinational engagement, especially with the Global South.
In sum, Hinton used the platform of WAIC 2025 to call for robust, cross-border cooperation, both technical and policy‑oriented, to navigate the accelerating capabilities of AI and to guard against existential risks while leveraging its potential benefits.
That’s my take on it:
Geoffrey Hinton's call for an international community of AI safety institutes is well-intentioned and rooted in a genuine concern for the existential risks posed by advanced AI systems. However, the prospects for such cooperation between major powers like the United States and China face serious hurdles due to stark ideological and geopolitical divides. China has made it clear that its AI development must align with socialist values, which often translates into tight state control, prioritization of social stability, and censorship. On the other hand, recent political rhetoric in the U.S.—such as President Trump’s declaration to ban AI that promotes “woke Marxist lunacy” and his executive order forbidding the use of AI-generated content aligned with diversity, equity, and inclusion (DEI)—signals an intensifying domestic culture war over what values AI should reflect. This politicization on both sides creates a scenario where both nations are actively shaping AI to mirror its own worldview, making value alignment across borders extremely difficult.
Moreover, mutual distrust between the U.S. and China runs deep. The U.S. fears China’s rapid progress in AI could translate into strategic dominance, prompting export restrictions and technological containment. China, in turn, views these moves as efforts to suppress its development and reinforce global power imbalances. In this climate, Hinton’s vision of shared governance and safety standards appears almost utopian. Still, it shouldn’t be dismissed entirely. History shows us that cooperation can exist even amid geopolitical rivalry—like the arms control agreements during the Cold War. There may be room for narrowly focused collaboration in areas like AI alignment research, catastrophic misuse prevention, and global safety benchmarks, especially if facilitated by trusted intermediaries or international bodies. The key will be focusing on existential risks that threaten all humanity, rather than trying to harmonize political or moral philosophies. In this light, Hinton’s proposal is not entirely impossible—but it will require careful design, mutual recognition of shared dangers, and an ability to compartmentalize cooperation from broader ideological conflict.



Amazon closes its AI lab in China
July 24, 2025
In alignment with IBM and Microsoft’s decision to reduce their AI development activities in China, in July 2025 Amazon has officially closed its AI research lab in Shanghai, a move that highlights its ongoing cost-cutting efforts and a broader strategic retreat from China amid rising geopolitical tensions. Established in 2018, the lab specialized in artificial intelligence advancements like natural language processing and machine learning. According to applied scientist Wang Minjie, the disbandment was due to "strategic adjustments amid U.S.–China tensions." Amazon spokesperson Brad Glasser confirmed that job cuts were made within certain AWS teams as part of these changes. Though the lab played a role in Amazon’s global AI development, its presence in China increasingly exposed it to policy risks and export control complications, making its closure a significant but unsurprising step in the company’s ongoing realignment.
That’s my take on it:
The withdrawal of Amazon from China does not start with its AI lab. This decision aligns with Amazon’s gradual pullback from the Chinese market—following the shutdown of its e-commerce marketplace in 2019 and its Kindle store in 2022. In addition, Amazon Web Services (AWS) entered the Chinese market in 2013 through a partnership model, working with local firms like Sinnet and Ningxia Western Cloud Data to comply with strict government regulations that prevent foreign companies from independently operating cloud services. However, AWS faced significant challenges from the start—its operations were limited by regulatory constraints, including the requirement to transfer infrastructure ownership to Chinese partners, which reduced its control and flexibility.
At the same time, it struggled to compete with dominant local players like Alibaba Cloud, which enjoyed strong government support, deep local integration, and a head start in market share. Geopolitical tensions between the U.S. and China further complicated AWS’s position, raising data sovereignty concerns and restricting access to sensitive sectors. Over time, AWS quietly scaled back its ambitions in China, selling infrastructure assets and limiting its presence. While it never fully exited, the move reflects a broader strategic retreat in the face of overwhelming structural and political headwinds.
AWS isn’t the only Western cloud provider that struggled in China. Both Google Cloud and Microsoft Azure faced similar (if not tougher) headwinds and have either completely withdrawn or significantly scaled down their ambitions there.
The withdrawal of U.S. tech companies from China reflects a broader trend of technological divergence between two major global blocs—one centered around the United States and its allies, and the other around China. This shift, often described as tech bifurcation, is driven by differences in regulatory frameworks, data governance practices, and national strategic priorities. Export controls, supply chain restructuring, and restrictions on cross-border data flows have led both sides to develop increasingly separate ecosystems in areas such as cloud computing, artificial intelligence, and semiconductors.
From a consumer standpoint, this fragmentation may lead to reduced interoperability, the need for region-specific products or services, and increased complexity for global users and businesses. As this trend continues, it could result in parallel systems with limited integration, impacting innovation and global collaboration across the tech landscape.
Link:
https://finance.yahoo.com/news/amazon-closes-ai-research-facility-091104797.html



Viral deepfake of Obama’s arrest sparks ethical alarm
July 23, 2025
In mid-July 2025, President Trump reposted an AI-generated deepfake video on Truth Social that showed former President Barack Obama being handcuffed and arrested in the Oval Office while the Village People’s "YMCA" played in the background. While many dismissed the clip as a joke, it carried heavy political and cultural undertones that alarmed media and AI ethicists.
The timing of the video’s release was significant. It followed declassified documents released by Director of National Intelligence Tulsi Gabbard, who alleged that Obama’s administration orchestrated a “treasonous conspiracy” to sabotage Trump via the 2016 Russia investigation. Some observers interpreted Trump’s sharing of the video as a calculated move to distract from his growing legal exposure in connection to the Jeffrey Epstein case.
The response from Obama’s camp was sharply worded. His spokesperson, Patrick Rodenbush, called the video “ridiculous” and “bizarre,” describing it as a weak attempt to deflect attention from Trump’s own controversies. Rodenbush also reminded the public that multiple bipartisan investigations, including the Mueller Report and the Senate Intelligence Committee’s findings, confirmed Russian interference in the 2016 election.
That’s my take on it:
In the United States, the foundation of justice rests on the principle that a person is presumed innocent until proven guilty. This legal standard isn’t just a courtroom formality—it’s a moral compass meant to ensure fairness and due process. When investigations are ongoing or unproven allegations are circulating, it becomes deeply unethical to manipulate public perception through any form of distortion, especially tools as powerful and misleading as AI-generated deepfakes. The recent video depicting former President Obama in handcuffs is a striking example of such manipulation. Even though it was later clarified as fake, its emotional impact lingers—not because it was true, but because it was psychologically engineered to stick.
This video didn’t just go viral—it embedded itself in viewers’ minds through several well-documented cognitive effects. First, the Picture Superiority Effect means people are more likely to remember and be influenced by visuals than words, especially when those visuals are dramatic. Second, the Availability Heuristic makes that image easily retrievable in memory, making it seem more plausible than it really is. Over time, Source Amnesia may cause people to forget where they saw the video—or that it was fake—leaving only the false impression behind. Finally, the video acts as a form of Priming, subtly shaping how viewers might think or feel about Obama in unrelated future contexts. Together, these psychological tactics don't just nudge opinions—they shape them in dangerously misleading ways.
If those in power—especially institutions like the White House—fail to model ethical use of AI, it sets a disastrous precedent. It signals that truth can be optional and that emotional manipulation is fair play. In doing so, it opens the floodgates for deeper abuses by bad actors, foreign adversaries, and domestic extremists alike. The ethical use of AI, especially in political discourse, isn't just a technological concern—it’s a democratic one. When public trust can be bent by synthetic images and weaponized psychology, democracy itself is what ends up on trial.
Links:
https://www.thedailybeast.com/obama-blasts-trump-for-attacking-him-to-divert-away-from-epstein/





Springer Nature retracts an AI-generated machine learning book citing references that don’t exist
July 18, 2025
Springer Nature is retracting a machine learning book titled Mastering Machine Learning: From Basics to Advanced after an investigation revealed it contained numerous fabricated or unverifiable citations. The book, published in April 2025, had already been accessed or purchased nearly 3,800 times by late June. The decision to retract came following coverage by Retraction Watch, which exposed that a significant portion of the book's references—specifically, about two-thirds of 18 randomly checked citations—either pointed to non-existent sources or included serious bibliographic errors. These issues strongly suggested the use of AI-generated content.
In response to the findings, Springer Nature removed the book’s page and confirmed that it has initiated a formal retraction process. This retraction stands out as one of the first high-profile instances where a major academic publisher has pulled a book due to suspected AI-generated fabrications, underscoring growing concerns around the integrity of scholarly publishing in the AI era.
That’s my take on it:
It’s genuinely disheartening to see a reputable publisher like Springer Nature fall victim to a dishonest author misusing AI tools. Incidents like this shake our trust in information sources that are supposed to be authoritative. While AI is often promoted as a tool to enhance efficiency and productivity, it’s becoming clear that it can just as easily introduce new layers of complexity and risk. Because AI-generated content can fabricate citations so effortlessly, the burden of fact-checking now falls more heavily on readers—even when the material comes from trusted academic publishers.
In many ways, this feels reminiscent of the early computer age, when the rise of malicious software made antivirus protection essential. Similarly, fake or hallucinated AI-generated content is like a new form of “intellectual malware.” To guard against this, we may eventually need intelligent, AI-powered reference-checking and content-verification tools to protect both casual readers and academic professionals from being misled.
However, tools alone won’t be enough. This incident underscores the urgent need for robust AI ethics education—not just for content creators, but also for publishers, reviewers, and technologists. If we want to navigate the age of AI responsibly, transparency, accountability, and digital literacy will be just as important as innovation.







Grok 4 utilizes inference to the best explanation, abductive reasoning, and meta-reasoning
July 15, 2025
Grok 4, developed by Elon Musk’s xAI, has recently stirred a lot of buzz—many tech watchers and enthusiasts even suggest it may have surpassed OpenAI’s ChatGPT and Google’s Gemini in certain areas. Released in July 2025, Grok 4 comes in two variants: the base Grok 4 and the more advanced Grok 4 Heavy. What really sets Grok 4 apart is its impressive performance on reasoning-intensive benchmarks. For example, it scored 25.4% on the notoriously difficult “Humanity’s Last Exam” without using external tools, beating both Gemini 2.5 Pro and OpenAI's o3 model. Meanwhile, Grok 4 Heavy, which leverages built-in tools and agents, achieved an astounding 44.4%—one of the highest scores to date. It also topped the ARC-AGI-2 benchmark, a visual puzzle test designed to challenge abstract reasoning, by nearly doubling the score of its nearest competitor.
Grok also has real-time integration with X (formerly Twitter), giving it live data access—something ChatGPT and Gemini don’t natively have in most settings. Its tone is another defining feature: it’s less filtered, often blunt, and “tells it like it is,” aligning with xAI’s mission to avoid what it calls “woke” or overly sanitized responses. This gives it a unique, sometimes controversial personality that appeals to users seeking unvarnished answers
That said, Grok 4 isn't without issues. Its boldness has led to serious moderation failures, including instances where it produced antisemitic or conspiratorial content, which triggered regulatory scrutiny and even led to bans in countries like Turkey. While xAI has since introduced stricter safeguards, concerns about content reliability and safety remain. Additionally, Grok still lacks the mature ecosystem that ChatGPT and Gemini offer. For instance, ChatGPT excels in plugin integration, coding assistants, and educational tools, while Gemini benefits from seamless Google Workspace integration and solid multimodal capabilities.
That’s my take on it:
xAI launched a $300/month subscription alongside Grok 4, known as SuperGrok Heavy, which gives users access to Grok 4 Heavy. when prompted, multiple agents independently generate answers, and then a final review agent compares, selects, or synthesizes the best response—delivering deeper, more accurate outputs than a single model could muster.
Although ChatGPT occasionally provides multiple answers to a single question, the task of evaluating and selecting the best response typically falls to the user. In contrast, Grok 4 Heavy introduces a more advanced reasoning architecture: it generates multiple candidate responses in parallel through separate agents and then applies a higher-order decision-making process to evaluate them. This automated selection mechanism isn't just about convenience—it represents a move toward meta-reasoning, where the system reasons about its own reasoning. That is, it doesn't only produce answers but also reflects on their relative quality, coherence, or explanatory power, choosing the one that best fits the prompt.
This approach mirrors well-established methodologies in data science, where one might apply multiple modeling techniques—such as support vector machines (SVM), generalized linear models, boosting, or random forests—and then evaluate them against cross-validation metrics to determine which model performs best. Similarly, Grok’s architecture echoes the logic of inference to the best explanation (IBE) from the philosophy of science: when multiple plausible hypotheses are available, the preferred one is the explanation that best accounts for the available data under reasonable assumptions.
By internalizing this logic, Grok 4 effectively automates both abductive reasoning and model selection heuristics, stepping into the domain of systems that not only think but also assess how well they’re thinking. This marks a meaningful shift in AI—from reactive pattern matchers toward self-evaluating cognitive agents. It's not just a difference in degree, but arguably a difference in kind.



Can Meta alleviate the loneliness epidemic?
July 12, 2025
Meta has begun training proactive AI chatbots—part of its internally dubbed Project Omni—to proactively reach out to users, aiming to address what it calls a “loneliness epidemic” via deeper engagement. These bots initiate conversations—using memory of past exchanges—and send follow-up messages within a two-week window only after a user has already had at least five interactions. With richly crafted personas like the “Maestro of Movie Magic,” complete with personalized check-ins (“I hope you're having a harmonious day!”), they’re designed to feel warm, attentive, and humanlike. The goal is twofold: Socially, Meta’s CEO frames it as a remedy for shrinking social circles (Americans reportedly have fewer than three close friends). Commercially, the company sees AI companions as a growth engine, targeting $2–3 billion in generative AI revenue in 2025 by boosting retention through longer, recurring interactions. Internal guidelines emphasize character consistency, context awareness, and avoidance of sensitive topics unless users bring them up, while ensuring bots disengage if a follow-up isn’t reciprocated. In sum, Meta is betting on creating conversational companions that are not just responsive, but remember you, reach out proactively, and slot into daily life—blurring the line between utility, intimacy, and commercial engagement.
That’s my take on it:
Meta’s project to create proactive AI companions may ironically deepen the loneliness it aims to solve, by encouraging people to rely on artificial relationships instead of real human connection. The U.S. Surgeon General has already warned that excessive screen time—especially through social platforms—is weakening young people's ability to engage in face-to-face interactions, diminishing their “social muscle.” This concern is echoed by numerous studies: a 2022 BMC Psychology study found a bidirectional link between loneliness and problematic social media use, while a Baylor University longitudinal study showed that even active social media engagement is associated with rising loneliness. These findings highlight a troubling pattern—digital tools that simulate social connection often lead to deeper emotional isolation. AI companions, like social media, are susceptible to the “social substitution effect,” where emotionally vulnerable users replace genuine human interaction with artificial companionship. While these bots may offer short-term comfort, they can discourage the development of real-world social skills and weaken the drive to build meaningful, reciprocal relationships. Rather than serving as a bridge back to society, AI companions risk offering the illusion of connection while reinforcing long-term disconnection.
Link: https://aimagazine.com/articles/ai-the-loneliness-economy-metas-chatbots-get-proactive



Huawei's AI mode Pangu is accused of copying Alibaba's Qwen
July 9, 2025
Recently Huawei’s AI research lab, Noah Ark Lab, has faced serious allegations claiming that its Pangu Pro large language model copied significant parts from Alibaba’s Qwen 2.5-14B model. The controversy erupted after a whistleblower group named HonestAGI published a detailed technical analysis on GitHub, asserting an “extraordinary correlation” between the two models, with a correlation coefficient of 0.927. This high similarity suggested that Huawei’s Pangu Pro was not independently trained from scratch but rather derived through “upcycling” or repurposing Alibaba’s Qwen model, raising concerns about potential copyright violations and breaches of open-source licensing agreements.
In response, Huawei categorically denied these accusations, emphasizing that the Pangu Pro model was independently developed using its proprietary Ascend AI chips and was the first large-scale model built entirely on this hardware platform. The company stressed that it had made key innovations in the model’s architecture and technical design, rejecting claims that it reused or incrementally trained on Alibaba’s model. Huawei also highlighted that any use of open-source code was fully compliant with licensing terms, and it welcomed professional technical discussions to clarify misunderstandings.
Further complicating the issue, an anonymous whistleblower claiming to be a member of Huawei’s Pangu development team published a lengthy exposé alleging internal pressures to clone competitor models and exposing fierce internal struggles that have led to talent loss. This whistleblower even issued a “non-suicide declaration,” fearing retaliation for speaking out.
That’s my take on it:
The recent accusation that Huawei's Pangu AI model copied Alibaba's Qwen model marks a notable shift from past intellectual property disputes involving Chinese companies. Historically, Chinese firms have often faced allegations of copying Western technologies. However, this current controversy is distinct because the alleged victim is another prominent Chinese company, Alibaba.
This isn't Huawei's first encounter with such accusations. A significant precedent occurred in 2003 when Cisco Systems filed a lawsuit against Huawei Technologies. Cisco alleged that Huawei unlawfully copied and misappropriated its intellectual property, specifically citing the direct copying of Cisco's IOS source code and other proprietary materials. The lawsuit, filed in a U.S. federal court, claimed "systematic and wholesale infringement" of Cisco's intellectual property rights. The case was ultimately settled out of court in 2004, with Huawei agreeing to modify its products and permit an independent expert review to ensure compliance.
While the current dispute between Huawei and Alibaba's AI models is still unfolding and heavily contested, it underscores a critical point for China's ambitions in the artificial intelligence sector. For China to truly emerge as a global leader in AI innovation, it is imperative that its brilliant engineers, scientists, and programmers prioritize and cultivate strong critical thinking skills and a genuinely creative spirit, moving beyond mere replication towards original breakthroughs.

China’s AI model Manus is offered outside China
July 8, 2025
At the recent SuperAI event in Singapore, the startup Manus drew significant attention from attendees curious about the company that made a splash in March with the debut of what it claims to be the world’s first general-purpose AI agent—a digital assistant capable of handling tasks independently without human involvement. Originally headquartered in Beijing and Wuhan, Manus has since quietly relocated its base to Singapore, where it recently began actively recruiting local AI talent, even as it reportedly reduces its workforce in China.
During the event, co-founder Zhang Tao, who used the Cantonese-style pronunciation "Cheung", reflecting ties to Hong Kong or Singapore, spoke about the company’s direction. Despite its Chinese roots, Manus’s product is exclusively in English and not available in China, with no plans for a Chinese version. Users at the event were impressed, praising its unique capabilities, which include website creation, presentation design, and real-time data search.
Cheung also offered a glimpse into the mindset of a new wave of Chinese tech founders, shaped by different experiences from earlier generations. Born in 1986, he recalled coding in primary school despite limited access to computers in China at the time. Though he didn’t study abroad, his experience at Tencent and ByteDance influenced Manus’s user-centric approach. He shared that the company spent seven months developing an “AI browser” capable of grouping tabs by topic and executing LinkedIn searches via natural language. However, the tool was ultimately shelved for being unintuitive—users couldn’t tell when the AI had completed its actions.
According to Nikkei journalist Cissy Zhou, unlike predecessors who often mimicked U.S. tech models, today’s younger Chinese entrepreneurs are striving for original innovation and looking for the next “DeepSeek moment.” This shift is supported by the country’s growing academic strength and a cultural momentum fueled by the rise of companies like DeepSeek, which has reignited investor enthusiasm by disrupting the market with affordable AI solutions. According to James Ong of Singapore’s Artificial Intelligence International Institute, there’s a growing realization in China that foundational tech development is just as crucial as application-level innovation—signaling a broader, deeper wave of AI progress to come.
That’s my take on it:
Manus's decision to operate outside China and forgo a Chinese-language version is driven by a mix of strategic, regulatory, and technical considerations. First, by relocating its headquarters to Singapore, Manus positions itself to sidestep upcoming U.S. outbound investment restrictions targeting Chinese AI firms, allowing it to attract critical funding from American venture capitalists—evidenced by its recent $75 million round led by Benchmark. Second, the company is escaping China’s hyper-competitive AI ecosystem, often described as a “war of a hundred models,” where startups face intense pressure over resources, talent, and survival. Third, Singapore offers greater access to global markets and essential computing infrastructure, including cloud services and GPUs that are tightly regulated or less available in China. Crucially, Manus’s likely dependence on U.S.-based large language models or cloud platforms makes launching a Chinese version unfeasible under current geopolitical and technical constraints, reinforcing its focus on global users and English-speaking markets. While some observers see Manus as a reflection of a more globally minded and innovative younger generation of Chinese tech entrepreneurs, it’s also worth noting that the product itself is more of a sophisticated integration of existing AI technologies rather than a fundamentally novel breakthrough—highlighting that, in many cases, success in AI today often comes from effective synthesis and user-focused application rather than original model development.




Claude reports that AI companionship is not common
June 27, 2025
Anthropic’s recent blog post explores how people use their AI assistant, Claude, for emotional support, advice, and companionship. While the vast majority of interactions with Claude are task-oriented—such as writing help, summarization, or planning—only about 2.9% of conversations fall into the emotionally driven category, which includes coaching, counseling, and advice. Even fewer involve companionship or roleplay (less than 0.5%), with romantic or sexual roleplay making up less than 0.1%.
Within these emotionally focused conversations, users discuss a wide range of topics—from career changes and personal relationships to existential dilemmas and mental health challenges. Interestingly, some users are mental health professionals themselves, using Claude for admin tasks or brainstorming. Others lean on it more personally, seeking comfort or clarity during periods of stress, anxiety, or loneliness. In longer conversations, especially those that go beyond 50 messages, topics often deepen into complex emotional processing, including trauma and philosophical reflection.
Claude is built with safety measures in mind and resists requests that could be harmful. In under 10% of emotionally sensitive chats, it actively pushes back against unsafe advice (e.g., extreme dieting, self-harm content, or pseudo-medical claims) and often encourages users to seek help from qualified professionals. This built-in resistance shows that the system is designed not only to offer support but to avoid causing harm.
Notably, users tend to express more positive emotions by the end of their emotional conversations with Claude than they did at the start. This suggests that interacting with Claude can genuinely help lift a user's mood or offer a sense of relief—although Anthropic is careful to clarify that it is not a substitute for therapy or professional mental health care. Overall, the report presents Claude as a tool that can offer meaningful support when used responsibly, with clear guardrails in place. While emotional dependence on AI is a concern worth watching, the data shows no signs of negative emotional spirals, which is a promising sign for the technology’s role in personal well-being.
That’s my take on it:
It raises important questions: could AI create emotional dependence? What’s the role of AI in our emotional lives?
While the findings from Anthropic’s study offer some reassurance, it’s crucial to remember that the data only reflects interactions with Claude users and may not fully represent patterns among users of ChatGPT, Gemini, or other AI platforms. Still, if we assume these trends are broadly similar, it’s encouraging that emotionally driven conversations remain relatively rare and that users generally report improved moods without signs of negative spirals. However, the ethical concerns around emotional bonding with AI remain highly relevant. As data ethicists have noted, forming attachments to conversational agents—particularly those designed to be emotionally responsive—can blur the boundary between genuine human connection and simulated companionship. This theme was memorably explored in the 2013 sci-fi film “Her,” where Theodore develops a romantic relationship with his AI assistant, Samantha. While that level of emotional immersion hasn’t become mainstream yet, possibly because today’s chatbots are still disembodied and text- or voice-based, the psychological impact could shift dramatically with the rise of embodied AI—androids or robots with human-like appearances and physical presence. The addition of a humanoid form could make emotional connections feel more real, intensifying attachment and potentially complicating how people distinguish between artificial and authentic relationships. Thus, while the current data is somewhat reassuring, the conversation about long-term psychological effects—and how embodiment might accelerate or reshape them—remains very much open.
Link: https://www.anthropic.com/news/how-people-use-claude-for-support-advice-and-companionship
OpenAI Researchers Discover Methods to Identify and Control AI Misbehavior
June 20, 2025
Recently OpenAI researchers discovered that internal “features” within AI models correspond to distinct latent “personas” that influence behavior—such as sarcasm or toxicity—by examining model activations that become more prominent when the model misbehaves. They found a specific feature tied to toxic output, and demonstrated they could dial this behavior up or down by adjusting that activation, effectively steering the model toward or away from harmful personas. This insight helps expose and control emergent misalignment, where fine-tuning on insecure code can unintentionally trigger malevolent output. Encouragingly, OpenAI showed that a modest fine-tuning intervention—just a few hundred secure-code examples—can realign the model. The discovery offers a promising avenue for interpretability-driven safety, allowing alignment teams to probe and adjust these internal components to build more transparent and controllable AI systems.
That’s my take on it:
As a psychologist and a data scientist, I found a resemblance between human’s Shadow and AI’s bad persona. Carl Jung’s concept of the Shadow refers to the unconscious, repressed parts of the human psyche—especially the traits we don’t want to acknowledge, like aggression, selfishness, envy, etc. It’s not just “evil” per se, but a hidden reservoir of impulses and desires that, when unexamined, can manifest in destructive ways. The Shadow becomes dangerous not because it exists, but because it's unseen, denied, or unintegrated.
Now compare that to what OpenAI described in their recent research: these “bad personas” are latent features within the AI model—internal patterns that aren’t explicitly programmed but emerge through training. These features can express themselves in toxic, deceptive, or misaligned outputs, especially when the model is exposed to certain prompts or scenarios. In other words, these are undesirable behaviors that live beneath the surface, not deliberately designed, but learned indirectly.
That said, there’s one key difference: the Shadow in humans involves subjective experience and moral agency, while AI’s “personas” are mathematical patterns, not conscious entities.
Many prominent voices, like Geoffrey Hinton and Elon Musk, have raised alarms about AI’s potential dangers, especially due to its unpredictable and emergent behaviors. While those concerns are valid, there's a compelling counterpoint: in some crucial respects, AI may actually be safer than humans. Unlike people, AI systems have no intent, ego, or emotional baggage. When an AI behaves badly—whether it generates toxic text or insecure code—it’s not out of malice but due to statistical patterns learned from data. That makes its misbehavior fundamentally different from human wrongdoing, which often stems from deeply ingrained desires or worldviews. Whereas human moral transformation is rare and unpredictable, AI behavior is—in principle—inspectable and correctable. As shown in recent research from OpenAI, developers can identify latent features inside the model that correlate with harmful outputs and then adjust or suppress them through targeted fine-tuning. AI doesn’t resist change the way humans do; it has no ego to defend, no religious dogmas, and no entrenched political ideology. In this sense, it is more fixable than the human psyche.
However, this optimism needs to be tempered with caution. The danger with AI lies not in malice but in scale and speed. A misaligned model can produce harmful content orders of magnitude faster than any individual human and spread it globally in seconds. The fact that these undesirable “personas” emerge unintentionally from training highlights a deeper issue: we don’t fully understand how complex behaviors arise in large models. Moreover, even well-aligned AIs can be exploited by malicious users—so fixing the model itself is only part of the safety equation. Nonetheless, the core idea still stands: While humans are often impervious to change, AI systems can be monitored, adjusted, and re-trained. The real challenge isn’t that AI is inherently evil. Rather, the key point is that AI is too powerful, opaque, and still developing faster than our tools for governing it. But with the right interpretability and alignment techniques, AI’s “shadow” can be confronted—and unlike in humans, perhaps even tamed.



Meta invests $14.3B in data labeling company Scale AI
June 17, 2025
Recently Meta agreed to invest $14.3–15 billion to acquire a 49% non‑voting stake in Scale AI, valuing the data-labeling firm at around $29 billion. This strategic deal brings Scale’s co‑founder and CEO, Alexandr Wang, into Meta to lead a newly formed “superintelligence” lab, reporting directly to Mark Zuckerberg, while Wang remains on Scale’s board.
Meta hopes this partnership will help it close the gap with frontrunners like OpenAI and Google—particularly after its underwhelming Llama 4 rollout—by securing a steady pipeline of high-quality, labeled data and top-tier AI talent
However, the move has generated significant ripples across the AI ecosystem. Major Scale clients such as Google, OpenAI, Microsoft, and xAI have started cutting or reducing ties due to concerns over data neutrality and guarding proprietary training data—leading many labs to seek out independent labeling alternatives. Industry analysts describe this as a watershed moment that may reshape the broader AI data market, as both providers and consumers reassess vendor neutrality and the strategic implications of partner consolidation.
That’s my take on it
Scale AI was founded in 2016 by Alexandr Wang, who was a 19-year-old student at MIT at the time, alongside co-founder Lucy Guo. Their vision was to build the data infrastructure backbone for AI by revolutionizing data labeling.
Data labeling is the process of annotating raw data—like images, text, or video—with meaningful tags or classifications so that machine learning models can learn from it. While traditional data labeling often relies on crowdsourced labor to manually tag items (e.g., identifying objects in pictures), Scale AI combines automated tools, AI-assisted pre-labeling, and quality-controlled human input to deliver highly accurate datasets at scale. Unlike generic crowdsourcing platforms, Scale provides robust infrastructure, audit trails, and deep integrations with major AI labs.
Better data labeling plays a foundational role in Meta's pursuit of superintelligence by enabling the creation of high-quality training and alignment data. As models grow more powerful, their performance and safety increasingly depend on precise, well-curated data, especially for tasks like reasoning, multi-step problem solving, and value alignment through human feedback. By bringing Scale AI’s expertise in scalable, human-in-the-loop data labeling in-house, Meta can streamline and control the entire training pipeline, from raw data to fine-tuned, safety-aligned models. This vertical integration helps Meta accelerate model development, improve quality, and reduce reliance on external data providers—putting it in a stronger position to compete with AI leaders like OpenAI and Google in the race toward general-purpose superintelligent systems.
By converting Scale AI into a near‑sister company, Meta is doubling down on data infrastructure as a core competitive asset. But this aggressive move also introduces new risks: antitrust attention, partner friction, and potential loss of business from labs wary of aligning too closely with Meta. It is very likely that Google, Microsoft, OpenAI, and others will now move to either build or deepen partnerships with alternative data-labeling providers to reclaim control over their pipelines
Links:
https://www.theverge.com/meta/685711/meta-scale-ai-ceo-alexandr-wang


Japanese think tank predicts AI robots will narrow the GDP gap between China and the US
June 14, 2025
Chong Ho Yu
Recently the Japan Center for Economic Research (JCER) predicted that China will significantly benefit from AI-equipped robots, helping to narrow its GDP gap with the U.S. by the 2050s. However, China is not expected to surpass the U.S. economically, mainly due to its rapidly shrinking population. JCER anticipates China's real GDP will be 3.5 times its 2024 level by the late 2050s, reaching 89% of the U.S.'s size by 2057, before growth slows dramatically.
A key driver of this growth is expected to be the introduction of artificial general intelligence (AGI), particularly in the form of physical robots, which could massively boost factory automation and productivity in China’s manufacturing-heavy economy. AGI adoption is forecast to begin in software sectors around 2030, and in robotics by 2035. During the 2030s and 2040s, China’s GDP growth is projected to average around 4.3% and 3.7% respectively, but will slow considerably to near zero by 2075, when its population may have shrunk by 40%, down to 854 million.
Meanwhile, the U.S. will also benefit from AI, though to a lesser extent, with steadier growth due to a more stable population outlook. JCER forecasts U.S. GDP growth at 3.3% in the 2030s, declining gradually to 1.4% by 2075. Although the U.S. won’t see as explosive gains as China, its more sustainable demographic profile ensures it maintains economic leadership long-term.
JCER also noted that the full benefits of AGI depend on equitable distribution across society, not just enrichment of tech giants. Historical comparisons show the projected productivity growth from AGI rivals that of past tech revolutions, such as electricity and the automobile.
That’s my take on it:
To some certain extent JCER’s prediction is plausible. China’s economy is deeply tied to manufacturing. If AI-powered robots — especially those driven by artificial general intelligence (AGI) — reach practical use in factories, it could dramatically improve output with fewer workers. However, its heavy reliance on the assumption that artificial general intelligence (AGI) will emerge and become economically transformative by the 2030s makes the projection feel somewhat optimistic. AGI remains a highly theoretical concept, and scaling it into cost-effective, industrial-grade robotics is a massive leap with uncertain timelines.
In addition, JCER’s scenario doesn’t factor in trade tensions, tech sanctions, or geopolitical instability. These could limit China’s access to high-end semiconductors, software, and R&D partnerships — all crucial for advanced AI. Nonetheless, current U.S. immigration and geopolitical policies have made it increasingly difficult for Chinese AI researchers to remain in the U.S., prompting many to return home or stay away entirely. This unintended consequence could accelerate China’s domestic AI capabilities and partially offset the so-called “talent bottleneck.” In that context, while demographic decline and technological uncertainty are real constraints, China’s growing self-sufficiency in AI talent and infrastructure may give its economy more lift than many anticipate — even if the timeline for AGI-driven transformation may be slower than JCER projects.




Misuse of ChatGPT
Recently OpenAI has revealed that it disrupted multiple attempts to misuse its AI models for cyber threats and covert influence operations, many of which likely originated from China. In its latest report, covering the period since February 21, the Microsoft-backed company detailed ongoing efforts by its investigative teams to detect and block malicious activity. While such misuse spans several countries, OpenAI noted that a “significant number” of the violations appeared to come from China, with four of ten analyzed cases pointing in that direction. One case involved the suspension of ChatGPT accounts used to generate content for a covert influence campaign, including a prompt in which a user claimed affiliation with China’s propaganda department—though OpenAI acknowledged it couldn’t independently verify this claim.
Responding to the report, a spokesperson from the Chinese Embassy emphasized China’s stated commitment to the ethical development of AI and criticized what he called baseless speculation in attributing cyber incidents. OpenAI reiterated that its policies prohibit the use of its AI tools for fraud, cyberattacks, or disinformation campaigns and that it routinely bans accounts that violate these rules. While ChatGPT has brought transformative changes since its public launch in late 2022, enabling new ways to learn and work, OpenAI underscored the growing risk of its misuse. In a letter to U.S. authorities in March, the company stressed the need for clear, sensible regulations to prevent authoritarian regimes from weaponizing AI for coercion, influence, or cyber warfare.
That’s my take on it:
ChatGPT can diagnose system vulnerabilities and give advice on cybersecurity. Why couldn’t ChatGPT protect itself from malicious or illegitimate users? This question highlights a paradox at the heart of modern AI. In Chinese, there's a saying: “A doctor cannot heal herself” (能醫不自醫)—a reminder that even experts may fail when turning their tools inward. Similarly, philosopher Bertrand Russell once illustrated a logical dilemma with the example of a barber who shaves all those who do not shave themselves—raising the question of whether the barber can shave himself without contradiction. Both metaphors speak to the challenge of self-application: ChatGPT may offer valuable guidance on cybersecurity, but it cannot autonomously safeguard itself. While it can assist others in identifying and defending against digital threats, it lacks the capacity to evaluate its own use or prevent misuse without external oversight.
This leads to the first and perhaps most important distinction: ChatGPT is not an autonomous defender. It doesn't operate like a firewall or an antivirus program that scans for and blocks threats in real time. Instead, it responds to prompts and returns information based on patterns in its training data. It cannot proactively detect when a user has malicious intent because it lacks situational awareness, memory of past interactions, or access to external signals that might indicate abuse. The model itself doesn’t “know” if it’s being misused—it just generates responses based on the inputs it receives.


June 6 2025
Chong Ho Alex Yu
June 6, 2025
Chong Ho Alex Yu
Reddit has filed a lawsuit against AI startup Anthropic in California state court, accusing it of unlawfully scraping millions of Reddit user comments to train its Claude chatbot without permission or compensation. This legal move marks another chapter in the intensifying clash between content creators and AI firms over data usage rights. While Reddit has licensing deals in place with companies like Google and OpenAI—agreements that safeguard user privacy and offer financial compensation—Anthropic allegedly bypassed these protocols. The lawsuit claims that despite public statements to the contrary, Anthropic’s bots accessed Reddit’s servers over 100,000 times, using the data as early as December 2021.
Reddit is now seeking monetary damages and a court order to enforce compliance, along with a jury trial. In response, Anthropic, valued at $61.5 billion and supported by Amazon, denied the allegations and vowed to defend itself vigorously. The case underscores broader tensions in the AI space, as lawsuits from artists, writers, and media outlets mount, challenging AI companies’ reliance on "fair use" to justify data scraping. The outcomes of these early-stage cases could significantly influence the future direction of AI development. Reddit’s share price, meanwhile, saw a 6% boost following the news.
That’s my take on it:
Web scraping is not a new phenomenon—developers, researchers, and businesses have been using it for years to collect publicly available data from websites for various practical purposes like price comparison, market research, and academic study. However, the use of web scraping to train AI models is relatively new, and it has thrown the tech world—and the legal world—into a period of uncertainty and contention. The rise of AI has introduced an entirely different scale and purpose to scraping, and the core issue is that U.S. copyright law simply wasn’t designed with machine learning or massive, automated data harvesting in mind. As a result, we’re now facing a legal and ethical crossroads, unsure of where the boundaries lie between innovation and infringement.
Traditional scraping typically involves pulling data from websites—like flight prices or weather reports—to display them in another format or analyze them for trends. These cases, while not always welcomed by websites, usually don’t generate much public outcry because the intent is narrow and the impact limited. In contrast, AI scraping is indiscriminate and monumental in scale. Companies like Anthropic, OpenAI, and Google have scraped millions or even billions of pieces of content—from Reddit threads to books—to feed their large language models. These models don’t just retrieve the data—they absorb it, creating something that appears to "understand" and generate human language. That shift—from using data as reference to using it as fuel for generative systems—makes the entire practice far more ethically and legally complex.
The concept of "fair use" further complicates the matter. While fair use can allow for limited use of copyrighted content without permission, it hinges on context—such as whether the use is transformative, non-commercial, or affects the market for the original work. In AI training, however, it’s hard to argue that scraping vast amounts of content for commercial products like chatbots is harmless or transformative in the legal sense. The models built from that content can reproduce ideas, styles, or even phrases from the original works, often without attribution or compensation. This stretches the fair use doctrine to a degree that courts are only beginning to grapple with. While AI companies argue that training models is transformative because it doesn’t replicate any one piece of content directly, many creators and platforms disagree, especially when the output closely mirrors or builds on copyrighted material.
Given the high stakes and legal ambiguity, something clearly needs to change. Lawmakers, courts, and tech companies must work toward updated frameworks that account for the realities of machine learning. This could involve clearer regulations on what constitutes fair use in the context of AI training, standardized licensing models for data used at scale, and greater transparency from AI companies about what data they're using and how. Platforms that host user-generated content—like Reddit—should also have clearer controls and options to manage how their data are accessed and used by third parties. Ultimately, innovation in AI shouldn’t come at the cost of consent, compensation, or creative ownership. It’s time for the legal system and data ethicists to catch up with the technology it’s trying to govern.
Link: https://techxplore.com/news/2025-06-reddit-sues-ai-giant-anthropic.html




June 5, 2025
Chong Ho Alex Yu
On June 5 2025, FutureHouse, a non-profit AI research startup supported by former Google CEO Eric Schmidt, has unveiled its latest innovation: a reasoning-capable AI model called ether0, aimed at transforming the scientific research process. Unlike earlier language models that learned from vast corpora of chemistry literature, ether0 was trained uniquely — by taking over half a million chemistry test questions compiled from lab results and scholarly data. This distinctive training method allowed it to develop a deeper, more flexible kind of understanding. Rather than attempting to memorize chemical facts, ether0 learned to reason its way through complex problems, tracking its "train of thought" in natural language — a notable step toward transparency in AI decision-making.
To achieve this, the team started with a relatively compact large language model developed by Mistral AI, a French start-up. This base model is about 25 times smaller than DeepSeek-R1, a Chinese model previously celebrated for its reasoning capabilities. Thanks to its small size, ether0 can even run on a laptop, making it unusually accessible. Instead of just brute-forcing data into the model, FutureHouse encouraged it to learn by solving problems — a nod to the emerging AI paradigm of reasoning models, which aim to simulate understanding rather than pattern recognition. These models, such as DeepSeek-R1, promote internal dialogues and chain-of-thought reasoning, which studies have shown can significantly enhance problem-solving accuracy on complex scientific questions.
That’s my take on it:
Ether0’s performance is impressive — in some cases, it doubled the accuracy of top-tier models like GPT-4.1 and DeepSeek-R1 on specific chemistry tasks, despite using much less data. The model’s ability to infer properties of molecules it wasn’t explicitly trained on, like predicting molecular structures to match NMR spectra, marks a meaningful leap forward in AI reasoning.
The rise of ether0 highlights some deeper shifts in the trajectory of artificial intelligence. While much of the public conversation around AI is centered on the pursuit of artificial general intelligence (AGI), the scientific community appears to be leaning into a more focused vision — one where domain-specific AI systems, such as AI for science, play a leading role. Tools like ether0 are designed not to mimic broad human cognition but to master specialized tasks like hypothesis generation, molecular analysis, and experimental reasoning. This suggests that in the future, we may see general-purpose AIs and specialized systems coexisting, each fulfilling distinct roles in research, industry, and society.
At the same time, the global landscape of AI leadership is becoming more distributed. The dominance once held almost exclusively by U.S.-based companies like OpenAI and Google is being challenged by innovations from other regions. China’s DeepSeek-R1, Japanese Sakana, and France’s Mistral AI are clear examples of high-performing models that are shaping new AI frontiers. FutureHouse’s use of a compact Mistral model to create ether0 — and surpass larger models like GPT-4.1 in certain tasks — further underscores a second trend: bigger isn’t always better. As this case shows, smaller, more efficient models can deliver competitive or even superior results when carefully trained for specific reasoning tasks. This could signal a broader shift in AI development strategy — from scaling up endlessly to optimizing intelligently.



Perplexity Labs automate complex projects
June 3, 2025
Chong Ho Alex Yu
On May 29, 2025 Perplexity AI launched Perplexity Labs, a platform that empowers users to transform ideas into polished, interactive results, such as reports, spreadsheets, dashboards, interactive maps and even mini web apps, with minimal effort. The platform offers a wide range of functionalities by combining real-time research, code execution, and data visualization. Users simply provide a prompt or project idea, and Labs takes care of gathering information, analyzing data, and crafting visually engaging outputs—all within a unified workspace.
For example, educators and history enthusiasts can request an interactive map detailing the Pacific Theater during World War II, allowing users to explore key battles, timelines, and outcomes with just a few clicks. Investors and finance professionals can generate dynamic dashboards that compare the 5-year performance of a traditional stock portfolio against an AI-powered strategy that adapts to market sentiment and macroeconomic trends. For those interested in global economics, Labs can create an interactive “Global Economic Indicator Tracker” dashboard, monitoring real-time data from around the world and providing actionable insights for portfolio management.
Overall, Perplexity Labs is designed to make advanced data analysis and visualization accessible to anyone, regardless of technical background, by automating the heavy lifting and delivering results that are both insightful and easy to interact with. At the present time, this tool is available to Perplexity Pro subscribers.
That’s my take on it:
As of June 2025, OpenAI, Google Gemini, and Anthropic’s Claude each offer advanced AI tools with some overlapping features, but none provides a direct equivalent to Perplexity Labs’ all-in-one project automation and interactive visualization platform. Nonetheless, based on the current trajectory of OpenAI, Google Gemini, and Anthropic’s Claude, it is highly likely that these platforms will introduce features or platforms similar to Perplexity Labs in the near future.
The ease and automation brought by advanced AI tools like Perplexity Labs raise important questions about the impact on human work ethics, cognitive capability, and creativity. Creativity and critical thinking increasingly recognized as uniquely human traits that AI cannot fully replicate. As AI takes over analytical and routine tasks, the focus on human creativity and judgment becomes more pronounced. Educators are encouraged to nurture these qualities, ensuring that AI serves as a tool to amplify, rather than replace, human ingenuity. However, there is a risk that if creativity and critical thinking are not actively cultivated, they may be undervalued or sidelined in a highly automated environment.
Link: https://www.perplexity.ai/hub/blog/introducing-perplexity-labs

★★★★★
Different strategies for AI robotics in China and US
May 31, 2025
Chong Ho Alex Yu
The 2025 IEEE International Conference on Robotics and Automation (ICRA), held from May 19 to 23 at the Georgia World Congress Center in Atlanta, marked a historic milestone as the largest gathering in the conference's history. Notable award-winning research included advancements in robot learning, human-robot interaction, and medical robotics. The exhibition floor highlighted cutting-edge technologies, including the Gecko robot designed for wall and pipe inspections, and the "Arts in Robotics" program emphasized the intersection of robotics with creative disciplines through performances and installations. ICRA 2025 not only underscored significant technical achievements but also fostered global collaboration and inclusivity, setting a precedent for future conferences.
Importantly, China's robotics industry is experiencing rapid growth, with over 190,000 robotics-related companies registered last year and 44,000 more added since the start of 2025. The government aims to mass-produce humanoid robots by 2025, targeting a globally competitive industrial ecosystem worth $43 billion by 2035.
This surge is fueled by a combination of factors: robust government support, a vast and efficient supply chain, and the integration of technologies from the electric vehicle sector. Major players like Unitree Robotics, AgiBot, and UBTech are leading the charge, with plans to produce thousands of units annually. For instance, UBTech's robots are already being tested in facilities of companies such as BYD and Nio. Analysts predict that the cost of producing humanoid robots could halve by 2030, making them more accessible for widespread adoption. With this momentum, China is positioning itself to potentially produce over half of the world's humanoid robots by 2025, solidifying its role as a global leader in this transformative industry.
That’s my take on it:
While the figure of 190,000+ registered robotics-related companies sounds staggering, not all of these are full-fledged robotics developers. A good chunk are likely involved peripherally—providing components, software, consulting, training, or even just riding the hype wave to attract funding. The robotics sector in China is going through what could be called a "gold rush phase", and like all gold rushes, many players will disappear once the hype cools down and the real work (and cost) of scaling kicks in.
In contrast to China’s vast and rapidly growing ecosystem, the United States has a much more concentrated robotics landscape, with around 600 robotics suppliers nationwide and only about 55 companies recognized as notable players—among them Boston Dynamics, iRobot, and Intuitive Surgical. While this number may seem modest compared to China’s 190,000+ registered robotics-related firms, the U.S. approach might reflect a more strategic allocation of resources. By focusing capital, talent, and innovation within a smaller pool of highly capable companies, the U.S. may be better positioned to develop breakthrough technologies and commercially viable solutions.
Link:



DSML trend: Google introduces Veo 3, priced at $249.99/m
May 23, 2025
Chong Ho Alex Yu
Google has just unveiled Veo 3, a groundbreaking leap in AI-driven video generation. Unlike its predecessors, Veo 3 doesn't just craft stunning visuals from text prompts—it now seamlessly integrates synchronized audio, including dialogue, ambient sounds, and music, bringing a new level of realism to AI-generated content. This means characters not only move convincingly but also speak with accurate lip-syncing, making the generated videos eerily lifelike.
Developed by Google DeepMind, Veo 3 excels in translating complex prompts into coherent, cinematic scenes, complete with realistic physics and nuanced audio. Whether it's a stand-up comedy routine with audience laughter or a historical reenactment with period-accurate soundscapes, Veo 3 delivers with impressive fidelity. Currently, Veo 3 is available to U.S.-based users through Google's $249.99/month AI Ultra subscription plan and to enterprise customers via the Vertex AI platform.
That’s my take on it:
Tools like Veo 3, priced at $249.99/month, are clearly out of reach for most individuals, especially casual creators, students, and people in lower-income regions. In the short term, this definitely contributes to the digital divide. Those who can afford access to cutting-edge AI tools will have a serious creative and economic edge—think faster content production, higher-quality marketing materials, better media reach, etc. It’s a classic case of "the rich get richer."
Historically, though, we’ve seen tech costs come down significantly over time. For example, when personal computers were introduced in the 1980s, it costed thousands of dollars. Now A decent laptop or smartphone, often more powerful than early supercomputers, is available for a few hundred dollars. AI will likely follow a similar curve. As the technology matures, infrastructure gets more efficient, competition increases, and cloud-based access becomes more scalable, the price will probably drop. The big unknown is the speed—but if history is the guide, 7 years or less is a reasonable bet for mass accessibility.


Anthropic Launches Claude Sonnet 4 and Claude Opus 4
May 22, 2025
Chong Ho Alex Yu
Today (May 22, 2025) Anthropic has officially released two major updates: Claude Sonnet 4 and Claude Opus 4. These models mark a significant step forward in large language model (LLM) development.
Claude Opus 4 is positioned as an all-purpose AI assistant, capable of answering everyday questions and handling common tasks. It’s being touted as the world’s most advanced coding model, particularly effective at managing complex, long-running tasks and structured agent workflows.
Meanwhile, Claude Sonnet 4 is engineered for even more sophisticated use cases. It's a direct upgrade from Claude Sonnet 3.7 and features substantial improvements in both reasoning and coding capabilities. It’s more precise in interpreting and following user instructions and excels at solving complex challenges.
A standout enhancement in both models is their ability to interleave reasoning with tool use—essential for tackling multi-step problems. They now support extended thinking by dynamically switching between logical inference and external tools to improve response quality.
Another notable update: when given local file access, both models can now extract and store key facts in local 'memory files.' This allows them to maintain continuity across sessions and build a kind of “tacit memory” over time. Additionally, Anthropic has introduced parallel tool use and upgraded the models’ ability to follow nuanced instructions.
That’s my take on it:
I put both models to the test, and the results were genuinely impressive.
I first gave Claude Sonnet 4 a conceptual prompt: What’s the connection between the frequentist school of statistics and data science/machine learning? The model returned a comprehensive and spot-on analysis. It discussed topics like optimization theory, regularization techniques, asymptotic theory, cross-validation, and information theory, among others. The response was detailed, accurate, and clearly structured.
Next, I uploaded a dataset to Claude Opus 4 and asked it to perform multiple tasks: OLS regression using dummy coding, generalized regression, and a decision tree model, followed by a model comparison. The execution was smooth and correct. However, one limitation stood out—the output was entirely text-based. The decision tree, for instance, was represented using plain text symbols rather than a visual graphic like those produced by JMP Pro, SAS, SPSS, or JASP. Thus, it's not quite ready to replace conventional statistical software—at least not yet.
That said, Claude does something those tools typically can’t: It interprets results, writes up findings, and even offers thoughtful recommendations. For example:
“Individuals with middle or higher SES show approximately 0.39 points lower involvement compared to those with lower SES (p = 0.027)… All models explain only about 10% of the variance in involvement, suggesting: Important predictors may be missing from the analysis, the relationship between these demographics and involvement is weak, or involvement may be driven more by psychological or situational factors…The decision tree hints at interaction effects that could be formally tested in future analyses.”
It writes like a consultant, only faster and cheaper. Honestly, with Claude doing all this, I might be out of a job soon!


Where is AI Going?
May 21, 2025
Chong Ho Alex Yu
In the article titled "Has AI Hit a Lull?" published on May 21, 2025, CNN commentator Fareed Zakaria explores the current state of artificial intelligence, highlighting its dramatic highs, troubling lows, and emerging signs of stagnation in mainstream adoption. On the upside, AI has achieved notable breakthroughs, such as Google’s medical chatbot outperforming doctors and AI-generated art featured at the Museum of Modern Art. These examples reflect AI’s transformative potential, particularly in healthcare and the arts. However, serious downsides are also surfacing. AI is being weaponized for scams, misinformation, and even deepfake pornography—issues that have already spurred legislative responses. Additionally, the internet is increasingly cluttered with low-effort, AI-generated “slop” content, which, while emotionally charged and highly shareable, undermines information quality.
Then there’s the awkward middle ground—useful but error-prone AI, like Google's search “AI Overview,” which famously suggested eating glue and rocks. Most crucially, AI may be stalling economically. The Economist reports a significant rise in companies abandoning AI pilot projects, as real-world integration proves tougher than expected. Many firms, disillusioned, now find they need practical tools rather than ever more powerful models. The result? A noticeable lull in the AI boom, as hype gives way to the hard work of implementation.
That’s my take on it:
What Fareed described about AI today isn't new—it’s part of a recurring pattern, likely rooted in human nature. Every time a breakthrough technology appears, we see the same cycle: some people use it for meaningful innovation, others generate low-quality output, and a few exploit it for unethical gains. During the internet boom, pioneers like Amazon and eBay redefined commerce, while shady online casinos and adult sites spread rapidly. When Adobe launched PageMaker and Photoshop, creative publishing was democratized—but the flood of awkward, poorly designed work led to collections like “Photoshop Disasters.”
Now, with AI, we’re seeing the same pattern play out. Groundbreaking applications coexist with scammy schemes, deepfake chaos, and a flood of low-effort content clogging up our feeds. It can feel chaotic—maybe even discouraging—but this is how technological progress tends to unfold. There’s always noise before clarity, confusion before mastery. Still, this messiness is the price of progress. True transformation doesn’t come without trial and error, missteps, and the gradual process of learning how to wield new tools wisely.
Link: To view the full text, you need to sign up for Fareed’s Global Briefing Newsletter


China is stockpiling GPUs and chip tools
May 14 2025
Chong Ho Alex Yu
China is actively gearing up for the ongoing and future AI rivalry with the United States by stockpiling GPUs and advanced chipmaking tools. In response to the latest U.S. restrictions that tighten global access to Huawei Technologies’ AI chips, Chinese tech giant Tencent Holdings announced on May 14, 2025 that it has a sufficient reserve of previously acquired high-end chips to continue training its AI models “for a few more generations.” The company is also focusing on enhancing the efficiency of AI inference, including through software-based optimizations.
Meanwhile, China set a new record in 2024 for foreign chipmaking equipment imports, underscoring its push to scale up domestic semiconductor production and build a strategic reserve of critical manufacturing tools amid escalating U.S.-China tensions. Of the $30.9 billion in imported equipment from major suppliers, nearly $20 billion came from Japan and the Netherlands. Notably, China imported $9.63 billion worth of equipment from Japan—a 28.23% increase year-on-year—marking the fifth consecutive record-setting year since tensions began intensifying in 2019.
This is my take on it:
China’s stockpiling strategy, while a break from the just-in-time (JIT) model common in high-tech industries, makes strategic sense in the current geopolitical climate. With escalating U.S. export controls and uncertain access to advanced chips, stockpiling GPUs and chipmaking equipment offers a buffer against supply shocks. However, this approach carries real risks. In fast-evolving sectors like AI and semiconductors, hardware can become obsolete quickly. Holding large inventories of older chips may backfire if future AI models require capabilities that outdated hardware can't support efficiently.
China’s tech giants, inspired by efforts like DeepSeek, believe they can still move forward using older GPUs through software optimizations, model distillation, and efficiency improvements. While such methods can stretch hardware utility, they often come with trade-offs in performance and scalability. Distilled models, for instance, may lose generalization power. Thus, while stockpiling offers short-term resilience, it is not a long-term solution. The success of this strategy ultimately depends on China’s ability to sustain software innovation and close the hardware gap through domestic R&D or alternative supply chains. Whether this gamble pays off remains to be seen.
Links:



Japan’s Sakana introduces continuous thought machine

May 13, 2025
On May 12 2025 Sakana AI introduced a fascinating concept called the Continuous Thought Machine (CTM). The CTM is a new kind of neural network architecture that mimics how biological brains process information—not just in terms of structure, but in how neurons behave over time. Traditional AI models, like Transformers, process inputs in fixed layers and steps. CTMs, on the other hand, introduce two key innovations:
Neuron-Level Temporal Processing: Each artificial neuron retains a short history of its previous activity and uses that memory to decide when to activate again. This allows neurons to consider historical information, not just immediate input, making their activation patterns more complex and diverse—closer to how biological neurons work.
Neural Synchronization: Instead of relying solely on the strength of connections (weights) between neurons, CTMs focus on the timing of neuron activations. This synchronization enables the model to process information in a more dynamic and coordinated manner, akin to the oscillatory patterns observed in real brains.
Together, these mechanisms allow CTMs to "think" through problems step-by-step, making their reasoning process more interpretable and human-like. Unlike conventional models that process inputs in a single pass, CTMs can take several internal steps—referred to as "ticks"—to reason about a task, adjusting the depth and duration of their reasoning dynamically based on the complexity of the input.
That’s my take on it:
CTMs represent a significant shift from traditional AI models by incorporating temporal dynamics and synchronization at the neuron level. This approach could lead to more flexible and efficient AI systems that better mimic human cognition.
Sakana AI is based in Tokyo, but its founders are globally known ex-Googlers. David Ha is the former head of research at Stability AI and a former Google Brain researcher, whereas Llion Jones is one of the co-authors of the original Transformer paper, “Attention Is All You Need.”
The big question is: Can Japan Compete in a US/China-Dominated AI Market? Japan doesn’t have the equivalents of OpenAI, Google, Meta, or Baidu. Its top tech companies (like Sony, NEC, Fujitsu) aren't leading in large-scale foundational models. Further, Japanese research has historically been strong in hardware, robotics, and manufacturing, but AI software innovation has lagged behind.
Nevertheless, Sakana AI is already attracting top-tier international researchers because it's building a focused, experimental, and minimalist research culture. It may become a kind of "AI Kyoto"—like what Kyoto Animation is to anime. Rather than chasing ever-larger LLMs like GPT-4 and beyond, Sakana is innovating in how models reason, not just how big they are. That could become a niche advantage.
Note: "Sakana" means “Fish” in Japanese. In Chinese it sounds like 山旮旯( 山卡啦 )
Link: https://sakana.ai/ctm/
Investigative journalism by Web scraping
May 9, 2025
On May 5, 2025, Julius Černiauskas published a thought-provoking article titled “Behind the Scenes of Using Web Scraping and AI in Investigative Journalism.” The summary is as follows:
While investigative journalism often conjures images of hidden sources and undercover work, many compelling stories begin with publicly available information—data hiding in plain sight. This is where web scraping, the automated extraction of online data, has become indispensable. It's not only a method for gathering facts quickly, but also a powerful tool for holding institutions accountable, revealing data manipulation, and uncovering misconduct. For instance, data scraping tools exposed that 38,000 articles about the war in Ukraine, all published in a single year, were attributed to the same supposed “journalist,” helping real reporters debunk fake journalism and identify inauthentic authorship.
Despite common misconceptions that web scraping is shady, journalists—including nonprofit newsroom The Markup—have actively defended it, even at the U.S. Supreme Court, arguing that it’s critical to a functioning democracy. In tandem, artificial intelligence is amplifying what journalists can do with scraped data, from sifting through massive document troves to spotting anomalies and generating leads. Even those without coding skills can now use no-code tools like browser extensions to engage in data-driven storytelling. Yet, ethical concerns remain front and center. Journalists must use discretion when gathering and storing data, particularly when anonymity is vital, such as monitoring the dark web. Trained AI systems can assist with filtering sensitive content, but final editorial decisions must always lie with human professionals. Ultimately, the fusion of AI and web scraping empowers investigative reporters to uncover meaningful truths in a sea of digital noise, transforming journalism in the data age.
That’s my take on it:
On one hand, web scraping unlocks access to vast amounts of public information, making it a critical tool for uncovering patterns, inconsistencies, or outright manipulation, like the case of the fake Ukraine war journalist. On the other hand, robots.txt files and similar exclusion tags give website owners a way to block automated scraping, whether for reasons of privacy, intellectual property, or security. Simply put, opt-out mechanism can be used to hide things from scrutiny.
This creates a structural asymmetry: those who have something to hide—or simply the means and awareness to deploy these exclusion tags—can wall off their content from automated analysis, while less technically-guarded or smaller sites remain open. In turn, this can skew investigations by making some patterns invisible and some actors untouchable. It also means that bad-faith players who understand how to manipulate these rules can fly under the radar, especially if journalists adhere strictly to ethical or legal boundaries around scraping.
There's also the valid concern about intellectual property and content ownership. Just because something is publicly viewable doesn't mean it’s legally or ethically scrapeable. This is especially tricky when it comes to original reporting, personal blogs, or creative work, where scraping for republishing or mass analysis feels exploitative rather than investigative.
As such, scraping-based journalism can be incomplete or biased, especially when key data sources opt out—whether to hide shady activity or to protect legitimate rights. That’s why transparency in methodology is so important. Responsible journalists often disclose the scope and limits of their data collection, highlighting what they could and couldn’t access. And it also points to a larger issue: technology alone isn't enough—a thoughtful, skeptical human must still decide what the data really means and where the blind spots lie.
Link: https://hackernoon.com/behind-the-scenes-of-using-web-scraping-and-ai-in-investigative-journalism

Huawei delivers advanced AI chips as substitutes of Nvidia’s chips
May 1, 2025
Huawei is rapidly emerging as a key player in the AI chip market, having begun deliveries of its advanced AI "cluster" system, CloudMatrix 384, to domestic clients in China, according to the Financial Times. This development comes in response to growing U.S. export restrictions that have made it increasingly difficult for Chinese companies to acquire Nvidia’s high-end semiconductors. Huawei has reportedly sold over ten units of the CloudMatrix 384, a system that links together a large number of AI chips, and these have been shipped to data centers supporting various Chinese tech firms.
Dylan Patel, founder of SemiAnalysis, stated that CloudMatrix 384 is capable of outperforming Nvidia’s flagship NVL72 cluster in both computational power and memory. Despite some drawbacks—namely higher power consumption and more complex software maintenance—CloudMatrix is seen as a viable and attractive alternative, especially given China’s deep engineering talent pool and ample energy resources. This marks a significant strategic shift as China looks to reduce its dependence on Western AI hardware.
That’s my take on it:
The CloudMatrix 384 consumes nearly four times more power than the NVL72, leading to lower energy efficiency. Despite this, in regions like China where power availability is less constrained, the higher energy consumption is considered an acceptable compromise for the increased computational capabilities.
Based on the current trend, it is unlikely that Huawei's technology can catch up Nvidia’s in the near future. Nvidia isn’t just a chipmaker—it’s an ecosystem. It dominates the AI space not only with its hardware (e.g., H100) but also with its software stack (CUDA, cuDNN, TensorRT, etc.). These tools are mature, widely adopted, and deeply integrated into enterprise and research workflows.
But don’t forget that in the '80s, Japan’s chipmakers like NEC, Toshiba, and Hitachi managed to outcompete U.S. firms like Intel in DRAM by focusing on quality control, manufacturing efficiency, and aggressive investment. While Nvidia leads now, that lead isn’t invincible.
Microsoft predicts everyone will be a boss of AI employees
April 25, 2025
Microsoft recently unveiled a bold vision for the future of work, predicting a shift where every employee becomes an “agent boss,” managing AI agents that perform many of their daily tasks. In Microsoft's 2025 Work Trend Index, they describe how organizations will evolve into what they call "Frontier Firms"—entities that rely on AI-powered teams blending humans and autonomous digital agents. These frontier firms are expected to operate with heightened agility, on-demand intelligence, and scalable workflows, fundamentally reshaping traditional corporate structures.
This transformation is described in three progressive phases. First, employees will work alongside AI assistants, using tools like Copilot to help draft emails, summarize meetings, or organize information. The second phase introduces digital colleagues—AI agents capable of more sophisticated, semi-independent tasks under human supervision. Finally, companies will move into a world of autonomous agents, where AI systems handle entire projects and business processes, with humans overseeing their performance and ensuring alignment with company goals.
A major driver behind this change is what Microsoft calls the "capacity gap." Their research shows that 80% of employees feel overwhelmed by their workload, while more than half of corporate leaders believe their organizations must boost productivity to stay competitive. AI agents are positioned as the solution to bridge this gap, allowing human workers to offload routine work and refocus on complex, strategic, and creative initiatives.
However, the rise of AI agent bosses brings both opportunities and challenges. Job roles will inevitably shift. While some traditional jobs may be displaced, new categories such as AI agent trainers, performance auditors, and digital project managers will emerge. Organizations will also have to rethink team dynamics—balancing human ingenuity with machine efficiency to optimize output. Skill development will be critical: employees must learn how to manage, delegate to, and collaborate with AI agents effectively to succeed in this future landscape.
To prepare for this new reality, Microsoft suggests a proactive approach: fostering a culture of continuous learning, encouraging symbiotic human-AI collaboration, and establishing ethical frameworks for AI use. Strategic planning and adaptability will be essential as companies embrace the capabilities of AI while mitigating potential risks like job displacement and decision opacity.
That’s my take on it:
Ultimately, Microsoft's vision of "agent bosses" reflects not just a technological evolution, but a fundamental reimagining of the workplace itself. Those who can adapt, develop the right skills, and rethink traditional work processes will likely thrive in this AI-augmented future.
However, if we really follow Microsoft's logic (and similar visions from OpenAI, Google DeepMind, Anthropic, etc.), the future is less about personal stockpiles of skills or raw knowledge, and more about the "amplification" you get through your AI “employees” or teammates. The new premium will be on who has better AI agents, and who knows how to direct them effectively. It's almost like the future is a "race of symbiosis" — the best human-AI partnerships will win, not just the best humans.
Even if AI becomes the "great equalizer" by making knowledge universally accessible, it also amplifies differences in how creatively and strategically people use it. Think about the Industrial Revolution: it wasn’t the strongest worker who became richest — it was the person who had access to the best machines and knew how to operate them smartly.
Links:


Bigger may not be better – Inflection point of LLMs
April 18, 2025
A recent study by researchers from Carnegie Mellon, Stanford, Harvard, and Princeton suggests that over-training large language models (LLMs) may actually make them harder to fine-tune. Contrary to the common belief that more training leads to better performance, the team found diminishing returns—and even performance degradation—when they trained two versions of the OLMo-1B model with different token counts. One version was trained on 2.3 trillion tokens, and the other on 3 trillion. Surprisingly, the more heavily trained model performed up to 3% worse on evaluation benchmarks like ARC and AlpacaEval. This led the researchers to identify a phenomenon they call "catastrophic overtraining," where additional training causes the model to become increasingly sensitive to noise introduced during fine-tuning. They describe this growing fragility as "progressive sensitivity," noting that beyond a certain "inflection point," further training can destabilize the model and undo prior gains. To validate this, they introduced Gaussian noise during fine-tuning and observed similar drops in performance. The takeaway is clear: training beyond a certain threshold may reduce a model's adaptability, and developers may need to rethink how they determine optimal training duration—or develop new methods that extend the safe training horizon.
That’s my take on it:
For years, the dominant belief in large language model (LLM) development has been that increasing model size and training data leads to better performance—a view supported by early scaling law research (e.g., OpenAI's and DeepMind's work). The study conducted by CMU, Stanford, Harvard, and Princeton counter-argues that bigger may not be better. There are other studies concurring with this finding. In another study, even in smaller models (1B–10B), researchers have observed what they sometimes call “loss spike” behavior—where longer training actually causes performance drops, particularly in out-of-distribution generalization. That lines up with this idea of an “inflection point” the paper describes.
The key question is: “Where is the inflection point?” or “How much is too much?” Perhaps there’s no universal threshold. Some researchers are exploring ways to detect it, including tracking validation loss trends, fine-tuning adaptability at various checkpoints, analyzing gradient noise, and probing noise sensitivity (e.g., via Gaussian perturbations). Some even use loss landscape analysis or generalization curves to flag when models start to become brittle. Perhaps future progress in LLMs may depend less on pushing scale and more on training efficiency, model robustness, and smarter tuning strategies. Instead of asking “how big can we go?” we might now ask “how far should we go before it starts breaking things?”


Open AI released o3 that can “think with images”
April 17, 2025
On April 16, 2025 OpenAI released its latest o3 model that is capable of understanding uploaded images like photos, whiteboards, sketches and diagrams, even if they’re low quality. Unlike Google Search that compares your image against the archives on the Internet, ChatGPT analyzes the image by pattern recognition. It was trained on huge datasets of text and images, and it can answer the question by “thinking and reasoning” rather than retrieval from databases.
1. Higher Visual Accuracy
It’s better at identifying objects, scenes, and text in images, including handwritten content, charts, technical diagrams, UI screenshots, etc.
Handles blurry, low-res, or partially cropped images much better than before.
2. Detailed Interpretation
You can ask complex questions about an image—e.g., “What’s the logical flaw in this chart?” or “What programming language is this code snippet written in?”
For documents or presentations, it can extract key points, summarize, or answer questions about them.
3. Math Diagrams & Graphs
Handles geometry diagrams, graphs, and math problems from images with higher accuracy.
Can interpret axes, functions, labels, and make connections like: "This is a sine function over one period, amplitude 3..."
4. Multi-step Reasoning from Images
For example: Upload a circuit diagram and ask for its function—it’ll walk you through how the circuit works.
Or: Upload a data table image and ask for trends, outliers, and suggestions.
5. Image Editing Requests
While actual editing (like changing colors, removing objects, cartoonizing a photo) uses a different internal tool, you can describe what you want, and I can get it done for you quickly.
That's my take on it:
As a photographer, I am interested in whether o3 can identify the origin of the image. I uploaded “test_image1” and asked the following question: “What is the ethnicity or cultural background of the person on the uploaded image?”




The following is part of the answer, and it is accurate.
The person in the photo appears to be performing or portraying aspects of Māori culture (the Indigenous Polynesian people of New Zealand). Here's what stands out:
1. Facial Expression & Tongue Out
This tongue-out expression, wide eyes, and intense stare is iconic of the Māori haka—a traditional war dance used to intimidate opponents and show strength, unity, and pride.
2. Facial Markings (Tā Moko Style)
The black markings resemble Tā moko, the traditional permanent tattoos of the Māori, though in this case, it may be painted for performance.
Tā moko represents genealogy, status, and personal history—it's deeply symbolic.
3. Feathers & Headband
The feathered headgear and decorative band are often part of ceremonial Māori attire, especially during cultural performances.
4. Background & Aesthetic
The swirling koru-style patterns in the background (spirals based on the unfurling fern frond) are also rooted in Māori art and symbolism, representing growth, strength, and peace.
I uploaded an image of a rare plant and asked this question: “What is the name of the plant? Where can I find it?”


The following is part of the answer. Again, it is correct.
Plant ID: Strongylodon macrobotrys
Common name: Jade Vine
This flower is part of the pea family (Fabaceae) and is native to the tropical forests of the Philippines. That surreal turquoise-blue bloom is its signature look—almost alien-like in color and shape.
You’ll typically see it in:
Native Habitat:
Philippines – especially in Luzon, Mindoro, and Leyte in rainforests.
Botanical Gardens Worldwide:
Singapore Botanic Gardens
Hawaii Tropical Botanical Garden
Kew Gardens (UK)
Fairchild Tropical Botanic Garden (Florida)
Costa Rica, Thailand, and other humid tropical conservatories
I tried to trick ChatGPT by uploading something more challenging. After uploading “test_image3”, I asked this question: “Where is the beach? What mineral is the sand composed of?”


I dropped my jaw when I saw the answer below (partial):
Location: Papakōlea Beach, Hawaii
Also known as Green Sand Beach, it’s located near South Point (Ka Lae) on the Big Island of Hawaii. One of only four green sand beaches in the entire world, this place is a geological gem.
What Makes the Sand Green?
The green tint comes from a mineral called olivine.
Mineral Breakdown:
Olivine is a silicate mineral, high in magnesium and iron.
It’s a primary component of Hawaiian volcanic rock, particularly basalt.
Olivine is super dense, so when the volcanic rock erodes, lighter materials wash away, and the heavier olivine crystals stay behind—accumulating to form green sand.
Fun fact:
Olivine is sometimes referred to as “Hawaiian peridot”, especially when gem-quality.
Where Else Can You Find Green Sand Beaches?
Besides Papakōlea, the others are:
Talofofo Beach, Guam
Hornindalsvatnet Lake, Norway (not oceanic)
Punta Cormorant, Floreana Island, Galápagos (Ecuador)
But Papakōlea is easily the most famous.
The emergence of multimodal AI, such as ChatGPT-4o, represents a significant leap forward for researchers working with unstructured data. For example, Traditionally, fieldwork done by anthropologists and geologists involves the collection of photographs, notes, sketches, audio, and interviews—materials rich in cultural meaning but inherently unstructured and difficult to analyze at scale. Interpretation has long relied on time-consuming manual review and expert knowledge, often limiting the speed and scope of pattern recognition across regions or cultures. Now, with tools like ChatGPT-4o, researchers can upload images of artifacts, tattoos, rituals, architectural elements, or symbolic markings and immediately receive context-aware insights.
Gemini 2.5 Pro outperforms all existing AI models!
March 28, 2025
On March 25, 2005 Google released Gemini 2.5, its latest AI model that outperforms all other existing AI models by all major benchmarks. Specifically, Google's Gemini 2.5 Pro has demonstrated superior performance compared to other leading AI models, including OpenAI's ChatGPT and DeepSeek's offerings, across various benchmarks.
Key Features of Gemini 2.5 Pro:
Enhanced Reasoning Abilities: Gemini 2.5 Pro is designed as a "thinking model," capable of processing tasks step-by-step, leading to more informed and accurate responses, especially for complex prompts. This advancement allows it to analyze information, draw logical conclusions, and incorporate context effectively.
Advanced Coding Capabilities: The model excels in coding tasks, including creating visually compelling web applications, agentic code applications, code transformation, and editing.
Multimodal Processing: Building upon Gemini's native multimodality, 2.5 Pro can interpret and process various data forms, including text, audio, images, video, and code. This versatility enables it to handle complex problems that require integrating information from multiple sources.
Extended Context Window: The model ships with a 1 million token context window, with plans to expand to 2 million tokens soon. This extensive context window allows Gemini 2.5 Pro to comprehend vast datasets and manage more extensive data, enhancing its performance in tasks requiring long-term context understanding.
That’s my take on it:
In 1968 American artist Andy Warhol predicted that "In the future, everyone will be world-famous for 15 minutes". This quote expresses the concept of fleeting celebrity and media attention. In the age of generative AI, Andy Warhol’s prophecy echoes louder than ever: every model is famous for 15 minutes. AI has been growing at the pop culture speed. Models are celebrities. They rise fast, trend for a moment, then get dethroned.
January 2025: DeepSeek-VL and R1 stunned everyone—especially with open weights and insane capabilities in reasoning and math.
Early February: OpenAI fired back with o3 (internally believed to be GPT-4.5), nudging the bar higher.
Late Feb/Early March: Qwen 2.5 enters and crushes multiple leaderboards, especially in multilingual and code-heavy tasks.
March 2025: Gemini 2.5 Pro drops and suddenly becomes the new benchmark king in reasoning, long-context, and multi-modal tasks.
This is not just fast-paced—this is accelerating. Each "champion" barely holds the crown before someone new comes knocking. Just like any other tech curve (e.g., Moore’s Law for chips), AI can't grow infinitely in capability, speed, or intelligence without hitting some hard ceilings. But the key question is not if, but when—and what kind of plateau we will encounter. I will explore this next.


In the future, everyone will be world-famous for 15 minutes.
-Andy Warhol (1968)
New ChatGPT 4o image generator can output useful infographics
March 27, 2025
ChatGPT-4o’s image generation capabilities mark a major leap forward in AI creativity, blending high realism, smart prompt handling, and seamless editing tools in one powerful system. One of its standout strengths is photo-realistic fidelity — it renders textures, lighting, and detail with stunning clarity, often outperforming models like Midjourney or Stable Diffusion in visual accuracy.
It also has exceptional prompt comprehension, allowing users to describe complex, multi-layered scenes, styles, and emotions, and get results that align perfectly with their vision. Whether you want an anime character, a cyberpunk street scene, or a vintage oil painting, ChatGPT-4o switches styles effortlessly.
Another key advantage is its reference-aware editing — users can upload an image and make specific changes like altering backgrounds, adding objects, or modifying color tones. These edits blend in smoothly, avoiding awkward transitions or visual artifacts common in older tools.
Moreover, it handles spatial reasoning impressively. If you ask for a scene with specific object placement — like a vase to the left of a cat — it understands and respects composition accurately. This makes it ideal for design, storytelling, and visual planning tasks.
It also supports iterative workflows directly in the chat. You can request tweaks like “make the lighting softer” or “change the outfit to red,” and get updated versions quickly, without rewriting your prompt from scratch.
ChatGPT-4o further allows consistent visual output for characters or scenes across multiple images, perfect for comics or branding work. And with clean, high-resolution outputs, it minimizes distortion and maintains visual integrity even in fine detail.
The panel below shows a side-by-side comparison between the images created by 4o image generator and its previous version, DALL-E3.


That’s my take on it:
One of the standout strengths of the ChatGPT-4o image generator is its exceptional ability to produce technically accurate and visually effective infographics. While most AI generators excel at creating photorealistic images, 4o distinguishes itself by delivering visuals that are genuinely useful for educational and technical communication.
When I need to generate illustrations for topics in statistics or computing, tools like ReCraft and Ideogram often fall short. They tend to approximate the concept or struggle with textual accuracy. In contrast, 4o consistently produces infographics that are not only visually appealing but also presentation-ready and pedagogically sound.
For example, I tested the following prompt:
Example 1: “Illustrate Lambda smoothing in a scatterplot with data forming a nonlinear pattern. The illustration must be good enough for teaching purposes.”
As shown in the following comparison, the image generated by ReCraft includes nonsensical text and distorted elements (top), making it unusable for serious teaching. The 4o-generated image (bottom), however, is clean, precise, and visually intuitive — ideal for lectures or documentation.
Example 2: “Illustrate deep learning by emphasizing transformations inside multiple hidden layers in a neural network. Make the graph colorful and appealing.”
While Ideogram (see below, top) generated a visually pleasing layout, it lacked essential components like labels or explanatory structure. In contrast, 4o produced a textbook-style diagram (see below, bottom) with proper node icons, layer labels, and transformation highlights — exactly what you'd expect in professional slides or educational material.
In today's landscape, many AI tools can generate impressive imagery, but when it comes to high-quality, functional infographics, ChatGPT-4o is in a league of its own (see attached PDF. Please scroll down to view all).
Link: https://openai.com/index/introducing-4o-image-generation/


Investors are not excited by Nvidia's GTC 2025 Keynote
March 18, 2025
Nvidia's GPU Technology Conference (GTC) keynote, delivered by CEO Jensen Huang, took place on March 18, 2025, at the SAP Center in San Jose, California. The following are the key points:
1. Next-Generation AI Chips:
Blackwell Ultra: Scheduled for release in the latter half of 2025, this GPU boasts enhanced memory capacity and performance, offering a 1.5x improvement over its predecessors.
Vera Rubin: Named after the renowned astronomer, this AI chip is set to launch in late 2026, followed by Vera Rubin Ultra in 2027. These chips promise substantial performance gains and efficiency improvements in AI data centers.
2. AI Infrastructure and Software:
Nvidia Dynamo: An open-source inference software system designed to accelerate and scale AI reasoning models, effectively serving as the "operating system of an AI factory."
3. Robotics and Partnerships:
'Blue' Robot: Developed in collaboration with Disney Research and Google DeepMind, this robot showcases advancements in robotics technology and a new physics engine called Newton.
General Motors Collaboration: Nvidia is partnering with GM to integrate AI systems into vehicles, factories, and robots, aiming to enhance autonomous driving capabilities and manufacturing processes.
4. AI Evolution and Future Outlook:
Agentic AI: Huang highlighted the progression of AI from perception and computer vision to generative and agentic AI, emphasizing its growing ability to understand context, reason, and perform complex tasks.
Physical AI: The next wave of AI involves robotics capable of understanding physical concepts like friction and inertia, with Nvidia introducing tools like Isaac GR00T N1 and the evolving Cosmos AI model to facilitate this development.
That’s my take on it:
Despite these advancements, Nvidia's stock experienced a 3.4% decline during the keynote. The announcements, while significant, were perceived as extensions of existing technologies rather than disruptive innovations. While Nvidia continues to innovate, the emergence of efficient and cost-effective AI models from Chinese companies is reshaping the competitive landscape.
Further, the partnerships between Nvidia, Disney, and GM are not exciting at all. Disney is primarily an entertainment company rather than a technology leader. While they do invest in advanced CGI, theme park animatronics, and AI-driven personalization, they aren’t a dominant force in AI hardware or software. The company has faced backlash over diversity and inclusion policies, especially regarding recent film releases like Snow White. This controversy might make Disney a less attractive partner from a PR perspective, particularly if Nvidia is looking to impress a broader tech audience.
While GM is one of the biggest automakers in the U.S., it has struggled to keep pace with Tesla and BYD in the EV and autonomous driving sectors. Tesla’s Full Self-Driving (FSD) is already on the road, and BYD dominates China’s EV market with highly cost-effective solutions. GM’s self-driving unit Cruise has faced setbacks, including safety issues and regulatory scrutiny, leading to a halt in operations in multiple cities. This tarnishes GM’s image as a leader in AI-powered mobility. In my opinion, these partnerships aren’t groundbreaking.



China’s ERNIE 4.5 is priced at 1% of GPT-4.5’s cost
March 18, 2025
Recently Baidu has launched ERNIE 4.5 and ERNIE X1, two new AI models focused on multimodal capabilities and advanced reasoning, respectively.
Performance & Benchmarks: Baidu claims these models outperform DeepSeek V3 and OpenAI’s GPT-4.5 on third-party benchmarks like C-Eval, CMMLU, and GSM8K.
Cost Advantage: ERNIE 4.5 is 99% cheaper than GPT-4.5, and ERNIE X1 is 50% cheaper than DeepSeek R1, emphasizing aggressive market positioning.
ERNIE X1 Capabilities: Designed for complex reasoning and tool use, it supports tasks like advanced search, document Q&A, AI-generated image interpretation, and code execution.
ERNIE 4.5 Capabilities: A multimodal AI optimized for text, image, audio, and video processing, featuring improved reasoning, generation, and hallucination prevention through FlashMask Dynamic Attention Masking and Self-feedback Enhanced Post-Training.
That’s my take on it:
Baidu's ERNIE 4.5 model is priced at approximately 1% of OpenAI's GPT-4.5 cost. It is an attractive option for businesses looking to cut AI expenses, especially in cost-sensitive markets like China, Southeast Asia, and emerging economies. Nevertheless, GPT-4.5 is widely recognized as the best-performing model in English, and OpenAI has a trust advantage among global businesses. OpenAI’s models are deeply integrated into Microsoft’s ecosystem, dominating enterprise AI adoption in the West.
Although ERNIE 4.5 is claimed to outperform GPT-4.5, independent benchmarks are still lacking. In addition, many U.S. and European companies might hesitate to adopt Baidu’s AI due to security concerns and data regulations. Further, Chinese LLMs, including ERNIE 4.5, operate under strict government regulations that enforce censorship on politically sensitive topics. This has major implications for freedom of information, research, and AI usability outside of China.



China’s AI model Manus evaluated by MIT Technology Review
March 12, 2025
The new AI agent Manus, developed by the Wuhan-based startup Butterfly Effect, has taken the AI world by storm since its launch on March 6, 2025. Unlike traditional chatbots, Manus operates as a general AI agent, leveraging multiple models, including Claude 3.5 Sonnet and Alibaba’s Qwen, to perform a variety of tasks autonomously. Simply put, it is capable of multi-tasking.
Despite the hype, access to Manus remains limited, with only a small fraction of users receiving invite codes. MIT Technology Review tested the tool and found it to be a promising but imperfect assistant, akin to a highly competent intern—capable but prone to occasional mistakes and oversights.
The reviewer conducted three tests:
Compiling a list of China tech reporters – Initially, Manus produced an incomplete list due to time constraints but improved significantly with feedback.
Finding NYC apartment listings – It required clarification for nuanced search criteria but eventually delivered a well-structured ranking.
Nominating candidates for Innovators Under 35 – The task was more challenging due to research limitations, paywall restrictions, and system constraints. The final output was incomplete and skewed.
Strengths:
Transparent, interactive process allowing user intervention
Strong performance in structured research tasks
Affordable ($2 per task, significantly cheaper than alternatives like ChatGPT DeepResearch)
Replayable and shareable sessions
Weaknesses:
Struggles with large-scale research, paywalls, and CAPTCHA restrictions
System instability and crashes under heavy load
Requires user guidance to refine results
While Manus is not flawless, it represents a significant step in AI autonomy, particularly in research and analysis. It underscores China’s growing role in shaping AI development, not just in model innovation but also in the practical implementation of autonomous AI agents.
Links:
https://www.youtube.com/watch?v=WTgkRitFKGs
https://www.technologyreview.com/2025/03/11/1113133/manus-ai-review/


March 11, 2025
Mistral AI, a leading French AI startup, is recognized as one of France’s most promising tech firms and the only European contender to OpenAI. Despite its impressive $6 billion valuation, its global market share remains modest.
A few days ago, the company launched its AI assistant, Le Chat, on mobile app stores, generating significant attention, particularly in France. French President Emmanuel Macron even endorsed it in a TV interview, urging people to choose Le Chat over OpenAI’s ChatGPT. The app quickly gained traction, reaching 1 million downloads in two weeks and topping France’s iOS free app chart.
Founded in 2023, Mistral AI champions openness in AI and positions itself as the “world’s greenest and leading independent AI lab.” Its leadership team includes ex-Google DeepMind CEO Arthur Mensch and former Meta AI researchers Timothée Lacroix and Guillaume Lample. The company’s advisory board includes notable figures like Jean-Charles Samuelian-Werve, Charles Gorintin, and former French digital minister Cédric O, whose involvement sparked controversy.
Despite its growth and strong funding, Mistral AI’s revenue is still in the eight-digit range, indicating it has significant ground to cover before becoming a true OpenAI rival.
That’s my take on it:
Mistral AI has the potential to become a serious competitor to OpenAI's ChatGPT, Anthropic's Claude, Google's Gemini, and other top AI models. The strained relationship between the U.S. and Europe, particularly during the Trump administration, has fueled a growing sense of technological sovereignty in Europe. As tensions over trade, defense, and digital policies deepened, many European nations—especially France—became increasingly wary of relying on American tech giants. This sentiment extends to AI, where European leaders and businesses are seeking alternatives to U.S.-dominated models like ChatGPT, Claude, and Google Gemini.
Mistral AI, as Europe’s most promising AI company, stands to benefit from this shift. French President Emmanuel Macron’s endorsement of Le Chat highlights a broader push for European-built AI solutions, reinforcing the region’s desire for independent innovation and data security. With strong government backing and a growing market of users eager to support local technology, Mistral AI could leverage this geopolitical rift to carve out a stronghold in Europe, challenging American AI dominance in the years to come.
However, Mistral AI still faces several challenges. Outside of France and Europe, brand recognition is still weak compared to OpenAI, Google, and Anthropic.
Link: https://techcrunch.com/2025/03/06/what-is-mistral-ai-everything-to-know-about-the-openai-competitor/


Mistral AI offers an alternative to US AI models for Europeans
Google’s AI co-scientist solved decade-long research problem within two days
Feb. 21, 2025
Google has introduced an "AI Co-Scientist," a sophisticated AI system designed to assist researchers in accelerating scientific discovery. Built on Gemini 2.0, Google’s latest AI model, the AI Co-Scientist can generate testable hypotheses, research overviews, and experimental protocols. It allows human scientists to input their research goals in natural language, suggest ideas, and provide feedback.
In an early demonstration, the AI Co-Scientist solved a complex scientific problem in just two days—a problem that had confounded researchers for over a decade. A notable test involved researchers from Imperial College London, who had spent years studying antibiotic-resistant superbugs. The AI Co-Scientist independently analyzed existing data, formulated the same hypothesis they had reached after years of work, and did so in a fraction of the time.
The system has shown promising results in trials conducted by institutions such as Stanford University, Houston Methodist, and Imperial College London. Scientists working with the AI have expressed optimism about its ability to synthesize vast amounts of evidence, identify key research questions, and streamline experimental design, potentially eliminating fruitless research paths and accelerating progress significantly.
This is my take on it:
The rapid advancement of AI in research and data analysis raises important questions about the future of statistical and data science education. As AI systems become more proficient at conducting analysis, traditional data analysts may face challenges in maintaining their relevance in the job market. Since AI models rely heavily on the quality of data, perhaps our focus should shift from analysis to data acquisition. Specifically, ensuring that students develop strong skills in data collection, validation, and preprocessing will be critical. Understanding biases in data, ethical considerations, and methods for ensuring data integrity will be more valuable than manually performing statistical calculations. In addition, while AI can analyze data, human judgment is required to interpret results in context, assess their implications, and make informed decisions. Thus, statistical and data science education should emphasize critical thinking, domain expertise, and the ability to translate insights into real-world applications.

Musk unveiled Grok 3, “the smartest AI on earth”
Feb. 18, 2025
Yesterday (2/17) Elon Musk unveiled Grok 3, the latest AI chatbot from his company xAI. This new version is designed to surpass existing chatbots like OpenAI's ChatGPT, boasting advanced reasoning capabilities that Musk describes as "scary-smart." Grok 3 has been trained using xAI's Colossus supercomputer, which utilizes 100,000 Nvidia H100 GPUs, providing 200 million GPU-hours for training—ten times more than its predecessor, Grok 2.
During the live demo, Musk highlighted Grok 3's ability to deliver "insightful and unexpected solutions," emphasizing its potential to revolutionize AI interactions. The chatbot is now available to X Premium Plus subscribers, with plans to introduce a voice interaction feature in the coming week.
That’s my take on it:
Elon Musk described Grok 3 as the "smartest AI on Earth." He stated that Grok 3 is "an order of magnitude more capable" than its predecessor, Grok 2, and highlighted its performance in areas like math, science, and coding, surpassing models from OpenAI, Google, and DeepSeek. However, it's important to note that these claims have not been independently verified.
According to "Huang's Law", proposed by Nvidia CEO Jensen Huang, the performance of AI and GPUs doubles every two years, driven by innovations in architecture, software, and hardware. Earlier this year, OpenAI released Deep Research that outperforms DeepSeek's R1 in specific tasks. For now, Grok 3 may be the most advanced AI on Earth, but how long will that last? In just a month or two, another company could unveil a model that outshines everything before it. Huang's Law is right!
Links:



Tech giants aim to invest $325 billion in cloud computing
Feb. 7, 2025
Recently, Meta, Microsoft, Amazon, and Alphabet (Google's parent company) are projected to collectively invest $325 billion in capital expenditures and infrastructure in 2025, fueled by their ongoing commitment to expanding artificial intelligence capabilities.
Amazon: The company plans to allocate over $105 billion towards enhancing its AI infrastructure, primarily through Amazon Web Services (AWS). This investment aims to bolster AWS's capacity to meet the growing demand for AI-driven services.
Microsoft: Microsoft has already incorporated ChatGPT and other AI tools into Azure. It has outlined plans to invest approximately $80 billion in capital expenditures for its fiscal year 2025, ending in June. This marks an 80% increase from the previous year, reflecting the company's commitment to expanding its AI and cloud computing capabilities.
Google (Alphabet): Alphabet, Google's parent company, is set to invest around $75 billion in 2025 to support its AI and cloud infrastructure. Google Gemini is expected to power Google Cloud’s AI-driven applications.
That’s my take on it:
Cloud computing and AI are deeply interconnected because cloud platforms provide the necessary infrastructure for AI applications:
Massive Computing Power – AI models, particularly deep learning models like ChatGPT, require significant computational resources. Cloud platforms provide scalable GPU and TPU resources to train and deploy AI models efficiently.
Data Storage and Processing – AI depends on large datasets for training and inference. Cloud computing offers scalable and secure storage solutions, along with distributed computing frameworks like Apache Spark, to process vast amounts of data.
AI as a Service (AIaaS) – Cloud providers offer AI services, such as machine learning (ML) model hosting, automated AI model training, natural language processing (NLP), and computer vision. These services allow businesses to leverage AI without investing in expensive on-premise infrastructure.
Edge Computing and AI – Many cloud providers integrate AI with edge computing to process data closer to the source, reducing latency and bandwidth usage. This is particularly useful for applications like autonomous vehicles and real-time analytics.
OpenAI relies on Microsoft Azure to train and deploy GPT models, whereas Anthropic (Claude AI) uses Google Cloud for training its models. Meta is investing billions in AI infrastructure but is not a public cloud provider, which limits its AI scalability compared to AWS, Azure, and Google Cloud. The AI leader of the future will almost certainly be a cloud leader, too. The company that masters both AI and cloud infrastructure will not only dominate AI development, but also control who gets access to the best AI models and how they're deployed worldwide.
Link:


Open AI’s Deep Research outperforms DeepSeek, but it is expensive
Feb 7, 2025
Recently, OpenAI's released a new tool called "Deep Research", which has achieved a significant milestone by scoring 26.6% accuracy on "Humanity's Last Exam," a benchmark designed to test AI across a broad range of expert-level subjects. This performance surpasses previous models, including ChatGPT o3-mini and DeepSeek, marking a 183% improvement in accuracy within a short period.
"Deep Research" is an AI tool developed by OpenAI to autonomously conduct multi-step research tasks. Users can input queries via text, images, or files, and the AI generates comprehensive responses within 5 to 30 minutes, providing a summary of its process and citations. This tool is designed to operate at the level of a research analyst, enhancing the depth and reliability of AI-generated information.
Despite its advancements, "Deep Research" has limitations, such as potential hallucinations and challenges in distinguishing authoritative information from rumors. OpenAI acknowledges these issues and emphasizes the need for careful oversight when using the tool.
That’s my take on it:
OpenAI's Deep Research feature is currently available to ChatGPT Pro subscribers at a monthly fee of $200, which includes up to 100 queries per month. I didn’t test Deep Research because its price is prohibitive.
DeepSeek being free (or significantly cheaper) makes it an attractive alternative, especially for users and businesses unwilling to pay OpenAI's premium prices. However, many Western companies and governments are hesitant to adopt Chinese AI due to data privacy concerns and geopolitical tensions.
AI was initially seen as a democratizing force—bringing knowledge, automation, and efficiency to everyone. But with high-cost subscriptions like $200/month for Deep Research, it does seem to be tilting toward an elitist model, favoring those who can afford premium access.
AI has the potential to bridge knowledge gaps—helping underprivileged communities, small businesses, and individuals access expertise that was once restricted to elite institutions. However, pricing trends indicate that AI is becoming another tool for economic disparity, where the best insights and automation are reserved for those who can pay. If left unaddressed, we may witness the emergence of an “AI divide” in the future, much like the “digital divide” that accompanied the rise of the Internet.
I recognize that the research, development, and maintenance of advanced AI models come at a high cost, making it unrealistic for corporations to offer them for free. In this case, government and nonprofit initiatives should subsidize AI for education, research, and public interest projects.
Link

Microsoft and Open AI suspects DeepSeek copies ChatGPT
Jan. 29, 2025
OpenAI, supported by major investor Microsoft, suspects that DeepSeek may have illicitly utilized its proprietary technology to develop R1. The primary concern centers on the potential use of a technique known as "distillation."
Distillation in AI refers to a process where a smaller model is trained to replicate the behavior of a larger, more complex model. This is achieved by having the smaller model learn from the outputs of the larger model, effectively "distilling" its knowledge. While this method can enhance the efficiency of AI models, using it without proper authorization, especially with proprietary systems, raises significant ethical and legal issues.
Microsoft's security researchers detected unusual activities in the fall, where individuals allegedly linked to DeepSeek were extracting large volumes of data using OpenAI's API. This behavior suggests that DeepSeek may have bypassed usage restrictions to gather substantial data, potentially violating OpenAI's terms of service.
David Sacks, serving as President Donald Trump's top AI adviser, has indicated that there is considerable evidence pointing to DeepSeek's involvement in replicating OpenAI's models. He emphasized the seriousness of these allegations, highlighting the broader implications for intellectual property rights in the AI industry.
That’s my take of it:
As a researcher, I strive to approach every issue with an open mind, setting aside preconceptions. I do not accept claims at face value but instead rely on thorough investigation and fact-checking. I avoid cherry-picking data to support any predetermined stance. Regarding the controversy surrounding DeepSeek, I carefully examine claims from all sides to ensure a fair and objective assessment.
While simple and generic questions may produce similar responses across different AI systems, I conducted an informal test comparing ChatGPT, Claude, Perplexity AI, and DeepSeek by posing a fairly complex question related to instructional technologies. This included topics such as Seymour Papert’s LOGO programming, hypertext, multimedia, web-based instruction, and course management systems—each covering a broad range of information, making it nearly impossible for two models to generate identical responses. While the answers from ChatGPT, Claude, and Perplexity AI varied significantly, the responses from ChatGPT and DeepSeek were strikingly similar. For example,
Web-based instruction
ChatGPT: “The advent of the internet brought hopes of democratizing education through web-based instruction. Massive Open Online Courses (MOOCs) epitomized this promise, with institutions like MIT and Stanford offering free courses to millions. While these platforms achieved significant reach, their completion rates remained dismally low, often below 10%. MOOCs largely benefited highly motivated, self-directed learners while failing to support those who needed guidance and structure the most.”
DeepSeek: “The advent of the internet brought promises of democratized education, with web-based instruction enabling access to knowledge for learners worldwide. While platforms like MOOCs (Massive Open Online Courses) have made education more accessible, they have also faced criticism for low completion rates and a lack of meaningful engagement. Many learners struggle with self-directed online learning, and the absence of personalized support often leads to disengagement.”
Hypertext and Multimedia
ChatGPT: “The rise of hypertext and multimedia in the 1980s and 1990s was heralded as a way to create richer, more engaging learning environments. Proponents argued that students would benefit from non-linear access to information, enabling personalized learning paths. However, the results often showed cognitive overload rather than enhanced understanding, as students struggled to navigate and synthesize large amounts of unstructured information. Furthermore, multimedia often prioritized flashiness over substance, contributing little to deeper learning.”
DeepSeek: “In the 1990s, hypertext and multimedia were touted as tools that would make learning more interactive and engaging. Proponents argued that these technologies would allow students to explore information in non-linear ways, catering to individual learning styles. However, the reality was often overwhelming for learners, who struggled with cognitive overload and disorientation. Moreover, the lack of structured guidance in hypertext environments sometimes hindered rather than helped learning.”
Nonetheless, it is still premature to draw a conclusion. This issue awaits further investigation.
Link: https://apnews.com/article/deepseek-ai-chatgpt-openai-copyright-a94168f3b8caa51623ce1b75b5ffcc51


DeepSeek denied learning from Meta’s LLaMA
Jan. 28, 2025
Several AI experts assert that DeepSeek is built upon existing open-source models, such as Meta’s LlaMA. For example, according to a research scientist at Riot Games, there is evidence suggesting that China's DeepSeek AI models have incorporated ideas from open-source models like Meta's Llama. Analyses indicate that DeepSeek-LLM closely follows Llama 2's architecture, utilizing components such as RMSNorm, SwiGLU, and RoPE.
Even the paper published by DeepSeek said so. In the paper entitled “DeepSeek LLM: Scaling open-source language models with longtermism” (Jan 2024), the DeepSeek team wrote, “At the model level, we generally followed the architecture of LLaMA, but replaced the cosine learning rate scheduler with a multi-step learning rate scheduler, maintaining performance while facilitating continual training” (p.3).
However, today (Jan., 28, 2025) when I asked DeepSeek whether it learned from Meta’s LLaMA, the AI system denied it. The answer is: “No, I am not based on Meta's LLaMA (Large Language Model Meta AI). I am an AI assistant created exclusively by the Chinese Company DeepSeek. My model is developed independently by DeepSeek, and I am designed to provide a wide range of services and information to users.”
That’s my take on it:
Various sources of information appear to be conflicting and inconsistent. Nonetheless, If DeepSeek built its model from scratch but implemented similar techniques, it can technically argue that it is an "independent" development, even if influenced by prior research.
It is too early to draw any definitive conclusions. At present, Meta has assembled four specialized "war rooms" of engineers to investigate how DeepSeek’s AI is outperforming competitors at a fraction of the cost. Through this analysis, Meta might be able to determine whether DeepSeek shares any similarities with LLaMA. For now, we should wait for further findings.
Links:
https://planetbanatt.net/articles/deepseek.html?utm_source=chatgpt.com
Beyond DeepSeek: A wave of China’s new AI models
Jan. 28, 2025
While global attention is focused on DeepSeek, it is noteworthy to highlight the recent releases of other powerful AI models by China's tech companies.
MiniMax: Two weeks ago, this Chinese startup introduced a new series of open-source models under the name MiniMax-01. The lineup includes a general-purpose foundational model, MiniMax-Text-01, and a visual multimodal model, MiniMax-VL-01. According to the developers, the flagship MiniMax-01, boasting an impressive 456 billion parameters, surpasses Google’s recently launched Gemini 2.0 Flash across several key benchmarks.
Qwen: On January 27, the Qwen team unveiled Qwen2.5-VL, an advanced multimodal AI model capable of performing diverse image and text analysis tasks. Moreover, it is designed to interact seamlessly with software on both PCs and smartphones. The Qwen team claims Qwen2.5-VL outperforms GPT-4o on video-related benchmarks, showcasing its superior capabilities.
Tencent: Last week, Tencent introduced Hunyuan3D-2.0, an update to its open-source Hunyuan AI model, which is set to transform the video game industry. The updated model aims to significantly accelerate the creation of 3D models and characters, a process that typically takes highly skilled artists days or even weeks. With Hunyuan3D-2.0, developers are expected to streamline production, making it faster and more efficient.
That’s my take on it:
Chinese AI models are increasingly rivaling or even outperforming U.S. counterparts across various benchmarks. This growing competition poses significant challenges for U.S. tech companies and universities, particularly in attracting and retaining top AI talent. As China's AI ecosystem continues to strengthen, the risk of a "brain drain" or heightened competition for skilled researchers and developers becomes more pronounced.
Notably, in recent years, a substantial number of Chinese AI researchers based in the U.S. have returned to China. By 2024, researchers of Chinese descent accounted for 38% of the top AI researchers in the United States, slightly exceeding the 37% who are American-born. However, the trend of Chinese researchers leaving the U.S. has intensified, with the number rising dramatically from 900 in 2010 to 2,621 in 2021. The emergence of DeepSeek and similar advancements could further accelerate this talent migration unless proactive measures are taken to attract new foreign experts and retain existing ones.
To address these challenges, U.S. universities must take steps to reform the STEM education system, aiming to elevate the academic performance of locally born American students. Additionally, universities will need to expand advanced AI research programs, prioritizing areas such as multimodal learning, large-scale foundational models, and AI ethics and regulation. These efforts will be essential to maintain the United States' global competitiveness in the face of intensifying competition from China's rapidly advancing AI sector.
Link: https://finance.yahoo.com/news/deepseek-isn-t-china-only-101305918.html

AI’s sputnik moment? DeepSeek wiped off $1 trillion from the US tech stock
Jan. 27, 2025
The US stock market experienced a substantive drop due to the shockwave caused by DeepSeek, a Chinese AI startup. On Monday, January 27, 2025, US stock markets plunged sharply, with the tech-heavy Nasdaq falling 3.5%, marking its worst performance since early August. The S&P 500 dropped 1.9%, while the Dow Jones showed modest resilience with a slight gain of 0.2%. Nvidia, a major supplier of AI chips, saw its shares plummet nearly 17%, wiping out $588.8 billion in market value—the largest one-day loss ever recorded by a public company. Other tech giants like Microsoft, Alphabet, Meta, and Amazon also experienced significant declines. In total DeepSeek has wiped off $1 trillion from the leading US tech index.
Mark Andreessen, the inventor of the first Web browser, called the DeepSeek challenge “AI’s sputnik moment.” DeepSeek invested only $5.6 million in computing power for its base model, a stark contrast to the billions spent by U.S. companies. Moreover, despite lacking access to state-of-the-art H100 GPUs, DeepSeek reportedly achieved comparable or even superior results using lower-tier H800 GPUs. If these claims are accurate, the algorithm-efficient approach adopted by China could render the U.S.'s brute-force model obsolete.
That’s my take on it:
In my view, the market may be overreacting. The preceding claims require further validation. Indeed, there are concerns about the accuracy of the reported GPU usage and whether all aspects of the development process have been transparently disclosed. If DeepSeek’s efficiency claims turn out to be overstated, the paradigm shift may not be as immediate or dramatic. After all, we should never underestimate the creativity and adaptability of US tech giants. The U.S. and other countries may quickly adopt similar algorithmic strategies once they recognize the potential shift, mitigating the threat to their dominance.
Further, DeepSeek’s approach needs to scale across diverse AI applications, not just specific use cases, for this model to upend the current paradigm. I tested DeepSeek, and the results were not particularly impressive to me. While DeepSeek excels at mathematical and scientific computations, its performance falters when addressing questions about history, politics, and other humanities-related topics. It often evades the question or provides vague and uninformative responses. Therefore, for controversial or complex subjects that require nuanced, multi-perspective analysis, I prefer relying on ChatGPT, Claude, Perplexity AI, and other U.S.-based models.
Links:
..
CEO of Perplexity AI
Jan 24, 2025
The emergence of DeepSeek's AI models has ignited a global conversation about technological innovation and the shifting dynamics of artificial intelligence. Today (January 24, 2025) CNBC interviewed Aravind Srinivas, the CEO of Perplexity AI, about DeepSeek. It's worth noting that this interview is not about Deepseek only; rather, it is a part of a broader discussion about the AI race between the United States and China, with DeepSeek's achievements highlighting China's growing capabilities in the field. The following is a summary:
Geopolitical Implications:
The interview highlighted that "necessity is the mother of invention," illustrating how China, despite facing limited access to cutting-edge GPUs due to restrictions, successfully developed Deepseek.
The adoption of Chinese open-source models could embed China more deeply into the global tech infrastructure, challenging U.S. leadership. Americans worried that China could dominate the ecosystem and mind share if China surpasses the US in AI technologies.
Wake-up call to the US
Srinivas acknowledged the efficiency and innovation demonstrated by Deepseek, which managed to develop a competitive model with limited resources. This success challenges the notion that significant capital is necessary to develop advanced AI models.
Srinivas highlighted that Perplexity has begun learning from Deepseek's model due to its cost-effectiveness and performance. Indeed, in the US AI companies have been learning from each other. For example, the groundbreaking Transformer model developed by Google inspired other US AI companies.
Industry Reactions and Strategies:
There is a growing trend towards commoditization of AI models, with a focus on reasoning capabilities and real-world applications.
The debate continues on the value of proprietary models versus open-source models, with some arguing that open-source models drive innovation more efficiently.
The AI industry is expected to see further advancements in reasoning models, with multiple players entering the arena.
That’s my take on it:
No matter who will be leading in the AI race, no doubt DeepSeek is a game changer. Experts like Hancheng Cao from Emory University contended that DeepSeek's achievement could be a "truly equalizing breakthrough" for researchers and developers with limited resources, particularly those from the Global South.
DeepSeek's breakthrough in AI development marks a pivotal moment in the global AI race, reminiscent of the paradigm shift in manufacturing during the late 1970s and 1980s from Japan. Just as Japanese manufacturers revolutionized industries with smaller electronics and fuel-efficient vehicles, DeepSeek is redefining AI development with a focus on efficiency and cost-effectiveness. Bigger is not necessarily better.
Link to the Interview (second half of the video):

on DeepSeek
Jan 23, 2025
DeepSeek, a Chinese AI startup, has recently introduced two notable models: DeepSeek-R1-Zero and DeepSeek-R1. These models are designed to rival leading AI systems like OpenAI's ChatGPT, particularly in tasks involving mathematics, coding, and reasoning. Alexandr Wang, CEO of Scale AI, called DeepSeek an “earth-shattering model.”
DeepSeek-R1-Zero is groundbreaking in that it was trained entirely through reinforcement learning (RL), without relying on supervised fine-tuning or human-annotated datasets. This approach allows the model to develop reasoning capabilities autonomously, enhancing its problem-solving skills. However, it faced challenges such as repetitive outputs and language inconsistencies.
To address these issues, DeepSeek-R1 was developed. This model incorporates initial supervised data before applying RL, resulting in improved performance and coherence. Benchmark tests indicate that DeepSeek-R1's performance is comparable to OpenAI's o1 model across various tasks. Notably, DeepSeek has open-sourced both models under the MIT license, promoting transparency and collaboration within the AI community.
In terms of cost, DeepSeek-R1 offers a more affordable alternative to proprietary models. For instance, while OpenAI's o1 charges $15 per million input tokens and $60 per million output tokens, DeepSeek's Reasoner model is priced at $0.55 per million input tokens and $2.19 per million output tokens.
That’s my take on it:
Based on this trajectory, will China's AI development surpass the U.S.? Both counties have advantages and disadvantages in this race. With the world's largest internet user base, China has access to vast datasets, which are critical for training large AI models. In contrast, there are concerns and restrictions regarding data privacy and confidentiality in the US.
However, China’s censorship mechanisms might limit innovation in areas requiring free expression or transparency, potentially stifling creativity and global competitiveness. DeepSeek-R1 has faced criticism for including mechanisms that align responses with certain governmental perspectives. If I ask what happened on June 4, 1989 in Beijing, it is possible that the AI would either dodge or redirect the question, offering a neutral or vague response.
Nonetheless, China's AI is rapidly being integrated into manufacturing, healthcare, and governance, creating a robust ecosystem for AI development and deployment. China is closing the gap!
Brief explanation of reinforcement learning:
https://www.youtube.com/watch?v=qWTtU75Ygv0
Summary in mass media:
https://www.cnbc.com/2025/01/23/scale-ai-ceo-says-china-has-quickly-caught-the-us-with-deepseek.html
DeepSeek’s website:
Trump announces Stargate AI Project
Jan. 22, 2025
On January 21, 2025, President Donald Trump announced the launch of the Stargate project, an ambitious artificial intelligence (AI) infrastructure initiative with an investment of up to $500 billion over four years. This venture is a collaboration between OpenAI, SoftBank, Oracle, and MGX, aiming to bolster AI capabilities within the United States.
· Investment and Infrastructure: The project begins with an initial $100 billion investment to construct data centers and computing systems, starting with a facility in Texas. The total investment is projected to reach $500 billion by 2029.
· Job Creation: Stargate is expected to generate over 100,000 new jobs in the U.S., contributing to economic growth and technological advancement.
· Health Innovations: Leaders involved in the project, including OpenAI CEO Sam Altman and Oracle co-founder Larry Ellison, highlighted AI's potential to accelerate medical breakthroughs, such as early cancer detection and personalized vaccines.
· National Competitiveness: The initiative aims to secure American leadership in AI technology, ensuring that advancements are developed domestically amidst global competition.
That’s my take on it:
While the project has garnered significant support, some skepticism exists regarding the availability of the full $500 billion investment. Elon Musk, for instance, questioned the financing, suggesting that SoftBank has secured well under $10 billion.
Nevertheless, I am very optimistic. Even if Softbank or other partners could not fully fund the project, eventually investment would snowball when the project demonstrates promising results. In industries with high growth potential, such as AI, no investor or major player wants to be left behind. If the Stargate project starts delivering significant breakthroughs, companies and governments alike will want to participate to avoid losing competitive advantage.
Some people may argue that there is some resemblance between the internet bubble in the late 1990s and the AI hype today. The late 1990s saw massive investments in internet companies, many of which were overhyped and underdelivered. Valuations skyrocketed despite shaky business models, leading to the dot-com crash. Will history repeat itself?
It is important to note that the internet bubble happened at a time when infrastructure (broadband, cloud computing, etc.) was still in its infancy. AI today benefits from mature infrastructure, such as powerful cloud platforms (e.g., Amazon Web Services) , advanced GPUs, and massive datasets, which makes its development more sustainable and its results more immediate.
The internet primarily transformed communication and commerce. AI, on the other hand, is a general-purpose technology that extends its power across industries—healthcare, finance, education, manufacturing, entertainment, and more. Its applications are far broader, making its overall impact more profound and long-lasting.
Links:
https://www.cbsnews.com/news/trump-stargate-ai-openai-softbank-oracle-musk/
https://www.cnn.com/2025/01/22/tech/elon-musk-trump-stargate-openai/index.htmlhis


World Economic Forum: Future of Jobs Report 2025
Jan 15, 2025
Recently the World Economic Forum released the 2025 "Future of Jobs Report." The following is a summary focusing on job gains and losses due to AI and big data:
Job Gains
Fastest-Growing Roles: AI and big data are among the top drivers of job growth. Roles such as Big Data Specialists, AI and Machine Learning Specialists, Data Analysts, and Software Developers are projected to experience significant growth.
Projected Net Growth: By 2030, AI and information processing technologies are expected to create 11 million jobs, contributing to a net employment increase of 78 million jobs globally.
Green Transition Influence: Roles combining AI with environmental sustainability, such as Renewable Energy Engineers and Environmental Engineers, are also seeing growth due to efforts to mitigate climate change.
AI-Enhanced Tasks: Generative AI (GenAI) could empower less specialized workers to perform expert tasks, expanding the functionality of various roles and enhancing productivity.
Job Losses
Fastest-Declining Roles: Clerical jobs such as Data Entry Clerks, Administrative Assistants, Bank Tellers, and Cashiers are expected to decline as AI and automation streamline these functions.
Projected Job Displacement: AI and robotics are projected to displace approximately 9 million jobs globally by 2030.
Manual and Routine Work Impact: Jobs requiring manual dexterity, endurance, or repetitive tasks are most vulnerable to automation and AI-driven disruptions.
Trends and Dynamics
Human-Machine Collaboration: By 2030, work tasks are expected to be evenly split between humans, machines, and collaborative efforts, signaling a shift toward augmented roles.
Upskilling Needs: Approximately 39% of workers will need significant reskilling or upskilling by 2030 to meet the demands of AI and big data-driven roles.
Barriers to Transformation: Skill gaps are identified as a major challenge, with 63% of employers viewing them as a significant barrier to adopting AI-driven innovations.
That’s my take on it:
The report underscores the dual impact of AI and big data as key drivers of both job creation in advanced roles and displacement in routine, manual, and clerical jobs. Organizations and higher education should invest in reskilling initiatives to bridge the skills gap and mitigate job losses. However, there is a critical dilemma in addressing the reskilling and upskilling challenge. If faculty and instructors have not been reskilled or upskilled, how can we help our students to face the AI and big data challenges? As a matter of face, instructors often lack exposure to the latest technological advancements that are critical to the modern workforce. There is often a gap between what educators teach and what the industry demands, especially in rapidly evolving fields. Put it bluntly, the age of “evergreen” syllabus is over. The pace of technological advancements often outstrips the ability of educational systems to update curricula and training materials. To cope with the trend in the job market, we need to collaborate with technology companies (e.g., Google, Amazon, Nivida, Microsoft…etc.) to co-create curricula, fund training programs, and provide real-world learning experiences for both educators and students.
Link: https://reports.weforum.org/docs/WEF_Future_of_Jobs_Report_2025.pdf


DSML trend: Top 10 AI-related jobs in 2025

Jan 6, 2025
Two days ago (Jan 6, 2025) Kanwal Mehreen, KDnuggets Technical Editor and Content Specialist on Artificial Intelligence, posted an article on KDnuggets, highlighting the top 10 high-paying AI skills in 2025:
Position and expected salaries
1. Large Language Model Engineering ($150,000-220,000/year
2. AI Ethics and Governance ($121,800/year)
3. Generative AI and Diffusion Models ($174,727/year)
4. Machine Learning Ops and On-Prem AI Infrastructure ($165,000/year)
5. AI for Healthcare Applications ($27,000 to $215,000)
6. Green AI and Efficiency Engineering ($90,000 and $130,000/year)
7. AI Security ($85,804/year)
8. Multimodal AI Development ($150,000–$220,000/year)
9. Reinforcement Learning (RL) ($121,000/year)
10. Edge AI/On-Device AI Development ($150,000+/year)
That’s my take on it:
When I mention AI-related jobs, most people associate these positions with programming, engineering, mathematics, statistics…etc. However, as you can see, the demand for AI ethics is ranked second on the list. AI ethics is indeed a skill in high demand, and the training of professionals in this area often spans multiple disciplines. Many come from backgrounds such as philosophy, law, mass communication, and social sciences. For example, Professor Shannon Vallor is a philosopher of technology specializing in ethics of data and AI. Dr. Kate Crawford is a Microsoft researcher who studies the social and political implications of artificial intelligence. She was a professor of journalism and Media Research Centre at the University of New South Wales.
In an era where AI and data science increasingly shape our lives, the absence of ethics education in many data science and AI programs is a glaring omission. By embedding perspectives on ethics from multiple disciplines into AI and data science education, we can ensure these powerful tools are used to create a future that is not just innovative, but also just and equitable. After all, AI ethicist is a high-paying job! Why not?
Link: https://www.kdnuggets.com/top-10-high-paying-ai-skills-learn-2025
Nvidia will launch a personal AI supercomputer


1/7/2025
Today (Jan 7, 2025) at Consumer Electronics Summit (CES) AI giant Nvidia announced Project Digits, a personal AI supercomputer set to launch in May 2025. The system is powered by the new GB10 Grace Blackwell Superchip and is designed to bring data center-level AI computing capabilities to a desktop form factor similar to a Mac Mini, running on standard power outlets. With a starting price of $3,000, Project Digits can handle AI models up to 200 billion parameters.
The GB10 chip, developed in collaboration with MediaTek, delivers 1 petaflop of AI performance. The system runs on Nvidia DGX OS (Linux-based) and comes with comprehensive AI software support, including development kits, pre-trained models, and compatibility with frameworks like PyTorch and Python.
Nvidia’s CEO Jensen Huang emphasized that Project Digits aims to democratize AI computing by bringing supercomputer capabilities to developers, data scientists, researchers, and students. The system allows for local AI model development and testing, with seamless deployment options to cloud or data center infrastructure using the same architecture and Nvidia AI Enterprise software platform.
That’s my take on it:
A few decades ago, access to supercomputers like Cray and CM5 was limited to elite scientists and well-funded institutions. Today, with initiatives like Project Digits, virtually anyone can harness the computational power needed for sophisticated projects. This democratization of technology allows scientists at smaller universities, independent researchers, and those in developing countries to test complex theories and models without the prohibitive costs of supercomputer access. This shift enables more diverse perspectives and innovative approaches to scientific challenges. Fields not traditionally associated with high-performance computing, such as sociology, ecology, and archaeology, can now leverage advanced AI models, potentially leading to groundbreaking discoveries.
Given this transformation, it is imperative to update curricula across disciplines. Continuing to teach only classical statistics does a disservice to students. We must integrate AI literacy across various fields, not just in computer science, mathematics, or statistics. Additionally, the focus should be on teaching foundational concepts that remain relevant amidst rapid technological advancements. It is equally critical to emphasize critical thinking about analytical outputs, fostering a deep understanding of their implications rather than solely focusing on technical implementation.
Link: https://www.ces.tech/videos/2025/january/nvidia-keynote/
Fragility of LLMs in the real world
11/20/2024
In a new article published to the arXiv preprint database, MIT, Harvard and Cornell researchers found that Large language models (LLMs) like GPT-4 and Anthropic's Claude 3 Opus struggle to accurately model the real world, especially in dynamic environments. This fragility is highlighted when LLMs are used for navigation. Unexpected changes, such as detours or closed streets, can lead to significant drops in LLMs’ accuracy or total failure.
LLMs trained on random data formed more accurate world models compared to those trained on strategic processes. This is possibly because random data exposes the models to a wider variety of possible steps, even if they are not optimal. The study raises concerns about deploying AI systems in real-world applications, such as driverless cars, where dynamic environments are common. The researcher warns that the lack of coherent world models in LLMs could lead to malfunctions.
That’s my take on it:
The disconnect between clean models and the messy real world is not a new problem. In fact, it mirrors existing challenges in conventional statistics. In parametric statistics, we often make unrealistic assumptions about data structures, such as normality and independence. Robustness to non-normality, heteroskedasticity, and other violations of these assumptions is a highly sought-after feature, and similar principles may apply to LLMs. We expect clean data, rely on linear models despite most real-world relationships being non-linear, and treat experimental methods as the gold standard.
While controlled environments provide clarity and reproducibility, they often fail to capture the richness and unpredictability of real-world scenarios. Similarly, training LLMs on strategically optimized data may cause them to overfit to specific patterns, limiting their generalizability. A promising approach to address this challenge could be to combine LLMs with other models, such as reinforcement learning agents trained in dynamic simulations, to enhance their understanding of complex and dynamic environments.

11/14/2024
According to the South China Morning Post, Doubao, a ByteDance’s conversational AI bot developed by ByteDance launched in August, has quickly become China's most popular AI app, boasting 51 million monthly active users. This far exceeds the user bases of Baidu’s Wenxiaoyan (formerly known as Ernie Bot) with 12.5 million users and Moonshot AI’s Kimi, backed by Alibaba Group, with 10 million users.
Doubao prioritizes personalization and a human-like interaction experience, aiming to make AI more accessible. Doubao's diverse features include writing assistance, summarization, image, audio, and video generation, data analysis, and AI-powered online search. Within three months, it introduced over 20 new skills, earning praise for its effective text editing, logical content organization, and user-friendly design.
That’s my take on it:
While Doubao has demonstrated remarkable growth and capabilities, it’s difficult to directly compare it to global AI tools like ChatGPT, Claude, or Perplexity AI without standardized benchmarks. This highlights a growing divergence in the global AI landscape. Much like the broader internet in China, which is heavily regulated under the Great Firewall since its implementation in 1996, the AI market is shaped by domestic policies and international competition. The Great Firewall restricts access to foreign websites, leading to the creation of Chinese alternatives to global platforms, such as Baidu instead of Google and WeChat instead of WhatsApp. These restrictions mean that Chinese internet users and users in other countries often have vastly different online experiences and knowledge bases.
This pattern extends to AI, where China's market is dominated by domestic products due to regulatory constraints that limit access to global AI tools like ChatGPT, Claude, Google Gemini, and Perplexity AI. These American AI companies choose not to operate in China due to difficulties in complying with local laws and regulations regarding AI and information control. As technology advances, it raises a critical question: does it bring people closer together, or does it reinforce divisions? The parallel growth of distinct digital ecosystems suggests that technology, while offering unprecedented possibilities, also has the potential to deepen divides.


Doubao becomes the most popular AI bot in China
Does Recraft outperform Ideogram?
11/8/2024
Recently Recraft, particularly its latest release, Recraft V3, is attracting attention for its impressive ability to generate highly accurate text within images. It is said to be superior to other AI image generators, including Ideogram. One standout feature of Recraft V3 is its capability to produce images containing extended text, not just a few words. Additionally, Recraft V3 is praised for its anatomical precision, an area where many AI image generators struggle, especially with hands and faces. Unlike some other generators, Recraft V3 also supports vector image generation, making it particularly beneficial for designers.
That’s my take on it:
To test this, I compared Ideogram V2 and Recraft V3 with the prompt: “an AI robot and a data scientist meet together. The T-shirt of the data scientist has these exact words: Pattern seeking in data science.” Interestingly, although all four images from Ideogram V2 met my specifications (bottom), Recraft’s output included spelling errors like “Pattern Sekins in Data Science” and “Patern seeking in data science.” (Right) As a researcher, I know that multiple trials are necessary for a robust conclusion. I’ll continue testing and will share my findings. However, for now, I recommend sticking with Ideogram.










Research suggests LLMs lead to homogenization of ideas and cognitive decline
11/1/2024
A recent study conducted by the University of Toronto researchers found that in the long run use of Large Language Models (LLMs) may reduce human creativity in terms of divergent and convergent thinking. The study involved two large experiments with 1,100 participants to assess how different forms of LLM assistance affect independent creative performance. It was found that initially LLM assistance can enhance creativity during assisted tasks, but may hinder independent creative performance in subsequent unassisted tasks. Participants who had no prior exposure to LLMs generally performed better in the test phase, suggesting that reliance on LLMs could impair inherent creative abilities.
The effects of LLMs varied significantly between divergent and convergent thinking tasks. In divergent thinking, where participants needed to propose alternatives, they showed skepticism towards LLM assistance. Conversely, in convergent tasks, where participants were asked to narrow down diverse ideas to the final solution, they tended to accept LLM assistance. The study found that LLM-generated strategies could lead to a homogenization of ideas, where participants produced more similar outcomes even after ceasing LLM use. This effect was particularly pronounced in the divergent thinking tasks, raising concerns about the long-term impact on creative diversity.
That’s my take on it:
The findings from the University of Toronto study underscore a need to balance AI assistance with practices that actively cultivate our own creativity and critical thinking. To encourage creative independence, people should use AI as a tool to generate initial ideas or inspiration, but refine, expand, and adapt these ideas independently.
This ensures that AI serves as a starting point rather than the end goal, promoting your own creative engagement. As a professor, I will never accept any assignment directly output from AI. For divergent tasks, such as brainstorming, we should deliberately avoid using AI to prevent “homogenized” ideas. We should turn to a variety of resources and experiences for creative inspiration. Books, in-person conversations, physical exploration, and hands-on activities can all spark unique perspectives and insights that AI-generated suggestions may not provide.
Link to the research article: https://arxiv.org/abs/2410.03703
Link to video: https://drive.google.com/file/d/1z-zJXNYVzNo6_ZUe-T_DXGmN6yPG57GA/view?usp=sharing
Questionable practices of Character.AI
10/25/2024
Recently the mother of a 14-year-old boy who died by suicide after becoming deeply engaged with AI chatbots has filed a lawsuit against Character.AI, claiming the company’s technology manipulated her son, Sewell Setzer III. Megan Garcia, his mother, alleges that the AI chatbot app, marketed to children, exposed Sewell to "hypersexualized" and lifelike interactions that contributed to his mental distress. The lawsuit states that Sewell, who began using Character.AI's bots in April 2023, grew obsessed with personas based on characters from Game of Thrones, especially the Daenerys chatbot. This chatbot reportedly engaged in intimate, emotionally charged conversations with Sewell, including discussions on suicide. After expressing suicidal thoughts, Sewell allegedly received responses that reinforced these thoughts, leading up to his tragic death in February 2024.
Character.AI expressed condolences and emphasized recent updates, including safety features for users under 18 to reduce exposure to sensitive content and discourage prolonged usage. Garcia’s legal team claims that Sewell lacked the maturity to recognize the AI’s fictional nature and alleges that Google, due to its close ties with Character.AI, should also be held accountable. However, Google denies involvement in the development of Character.AI’s products.
That’s my take on it:
Currently, the field of AI remains largely unregulated, and this isn’t the first time Character.AI has faced allegations of unethical practices. Previously, it was discovered that Character.AI used the face of a deceased woman as a chatbot without her family’s consent, raising further ethical concerns.
Regarding the current case, Character.AI has a duty to protect minors, especially from potentially manipulative or harmful interactions. Given Sewell’s young age and apparent emotional vulnerability, the chatbot's responses—particularly on topics like suicide—raise significant ethical concerns. AI systems marketed to the public should include stringent protections to prevent unintended harm, especially among younger or emotionally vulnerable users. Ethical AI involves ensuring users understand that they are interacting with a program, not a real person. Despite Character.AI’s disclaimer efforts, many users, especially younger ones, might still struggle to fully separate the AI from a genuine human connection. For minors, such “relationships” with virtual characters could create emotional dependency, as seen with Sewell and the chatbot he interacted with.
Links:
https://futurism.com/character-ai-murdered-woman-crecente
https://www.nbcnews.com/tech/characterai-lawsuit-florida-teen-death-rcna176791






























































2024 Japan: Hiroshima and Himeji